2021-01-13 22:00
¡La nube está de moda! Desde hace años, pero más desde la pandemia de COVID-19, todo el mundo quiere aprovechar sus ventajas y beneficios (pago por uso, escalabilidad, integraciones, mayor velocidad de desarrollo, etc).
Sin embargo, la forma en la que se usa la nube, puede variar mucho en función de las necesidades de cada cliente o usuario. Mientras unos apuestan por desarrollar todas sus aplicaciones futuras en ella, otros simplemente mueven aplicaciones ya desarrolladas. Por lo que me he encontrado a nivel personal, diría que la forma de uso suele estar entre esos dos extremos: con aplicaciones nuevas y aplicaciones legacy.
Considero que existen tres formas diferentes de llevar aplicaciones a la nube:
-
La primera es llamada Lift and Shift. Este modelo replica en la nube elegida, la infraestructura y la arquitectura de la aplicación legacy. Por ejemplo: si ésta se componía de tres servidores de aplicaciones, en tres máquinas virtuales y un balanceador, los creamos en nuestro proveedor y lo configuramos simulando a nuestro viejo CPD. Aunque es la forma más rápida y económica de utilizar la nube, también es la que menos permite aprovechar sus beneficios.
-
La segunda yo la llamo Mutated infrastructure. En ella se realizan pequeñas adaptaciones a la infraestructura para que ésta pueda integrarse con algunos servicios de la nube. De esta forma, nuestra aplicación puede ganar algunas ventajas como escalabilidad y resilencia. Es un proceso más lento que el primer modelo, pero aporta beneficios inmediatos a un coste relativamente bajo.
-
La tercera es Rearchitecture. Es la forma más laboriosa y requiere modificar partes del código de la aplicación para aprovechar toda la potencia de la nube. Requiere un proceso de reaquitectura de la aplicación completo, que puede ser muy costoso y por ello, no siempre se realiza.
Para los dos primeros casos, solemos partir de modelos basados en máquinas físicas o virtuales y en el tercero, se suele optar o bien por soluciones de tipo PaaS o por fragmentar dichas aplicaciones en contenedores.
Packer es una grandísima herramienta (de la que ya he hablado) para coger dichas máquinas virtuales o físicas y replicarlas en la nube, algo tremendamente útil en una migración a la nube.
En este post, vamos a simular una migración hacia la nube, realizando algunas mejoras y explicando los motivos de la misma. Manos a la obra :) .
2020-11-01 20:00
A finales del año 2018 hice una pequeña retroespectiva sobre qué futuro quería para este blog. En ese momento mis metas se centraron en continuar escribiendo contenido, adaptar más el tema a mis gustos y lograr una mayor interacción con la comunidad (con colaboraciones, habilitando un sistema de comentarios, etc).
Tras realizar varias pruebas, me di cuenta de algunas de las limitaciones que tenía Nikola respecto a otros generadores de código estático: su comunidad es reducida y su desarrollo, sin llegar a detenerse, avanza muy lentamente. A mi pesar, descubrí que algunas de las funcionalidades que deseaba, iban a necesitar mucho trabajo y decidí priorizar la creación de nuevo contenido frente a la funcionalidad.
Esto cambió hace unos meses: recibí un correo de parte de un mibro de Platform9 donde me daba feedback respecto al blog y me hacía una serie de recomendaciones para lograr tener más visibilidad. Tomé nota al respecto y me puse manos a la obra: era el momento de dejar atrás Nikola por otro generador.
A nivel personal, no había utilizado ningún otro generador de código estático, pero tras unas cuantas pruebas rápidas decidí utilizar Hugo, puesto que teóricamente cubría todas las necesidades que había detectado.
2020-10-14 08:00
Considero a Hashicorp una de las empresas que más están innovando actualmente: su compromiso con los entornos multi-nube (privada, pública y mixta) y su suite de herramientas están facilitando mucho la transición entre proveedores y reduciendo la curva de aprendizaje de la nube.
2020-08-31 10:00
Cada día utilizamos más servicios online: servicios accesibles a través de Internet que podemos operar y utilizar por nuestra cuenta, pero que forman parte de un conjunto mucho más grande.
Vamos a imaginarnos que Netflix o Spotify tuvieran que desplegar una aplicación para cada uno de sus usuarios. Sería mucho más difícil mantener y operar el servicio y haría casi imposible su escalabilidad y disponibilidad general. Tanto para ofrecer un mejor servicio como para ahorrar costes, cada plataforma digital suele funcionar como si fuese una única aplicación, dentro de la cual se nos asigna una pequeña parte de la misma y que podemos utilizar de manera independiente. Este sistema de compartición de recursos es una de las bases de la computación en la nube y recibe el nombre de Multi-tenancy.
Es un sistema que inicialmente añade complejidad al conjunto, pero que bien diseñado, puede aportar mucha robustez y ahorro a futuro.
Pese a que hay compañías que deciden desplegar una aplicación por clúster de Kubernetes para evitar complicaciones, esto puede ser muy ineficiente. Además, Kubernetes ofrece multitud de mecanismos para garantizar una buena gestión del multi-tenancy.
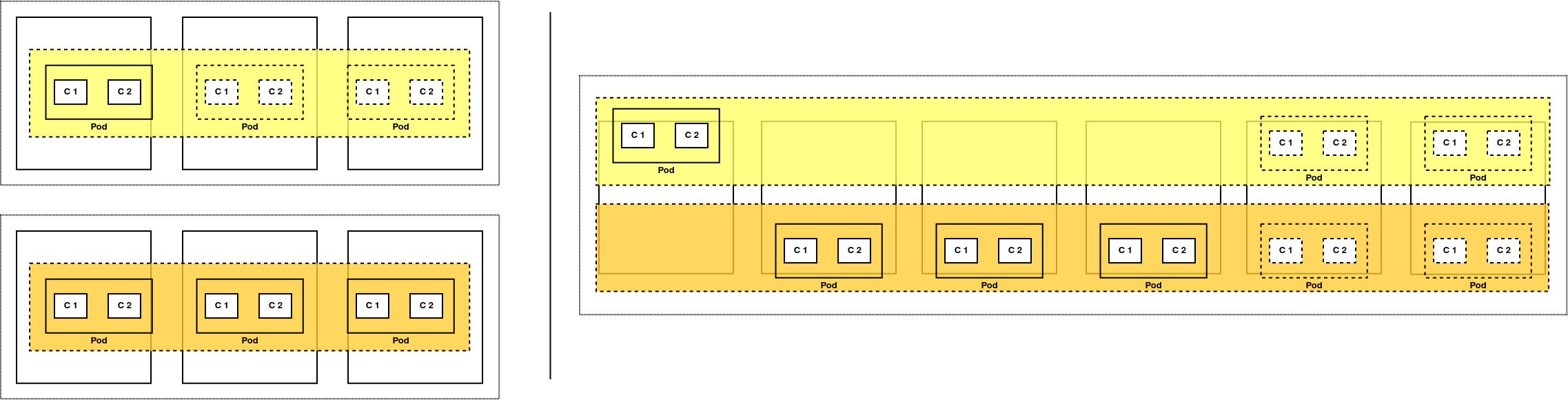
Por ejemplo: a la izquierda tenemos dos clústers separados con una aplicación cada uno. El superior tiene demasiados recursos para la carga que tiene, mientras que el inferior ya está al máximo y no puede aprovechar los recursos sobrantes del primero. A la derecha, ambas aplicaciones comparten el clúster y cualquiera de ellas puede aprovechar los recursos sobrantes si fuese necesario.
En anteriores post hemos visto como aislar pods y aplicaciones dentro del mismo clúster tanto a nivel de seguridad y permisos como a nivel de red. Hoy vamos a aprender cómo asignar y aislar los recursos computacionales que utilizan nuestras aplicaciones sobre Kubernetes.
2020-08-07 20:00
La digitalización de la sociedad es un proceso que ha aumentado tanto el consumo de servicios web como los ataques informáticos contra sus usuarios y los propios servicios. A mediados de 2020, alguien accedió a las herramientas de gestión internas de Twitter y pudo publicar mensajes en cuentas verificadas de gente famosa para que le enviaran Bitcoins. El ataque era un robo, pero las consecuencias del ataque podían haber sido mucho más graves.
¿Os imaginais que se hubiera publicado amenazas de muerte desde la cuenta de un presidente de un Estado hacia otro presidente? ¿O si desde la cuenta de un gran empresario se diese información errónea para manipular la Bolsa de un país?
Evidentemente, nosotros como usuarios no tenemos tanto poder, pero si alguien accediese a nuestras cuentas de AWS o GCP, podríamos tener problemas o gastos indeseados.
2020-07-15 10:00
A lo largo de varios meses, hemos visto qué es Kubernetes y cómo realizar algunas acciones en nuestros clústers: desplegar aplicaciones, hacerlas accesibles desde fuera del clúster o almacenar datos, entre otros (I, II y III)
En el último post de la serie, comenzamos a hablar de multitenancy y la capacidad de ejecutar diferentes aplicaciones, separadas de forma lógica en el mismo clúster.
Para lograr esta separación, lo primero era entender cómo funcionan los sistemas de autorización y autenticación de Kubernetes, pero aunque tengamos una buena política de permisos definida, nada impide por defecto que una aplicación mande peticiones a otra desplegada en el mismo clúster.
Esto puede parecer lógico y no ser un gran problema, pero si puede llegar a serlo: ¿Y si alguien despliega una aplicación maliciosa o alguien explota una vulnerabilidad en alguno de nuestros contenedores? ¿Y si nuestras aplicaciones tienen distintos grados de confidencialidad?.
Para que la separación lógica entre aplicaciones sea completa, no necesitamos crear un clúster por aplicación sino aplicar Network Policies.
2020-06-10 10:00
El uso de funciones en la nube no es una moda pasajera y ha llegado para quedarse. Pese a sus limitaciones, tienen algunos puntos fuertes que las hacen una baza imprescindible a la hora de potenciar la automatización de la administración de la nube.
Ya escribí un post sobre funciones en el que explicaba cómo utilizo las funciones para vigilar el estado de los backups de mis servicios a coste 0 y sin tener que preocuparme por su gestión.
Hoy vamos a darle una vuelta extra a dicho post, terraformando dichas funciones e integrándolas en un sistema de CICD completo.
2020-05-31 10:00
Al comenzar este blog hace más de dos años, siempre tuve claro que me centraría en la nube en sí misma, así como en las metodologías y tecnologías que permiten su existencia.
La tecnología no ha parado de evolucionar en estos años: han aparecido constántemente nuevas ideas, que buscan solucionar los problemas ya existentes, pero que a su vez generan otros nuevos problemas.
El propio Kubernetes es un ejemplo perfecto: permite aprovechar mejor los recursos que disponemos y aporta una mayor resilencia y disponibilidad. Sin embargo, también genera mucha abstracción en sus elementos y hace que podamos perder capacidad operativa y visibilidad. Sin las herramientas adecuadas es mucho más fácil corregir un error en una máquina virtual que en una aplicación desplegada en varios microservicios.
Personalmente, siempre me he centrado en los principales proveedores de nube pública. Son mi foco a nivel profesional y permiten reducir la complejidad que supone usar estas nuevas tecnologías, acercándolas a los usuarios, clientes y administradores menos techies.
Pero… ¿Y si no queremos utilizar nube pública? ¿No existe alguna alternativa potente para gestionar nuestra nube pública?
2020-04-28 10:00
Hoy vamos a continuar con la serie de posts relacionados con Kubernetes. Tras el contenido de los post I, II y III, ya sabemos un poco qué es Kubernetes, cómo almacenar datos en nuestro clúster y cómo acceder a nuestros servicios.
En cada post hemos visto como K8s está diseñado para ser escalable y para ello, cualquier servicio necesita ingentes cantidades de hardware (host, switchs, routers, cableado, discos duros, etc).
Si utilizamos una nube pública, nuestro proveedor se encargará de aprovisionar los recursos necesarios, pero seguirá de nuestra mano el tener que distribuir las cargas de trabajo a lo largo del clúster para lograr nuestros objetivos de servicio (alta disponibilidad, distribución en zonas o regiones, etc).
La gran necesidad de recursos nos lleva a hacernos una pregunta: ¿Cómo podemos aprovechar al máximo los recursos de nuestro clúster? La forma más completa se basa en desplegar diferentes aplicaciones que compartan hardware, pero puede no ser lo más seguro.
Así que, ¿cómo podemos aprovechar al máximo y de la manera más segura posible, los recursos de nuestro clúster?
2020-03-23 22:00
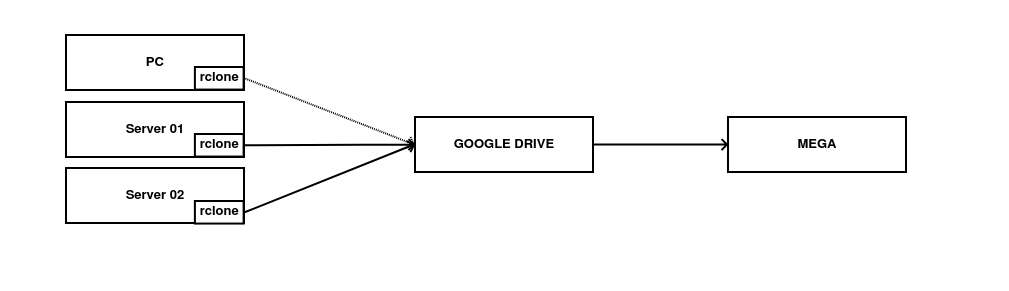
Una de mis mayores preocupaciones informáticas es la pérdida de datos. Nunca he tenido una pérdida catastrófica pero sí algunas menores y siempre he buscado que mi sistema de respaldo fuese consistente y fiable. Como ya dije en un post anterior, hace tiempo que me monté un sistema de backups personalizado y que me permite recuperar mis datos con una pérdida máxima de datos de 24 horas.
Los backups se generan cifrados con GPG en el origen a través de Backupninja y se suben a almacenamientos en la nube gracias a rclone. Se realiza un sistema
de archivado en MEGA.
Aunque generalmente funcione bien, sí he tenido algunas incidencias desde que lo implementé, todas ellas relacionadas con la imposibilidad de subir el backup al destino remoto (tokens expirados, discos remotos llenos, etc).