Kubernetes (V): networking y políticas de red
2020-07-15 10:00A lo largo de varios meses, hemos visto qué es Kubernetes y cómo realizar algunas acciones en nuestros clústers: desplegar aplicaciones, hacerlas accesibles desde fuera del clúster o almacenar datos, entre otros (I, II y III)
En el último post de la serie, comenzamos a hablar de multitenancy y la capacidad de ejecutar diferentes aplicaciones, separadas de forma lógica en el mismo clúster.
Para lograr esta separación, lo primero era entender cómo funcionan los sistemas de autorización y autenticación de Kubernetes, pero aunque tengamos una buena política de permisos definida, nada impide por defecto que una aplicación mande peticiones a otra desplegada en el mismo clúster.
Esto puede parecer lógico y no ser un gran problema, pero si puede llegar a serlo: ¿Y si alguien despliega una aplicación maliciosa o alguien explota una vulnerabilidad en alguno de nuestros contenedores? ¿Y si nuestras aplicaciones tienen distintos grados de confidencialidad?.
Para que la separación lógica entre aplicaciones sea completa, no necesitamos crear un clúster por aplicación sino aplicar Network Policies.
Networking en Kubernetes
En Kubernetes cada pod recibe una IP interna y es accesible a través de ella. Esto hace que los pods puedan ser tratados como VMs independientes, con todas las ventajas e inconvenientes que esto conlleva (asignación de puertos, balanceo de carga, etc).
Kubernetes impone dos requisitos fundamentales en su modelo de red:
-
Los pods de un nodo tienen que poder conectarse con los pods del resto de nodos sin necesidad de NAT.
-
Los servicios de un nodo (como Kubelet) tienen que poder comunicarse con todos los pods de dicho nodo.
Basándonos en dicho modelo, llamado Container Network Interface. tenemos diferentes implementaciones o plugins. Cada plugin se encarga de configurar la red de cada contenedor cuando es creado o destruido en el clúster y de garantizar que sus requisitos de red son correctos.
Los principales plugins CNI son los siguientes:
-
Flannel: desarrollado por CoreOS, es posiblemente sea el ejemplo más maduro de todos ellos y utiliza el etcd de nuestro clúster para almacenar la información de red. Flannel crea una red de capa tres que se extiende a lo largo de todos los nodos del clúster. Cada nodo recibe una fracción de dicha red para asignar IPs y los contenedores pueden comunicarse entre ellos sin problemas. Flannel no soporta por defecto Network Policies.
-
Calico: Calico es otra de las opciones más utilizadas a la hora de implantar un modelo de CNI en Kubernetes. Desarrollado por Project Calico, funciona a través de una red de capa tres que enrruta los paquetes entre cada uno de los hosts del clúster de Kubernetes mediante el protocolo BGP. Calico es muy conocido por sus potentes Network Policies, pero hablaremos de ello más adelante.
-
Canal: Es una mezcla de ambos: combina el modelo de networking simple de Flannel con la potencia de las políticas de red de Calico. Su origen está basado en un proyecto que ha sido descontinuado pero que se sigue utilizando puesto que los objetivos del proyecto se consiguieron al combinar Flannel y Calico, sin necesidad de tener un CNI nuevo al uso.
-
Cilium: Es un proyecto de código abierto para proporcionar sistemas de enrrutado en capas 3/4 y sistemas de balanceo en capas 4/7 que se integra nativamente con sistemas de orquestación de contenedores como Mesos o Kubernetes. Podemos leer más de él en la página del proyecto.
No vamos a profundizar más, pero si queremos saber más sobre cómo funciona el networking en Kubernetes, recomiendo la lectura del ebook gratuito publicado por Rancher, Kubernetes Networking Deep Dive. Es muy interesante.
Network Policies
Por defecto no hay restricciones de tráfico dentro de nuestro clúster y cualquier pod puede llamar o ser llamado por cualquier otro pod, sin importar su origen. Este formato de red plana puede llegar a ser un problema de seguridad.
Para realizar algún tipo de segmentación en ella, tenemos las llamadas Network Policies. Son objetos que permiten a Kubernetes limitar que sólo algunos pods, namespaces o rangos de IP puedan comunicarse con otros pods, namespaces o rangos de IP.
El soporte por defecto de Kubernetes a las Network Policies depende del driver CNI que estemos utilizando. En nuestra primera prueba vamos a seguir utilizando MicroK8s: la idea es crear dos namespaces y probar la comunicación entre ambos.
# Creamos el namespace origen
kubectl create namespace origen
# Creamos el namespace destino
kubectl create namespace destino
Tras crear los namespaces, cogemos el siguiente código y lo utilizamos para crear el fichero deny.yaml. De esta forma vamos a crear una política que deniegue por defecto todo el tráfico de tipo Ingress en el clúster.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
Para aplicarla tan sólo tenemos que ejecutar kubectl apply -f deny.yaml.
Las funcionalidades de las Network Policies que Kubernetes soporta por defecto son un poco limitadas. Podemos bloquear el tráfico de salida (Egress) o entrada (Ingress), pero sólo se aplica a recursos que estén correctamente etiquetados (pods, services, namespaces, etc) y a rangos de IPs o puertos.
Para hacer configuraciones más complejas o tener una mayor granularidad, generar logs para determinados puertos o reglas, filtrar por Host interfaces o por cuentas de servicio, necesitamos utilizar algún otro plugin CNI que nos extienda las políticas por defecto.
Microk8s soporta de caja un plugin CNI llamado Cilium, pero nosotros vamos a instalar Calico debido a que es prácticamente un estándar en Kubernetes.
Extendiendo las Network Policies: Calico
El desarrollo de Calico se basa en un modelo de seguridad de red llamado Zero Trust Networks. Dicho modelo se basa en que la red siempre puede ser hostil:
-
Un atacante puede comprometer algunas partes seguras de nuestra red y utilizarlas contra nosotros.
-
Un error o una mala configuración puede enviar tráfico de las zonas seguras de la red a las zonas no seguras.
-
Cualquier endpoint de una red segura puede ser comprometido y utilizado para atacar el resto de la red.
Si tenemos interés, podemos leer más sobre su modelo en la documentación oficial de Calico.
Con los tres puntos anteriores como base, las Network Policies de Calico permiten una mayor variedad de configuraciones:
-
Las políticas de red se pueden aplicar a cualquier tipo de Endpoint: pods, máquinas virutales, hosts, etc. También podemos definir políticas globales, en lugar de por namespace.
-
Las políticas pueden tener un orden, que les asigna distintas prioridades de aplicación.
-
Las políticas soportan diferentes acciones (allow, deny, log o pass) y con un control mucho más granular: se pueden aplicar a puertos, protocolos, atributos HTTP o ICMP, IPv4 o IPv6, IPs o CIDR y selectores de Kubernetes (como etiquetas en namespaces o en cuentas de servicio).
Instalando Calico en Kubernetes
Para poder utilizar Calico, primero debemos tener un clúster de Kubernetes que lo soporte. Microk8s actualmente lo soporta de caja, pero vamos a utilizar Minikube debido a su capacidad de personalización.
Para crear un clúster con Minikube nos descargamos el binario de Github, le damos permisos de ejecución y ejecutamos el siguiente comando:
# Descargamos Minikube de Github
curl https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 --output minikube
# Le damos permisos de ejecución
chmod +x minikube
# Creamos un clúster de dos nodos con una configuración concreta
minikube start --cpus=2 --disk-size='10g' --memory='2g' \
--network-plugin=cni \
--cni=calico
Necesitaremos tener disponibles al menos 2 cores y 4 GB de RAM en la máquina o host en el que ejecutemos dicho comando.
Minikube tiene soporte nativo para Calico y podemos instalarlo directamente con el siguiente comando, aunque nos dará una versión un poco más desactualizada.
Si queremos probar las últimas funcionalidades, podemos instalar Calico a mano, pero yo me he encontrado con algunos problemas que comentaré al final del post. En cualquier debemos cumplir los prerrequisitos prerrequisitos del producto.
Sin embargo, si deseamos probar las últimas funcionalidades yo personalmente recomiendo instalar Cálico a mano. El producto consta de una serie de controladores de CRDs (Custom Resource Definitions) que tenemos que aplicar. Su instalación es bastante sencilla: tan sólo debemos comprobar que cumplimos los y utilizar el operador de Tigera.
Definiendo nuestra red
Una vez que Calico ya está desplegado en nuestro clúster, vamos a definir algunas políticas para organizar la red interna de Kubernetes.
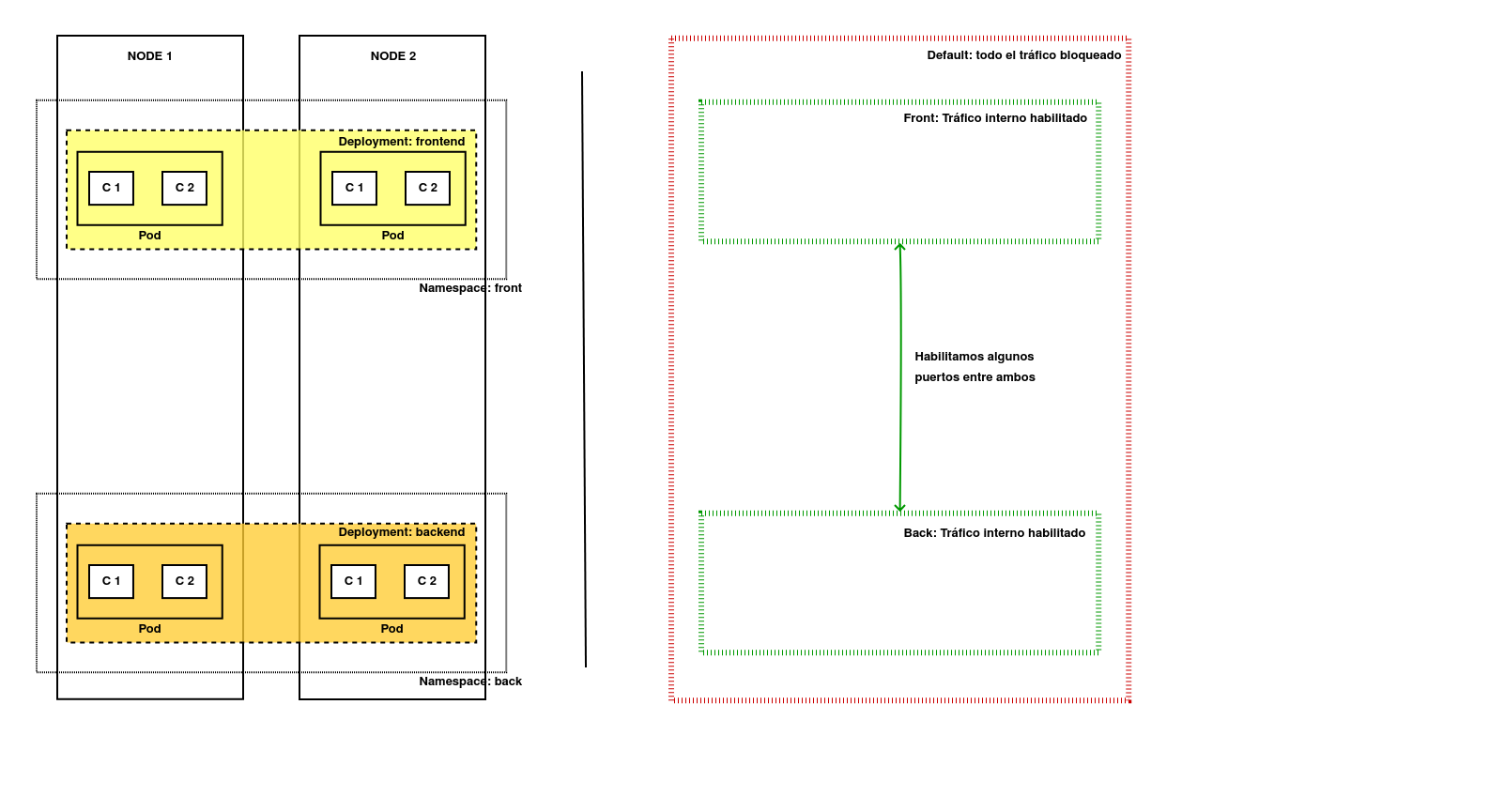
La anterior imagen muestra lo que queremos conseguir. A la izquierda tenemos la distribución lógica de nuestras aplicaciones y a la derecha tenemos la estructura de red que queremos conseguir:
-
Una política por defecto que denegará cualquier comunicación siempre que no esté permitida por otra política de mayor prioridad.
-
Se creará otra política para permitir el tráfico interno necesario dentro de los dos namespaces en los que se divide nuestra aplicación (front y back).
-
Se habilitará la comunicación entre algunos puertos de los namespaces, indicando el origen y el destino para que la aplicación sea funcional.
Vamos a preparar el entorno con la siguiente lista de comandos. Crearán los namespaces, desplegarán dos Nginx escuchando en distintos puertos para simular nuestros front y back y asociarán varios servicios a cada uno de ellos.
# Creamos el namespace front
kubectl create namespace front
# Desplegamos el Deployment y el SVC de Nginx-front
kubectl apply -f nginx-front.yaml -n front
kubectl apply -f nginx-front-svc.yaml -n front
# Creamos el namespace back
kubectl create namespace back
# Desplegamos el Deployment y el SVC de Nginx-back
kubectl apply -f nginx-back.yaml -n back
kubectl apply -f nginx-back-svc.yaml -n back
Si nos metemos en un pod y tiramos un curl contra el Service de nginx-back, veremos que éste responde:
# Entramos en uno de los pods de Nginx Front
kubectl exec -ti nginx-front-79d94b554f-7vxq7 -n front -- sh
# Hacemos un curl a la IP y puerto del service de Back
curl 10.104.101.8:3306
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
</head>
<body>
<h1>Welcome to nginx!</h1>
Global Network Policies
Con el entorno ya preparado, ahora vamos a crear una política común a todo el clúster: Calico permite generar un tipo de objeto que cumple con nuestas necesidades, las llamadas GlobalNetworkPolicy. Este sería el YAML que tendríamos que aplicar:
apiVersion: projectcalico.org/v3
kind: GlobalNetworkPolicy
metadata:
name: default-deny-traffic
spec:
order: 1000
selector: all()
types:
- Ingress
- Egress
Esta política bloqueará todo el tráfico a nivel de clúster, pero aunque podamos aplicarla con kubectl desde la versión de Calico 3.19, se recomienda gestionarla a través de la propia CLI de Calico.
Por todo ello, vamos a descargar calicoctl, darle permisos y conectarlo a nuestro clúster de Minikube:
# Descargamos la CLI con curl
curl -L https://github.com/projectcalico/calico/releases/download/v3.25.1/calicoctl-linux-amd64 -o calicoctl
# Lo hacemos ejecutable
chmod +x calicoctl
# Definimos el datastore del que va a leer los datos calico
export DATASTORE_TYPE=kubernetes
# Definimos el modo de acceso al datastore
export KUBECONFIG=~/.kube/config
Tras haber configurado la herramienta, ya podemos desplegar la política global correctamente:
# Aplicamos la política de seguridad global
calicoctl apply -f deny.yaml
Successfully applied 1 'GlobalNetworkPolicy' resource(s)
Y si entramos en un pod y repetimos la prueba anterior, nuestro pod no tendrá conectividad con el servicio de back.
Permitiendo el tráfico entre pods y namespaces
Esta primera regla, ha bloqueado todo el tráfico entre todos los endpoints del clúster impidiendo la comunicación entre todos los pods a lo largo del clúster. Esto impacta en algunas de las funcionalidades de nuestro clúster y que tenemos que arreglar:
-
Todos los pods de nuestro Control Plane tienen que poder comunicarse entre si (están ubicados en el namespace kube-system).
-
No podemos acceder a ningún tipo de servicio, ni resolver ningún nombre de dominio tanto interno como externo.
Para solucionar estos problemas, vamos a crear tres reglas globales más:
-
La primera habilita todo el tráfico dentro del namespace kube-system.
-
La segunda habilita todo el tráfico de todos los pods etiquetados como k8s-app: kube-dns (para habilitar la resolución interna).
-
La tercera habilita la resolución de DNS externa, permitiendo que las peticiones al puerto 53 puedan salir a Internet.
Creamos el fichero extra-rules.yaml con el siguiente contenido y lo aplicamos con calicoctl:
apiVersion: projectcalico.org/v3
kind: GlobalNetworkPolicy
metadata:
name: allowing-kubesystem
spec:
order: 800
ingress:
- action: Allow
destination:
namespaceSelector: name == 'kube-system'
source: {}
egress:
- action: Allow
destination: {}
source:
namespaceSelector: name == 'kube-system'
types:
- Ingress
- Egress
---
apiVersion: projectcalico.org/v3
kind: GlobalNetworkPolicy
metadata:
name: allowing-dns
spec:
order: 800
types:
- Ingress
- Egress
selector: k8s-app == 'kube-dns'
egress:
- action: Allow
ingress:
- action: Allow
---
apiVersion: projectcalico.org/v3
kind: GlobalNetworkPolicy
metadata:
name: allowing-dns-egress
spec:
order: 800
types:
- Egress
egress:
- action: Allow
protocol: UDP
destination:
nets:
- 0.0.0.0/0
ports:
- 53
Podemos ver que las reglas funcionan, desplegando un pod y probando a resolver algún nombre DNS:
# Desplegamos una herramienta para poder ejecutar resoluciones DNS
kubectl apply -f https://k8s.io/examples/admin/dns/dnsutils.yaml
# Probamos a realizar una resolución interna
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: kubernetes.default.svc.cluster.local
Address: 10.96.0.1
# Probamos ahora a realizar una resolución externa
kubectl exec -i -t dnsutils -- nslookup www.marca.es
Server: 10.96.0.10
Address: 10.96.0.10#53
Non-authoritative answer:
Name: www.marca.es
Address: 193.110.128.199
Tras arreglar el acceso al Control Plane de Kubernetes, el siguiente paso es habilitar el tráfico en los namespaces de front y back. Creamos dos NetworkPolicy, una para cada namespace habilitando el tráfico
apiVersion: projectcalico.org/v3
kind: NetworkPolicy
metadata:
name: allow-internal-front
namespace: front
spec:
order: 800
ingress:
- action: Allow
protocol: TCP
destination:
selector: app == 'nginx-front'
egress:
- action: Allow
protocol: TCP
destination:
selector: app == 'nginx-front'
---
apiVersion: projectcalico.org/v3
kind: NetworkPolicy
metadata:
name: allow-internal-back
namespace: back
spec:
order: 800
selector: app == 'nginx-back'
ingress:
- action: Allow
destination:
selector: app == 'nginx-back'
egress:
- action: Allow
destination:
selector: app == 'nginx-back'
Estas políticas buscan que se cumplan sus selectores y dejan pasar el tráfico dentro de sus respectivos namespaces a todos los objetos que tengan la etiqueta app y su valor sea nginx-$namespace.
Este tipo de políticas sencillas se pueden desplegar con el formato tradicional de Kubernetes. Aunque en teoría pueden mezclarse los formatos, personalmente no lo recomendaría. La sintaxis entre las políticas de Calico y las de Kubernetes también varía un poco y puede causar confusión si las mezclamos.
Nuestro último paso es habilitar el tráfico cruzado para que podamos llegar al Back desde nuestro Front, en el puerto 3306 y en el puerto 80. Debemos habilitar ambos puesto que aunque accedamos a través del puerto del servicio, tenemos que acceder también al pod. Este sería el YAML que tendríamos que aplicar.
apiVersion: projectcalico.org/v3
kind: GlobalNetworkPolicy
metadata:
name: allow-traffic-front-back
spec:
order: 800
ingress:
- action: Allow
protocol: TCP
source:
namespaceSelector: app == 'nginx-front'
destination:
namespaceSelector: app == 'nginx-back'
ports:
- 3306
- 80
Si realizamos una prueba de acceso, veremos que la comunicación no se ha habilitado. El motivo es que estamos utilizando como selector una etiqueta definida en un namespace, que todavía no existe. Para crear dichas etiquetas tiramos los siguientes comandos:
kubectl label namespace back app="nginx-back"
kubectl label namespace front app="nginx-front"
Si ahora repetimos la prueba anterior veremos que podemos acceder sin problemas, tal y como lo habíamos definido en el diagrama.
Conclusiones
Este post pretende ser un ejemplo de la sintaxis y las capacidades que nos ofrece Calico: muchas de sus funcionalidades son equivalentes a las políticas de red por defecto y no todas las organizaciones van a necesitar Calico. Sin embargo es un sistema muy útil para definir políticas de red a nivel de todo el clúster, pero no es su única funcionalidad. En este post podemos ver cómo habilitar sólo el acceso a algunas aplicaciones desplegadas en Kubernetes desde una VPN.
La potencia de Calico está fuera de duda, pero he tenido que realizar muchas pruebas y me he quedado con un sabor agridulce debido a que me he encontrado con muchísimos poltergeist:
-
Las etiquetas de namespaceSelector han funcionado “a veces”. En algunas ocasiones he podido utilizar el nombre del namespace (como en kube-system), pero no para habilitar el tráfico interno en front o back.
-
Me he encontrado con un funcionamiento la mar de extraño al ir añadiendo reglas de tipo Allow: a veces afectan a otros objetos que no deberían y bloquean el tráfico a dichos objetos (WTF!). Por ejemplo, tras aplicar las políticas default-deny-traffic y allow-traffic-front-back todo funcionaba como se había diseñado, pero si después aplicabamos alguna otra de las descritas en este post, el tráfico entre los namespaces de front y back dejaba de funcionar. No se que causaba la incidencia, pero no he encontrado mucha información al respecto y entiendo que debe de ser alguna metida de pata mía o algún problema relacionado con mi instalación. Si algún lector tiene ve el fallo, me encantaría que me escribiera para corregir este post :P.
Me ha pasado tanto en Minikube como en Google Kubernetes Engine y que me tiene desconcertado.
Muchas gracias por leerme y espero que os haya gustado.
Documentación
-
Calico for Kubernetes networking: the basics & examples (ENG)
-
Características propias de las Network Policies de Calico (ENG)
-
Uso y configuración de calicoctl en clústers de Kubernetes (ENG)
-
Laboratorio de Encodeflush sobre Global Network Policies (ENG)
Revisado a 01-05-2023