Kubernetes (I): qué es y primeros pasos
2019-06-05 18:00Tras unos meses un poco desaparecido debido a temas personales… volvemos a la carga con un clásico. Es prácticamente imposible tener un blog de temática tecnológica y Cloud sin hablar del producto estrella de dicho mundillo, así de cómo su orquestador principal: hablamos respectivamente de los contenedores y kubernetes.
Introducción
Cuando hablamos de contenedores y orquestadores, primero tenemos que explicar un poco de teoría para que la gente no se pierda en la terminología que se va a utilizar.
En este posts, vamos a aprender sobre:
-
Qué es un contenedor y un orquestador
-
Qué es Kubernetes
-
K8s: maestros, esclavos y servicios básicos de cada uno de ellos.
-
Contenedores, Pods, Namespaces, Deployments, ReplicaSets y Services
-
Escribir nuestros YAML para crear objetos en K8s.
Contenedores
Se podría definir un contenedor como la agrupación en una unidad del código de una aplicación y todas las dependencias (librerías, variables, etc) necesarias para que ésta funcione. Se diferencian de una máquina virtual a que éstas emulan todo un sistema operativo mientras que los contenedores no, haciendo que sean más pequeños y ágiles.
No son una idea nueva, puesto que ha habido aproximaciones al concepto desde los 80, pero sí que están casi convirtiéndose de facto en el estándar que utilizan muchos servicios y aplicaciones que utilizamos en la nube debido a su versatilidad.
De todos los sistemas de creación de contenedores, el más conocido es Docker, pero tenemos otros cómo ContainerD o LXC.
La función de este post no es enseñar cómo crear contenedores, sino cómo orquestarlos, pero si alguien necesita dicha información, hay un tutorial maravilloso creando por la comunidad de DigitalOcean aquí.
Orquestadores
Aunque mejoremos la portabilidad de una aplicación al “contenerizarla”, seguimos teniendo que vigilar que su estado sea correcto para garantizar el buen funcionamiento de la misma. Sólo por usar contenedores no ganamos una mejor gestión, para ello tenemos que utilizar un orquestador de contenedores
Dentro de un contenedor podemos tener de todo: desde aplicaciones web (un Django, un proxy web, un servidor web básico, etc), bases de datos relacionales (MySQL o PostgreSQL), bases de datos no relacionales (como MongoDB o Cassandra) o casi lo que queramos. Sin embargo, si nuestra aplicación tiene un mínimo de complejidad, es probable que esté compuesta por más de un contenedor y sea necesario utilizar un sistema que garantice que todos los contenedores funcionen de forma coherente.
Esa es la función de un orquestador: desplegar los contenedores necesarios y asegurar que éstos se encuentran en el estado deseado: manteniendo un mínimo de copias, realizando el balanceo de carga entre ellos y garantizando la coherencia en su conjunto.
Al igual que existen multiples formas de crear contenedores también existen diferentes orquestadores:
-
Kubernetes: es un sistema de orquestación de contenedores desarrollado por Google a partir de sus experiencias internas y liberado a mediados del 2014. Actualmente es el sistema más utilizado de todos y tiene implementaciones en cada uno de los principales proveedores de nube pública.
-
Docker Swarm: es el sistema desarrollado por Docker para orquestar sus contenedores. Aunque ha perdido algo de protagonismo, sigue teniendo peso en el mercado a pesar de carecer de algunas funcionalidades que si tiene su competencia. Microsoft Azure lo soporta de forma nativa.
-
Nomad: es el sistema utilizado para orquestar workloads, ya sea en contenedores o máquinas virtuales, desarrollado por Hashicorp. Aunque no lo he usado personalmente, tengo muchas ganas de hacerlo.
K8s o Kubernetes
Según su página oficial, Kubernetes es…
es un sistema de código abierto para automatizar el despliegue, el escalado y la gestión de aplicaciones contenerizada.
Para utilizar Kubernetes, primero debemos instalarlo o utilizar alguna solución en la nube como EKS (el sistema de Amazon) o GKE (la implementación de Google Cloud). Podemos ver más información al respecto aquí. En este post, voy a utilizar un kubernetes en local para enseñar sus conceptos básicos.
Arquitectura de K8s
Aunque ya podríamos empezar a desplegar algunas aplicaciones, primero debemos explicar un poco más de teoría (si, se que es un poco pesado, pero sólo será en el primer post :) )
Conceptos básicos
Kubernetes no es un orquestador de contenedores, sino de lo que llamamos pods. Un pod se compone de uno o más contenedores agrupados en una unidad lógica y son la unidad mínima que gestiona Kubernetes. Los pods se despliegan dentro de una entidad lógica independiente que se llaman namespaces.
Así ya hemos definido las unidades lógicas y el lugar donde van a ser desplegadas, pero todavía no tenemos definido su comportamiento. Para ello utilizamos los ReplicaSet y los Deployment:
-
Los ReplicaSet son un objeto de Kubernetes que asegura que se esté ejecutando un número mínimo de clones de un pod.
-
Los Deployment nos añaden la capacidad de controlar cómo se va a comportar un ReplicaSet cuando lo actualicemos. Gracias a ellos podremos realizar rolling updates o planchados en función de nuestras necesidades.
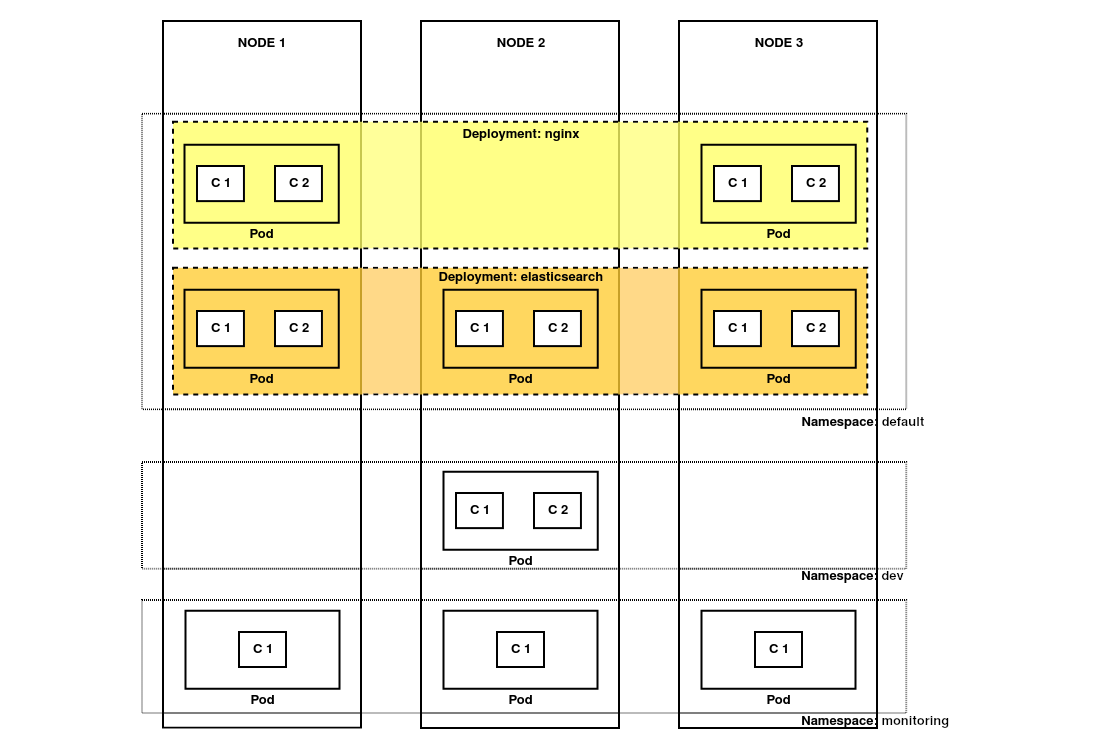
Nodos y servicios
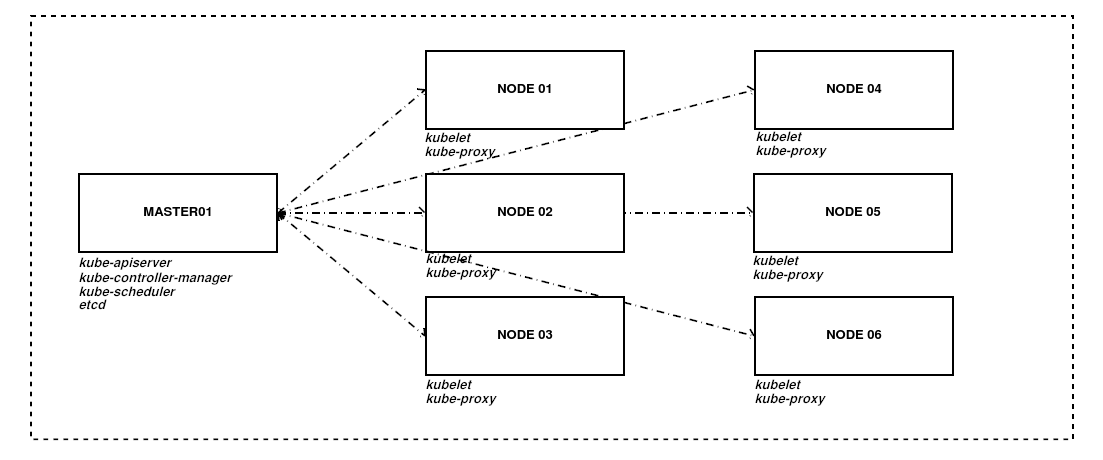
A modo de ejemplo este sería la arquitectura de un clúster complejo. En un entorno productivo tenemos uno o más nodos maestros que se conectan a los nodos de trabajo, indicándoles lo que tienen que hacer. Aunque se puede desplegar en los maestros, no es algo recomendado.
Cada nodo maestro tiene una serie de servicios propios:
-
kube-apiserver: proporciona acceso a través de una API/REST al estado de los elementos del clúster y le permite validar y configurar los datos para objetos como pods, servicios, etc.
-
kube-controller-manager: Es el demonio que se encarga de controlar el estado del clúster y cambiarlo al estado deseado. Por ejemplo: se encarga de asegurar que el número de replicas de un pod, definido en un ReplicaSet es el adecuado.
-
kube-scheduler: Es el planificador que controla el uso de cada uno de los nodos de K8s y que selecciona donde se van a ejecutar los trabajos en función de los recursos que haya disponibles.
-
etcd: Es la base de datos de clave-valor que utiliza K8s para guardar el estado y la configuración del clúster en un momento completo.
En cambio, cada worker tiene otros servicios:
-
kubelet: es el agente que habilita la comunicación entre los nodos maestros y los nodos de trabajo o esclavos.
-
kube-proxy: es el servicio que gestiona todas las operaciones de red de nuestro clúster y se encarga de que el tráfico de los usuarios llegue hasta el contenedor adecuado.
Aunque éstos no son todos los elementos y se han tratado muy por encima, sí son los elementos básicos que tenemos que conocer para empezar a utilizar K8s. Prometo que los próximos posts al respecto van a ser mucho más prácticos.
A 2023, la comunidad está desarrollando un sistema que no requiere del uso de kubelet en los nodos, pero es experimental y está fuera del contenido de este post.
MicroK8s
Kubernetes está formado por una gran cantidad de elementos que funcionan conjuntamente para proporcionar la funcionalidad que se espera. Montar un clúster de 0 es algo que haremos en posts futuros, pero en este caso vamos a utilizar MicroK8s para acelerar las cosas y hacer un par de ejemplos prácticos.
MicroK8s es un sistema empaquetado con snap y que hemos elegido gracias a su versatilidad y facilidad de instalación en Ubuntu.
Para instalarlo, hacemos lo siguiente:
# First we have to install the snap daemon
# If we are using Debian or Ubuntu-based distributions
sudo apt install snapd
# Other distributions check this:
# https://docs.snapcraft.io/installing-snapd/6735
# Second, we use snap to install Microk8s
sudo snap install microk8s --classic --channel=1.27/stable
Si todo va bien, haciendo sudo snap info microk8s veremos en la última línea algo parecido a esto:
microk8s (1.27/stable) v1.27.0 from Canonical✓ installed
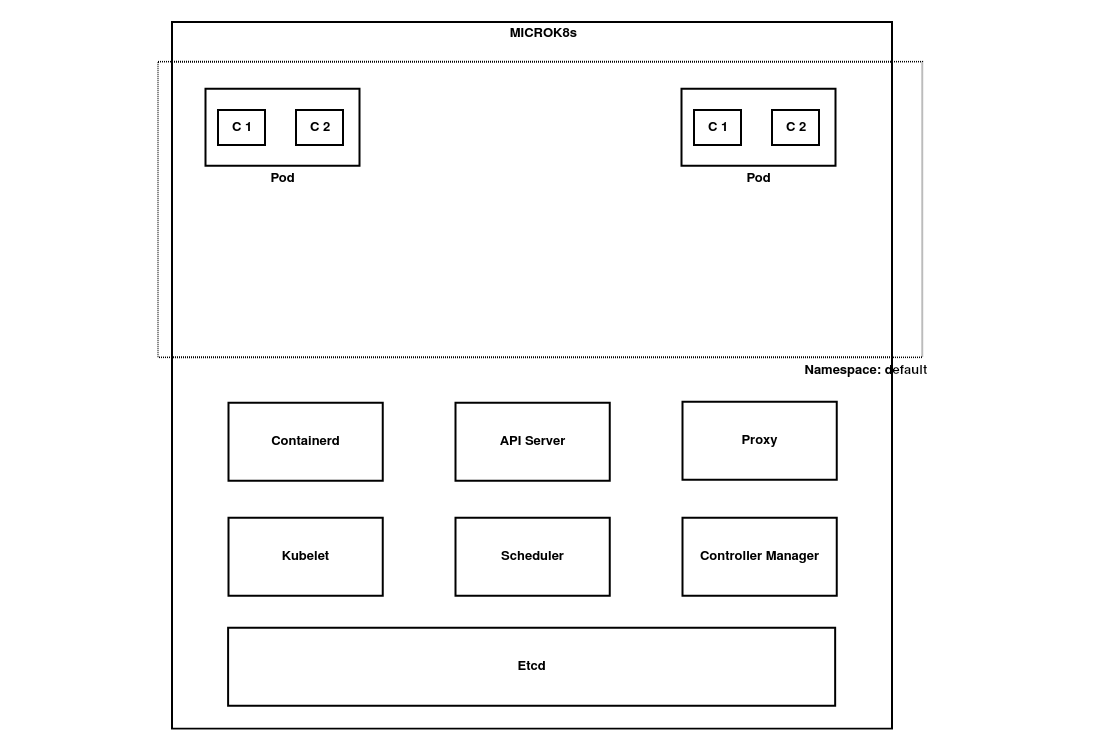
Al ser un sistema basado en un sólo nodo, podemos ver que los servicios de los nodos maestro y
esclavo se encuentran todos desplegados de forma conjunta con microk8s.inspect. Este sería el esquema final de nuestro K8s:
También deberemos añadir nuestro usuario al grupo de Microk8s y reiniciar para que el cambio sea efectivo.
sudo usermod -a -G microk8s $(echo $USER)
Primeros pasos
Ya tenemos nuestro K8s funcionando y podemos empezar a utilizarlo, pero primero debemos aprender a conectarnos al clúster creado. Para conectarnos y controlar nuestro K8s, usamos una herramienta llamada kubectl que viene instalada por defecto con microk8s. Al escribir en nuestra terminal microk8s. y pulsar el tabulador podremos ver todos los subcomandos que vienen incluidos.

Vamos a obviar la mayoría de ellos y a fijarnos en microk8s.kubectl config view. Con él podremos ver la configuración de kubectl y todos sus diferentes contextos (cada contexto se corresponde con la configuración de un clúster diferente de k8s).
tangelovers@tangeblog.me$microk8s.kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://127.0.0.1:16443
name: microk8s-cluster
contexts:
- context:
cluster: microk8s-cluster
user: admin
name: microk8s
current-context: microk8s
kind: Config
preferences: {}
users:
- name: admin
user:
token: REDACTED
Deployments y Services
Con nuestro clúster instalado y configurado ahora debemos utilizar la CLI para probarlo.
Si quisiésemos ejecutar una imagen de Nginx, necesitaríamos indicar la imagen que vamos a utilizar y el nombre del despliegue. Podríamos hacerlo de forma rápida con el comando:
microk8s.kubectl create deployment nginx --image=nginx:stable-alpine
Este comando nos generará un Deployment llamado Nginx, con la imagen de Nginx basada en Alpine Linux de Dockerhub.
Sin embargo, aunque esté desplegado en nuestro clúster, no podremos acceder a él. Para ello, debemos generar un nuevo objeto que nos permita acceder desde del clúster: un Service.
El Service utiliza el kube-proxy de los nodos del clúster para generar una dirección virtual y un nombre que podemos utilizar para acceder al conjunto de pods definidos en un ReplicaSet (dentro de un Deployment o no).
Si queremos que nuestro deployment nginx se muestra en el puerto 8000, utilizamos el siguiente comando:
microk8s.kubectl expose deployment nginx --port=8000 --target-port=80 --type=NodePort
Hace lo siguiente:
-
Genera un servicio de tipo NodePort. Hablaré más en profundidad en próximos pods al respecto, pero mientras podemos ver más documentación aquí.
-
Se genera un mapeo en el puerto 8000 y conecta contra el puerto 80 de los contenedores del Deployment.
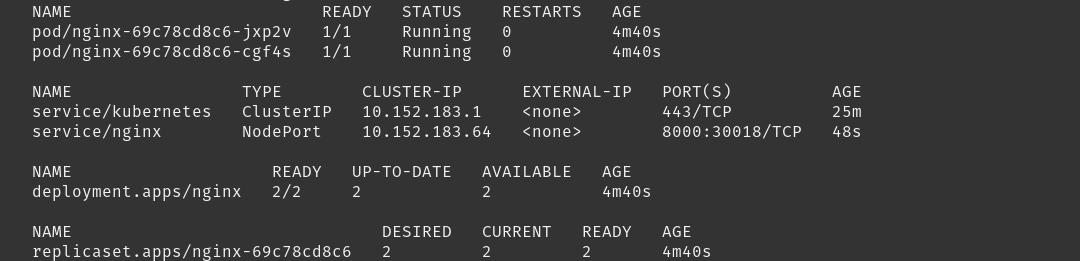
Podemos ver el resultado de todas nuestras acciones: microk8s.kubectl get all --all-namespaces
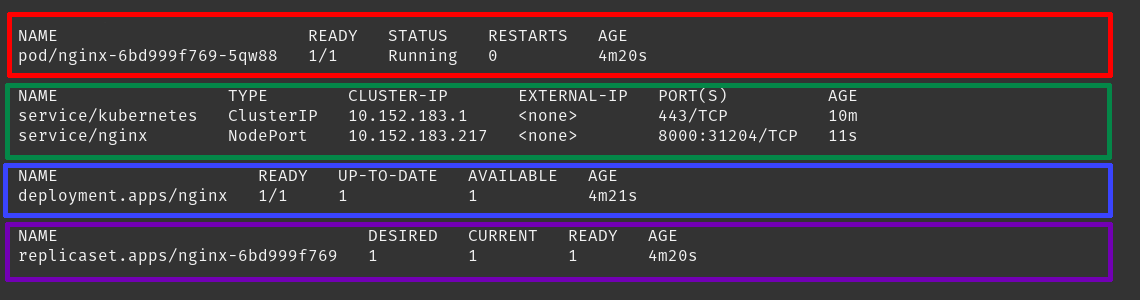
Utilizando el código de colores tenemos lo siguiente:
-
En color rojo tenemos los pods que hemos desplegado.
-
En color verde tenemos los servicios expuestos en nuestro clúster de K8s y las IPs a través de las cuales podemos acceder a ellos.
-
En color azul tenemos el Deployment generado.
-
En color morado también podemos ver el ReplicaSet que gestiona nuestro Deployment.
Ahora podríamos acceder a nuestro contenedor de Nginx a través de la dirección http://10.152.183.217:8000
YAMLs: definiendo objetos en K8s
En los últimos apartados hemos estado generando objetos muy sencillos en Kubernetes, pero cuando queremos definir objetos más complejos, debemos generar ficheros yaml.
Primero vamos a borrar lo que hemos creado antes:
microk8s.kubectl delete service nginx
microk8s.kubectl delete deployment nginx
Ahora generamos un nuevo fichero yaml con el siguiente contenido (que está basado en este ejemplo):
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:stable-alpine
ports:
- containerPort: 80
Como podemos ver en el fichero le estamos indicando a nuestro cluster una serie de objetivos:
-
Que tiene que apuntar a la API apps/v1 (desde Kubernetes 1.16 en adelante).
-
Que el tipo de objeto que tiene que crear es un Deployment.
-
Que el ReplicaSet del deployment va a tener dos replicas.
-
Que va a utilizar la imagen de Nginx, basada en Alpine Linux y a utilizar el puerto 80.
-
Etiquetamos las imagenes con el par “app: nginx”
Procedemos a aplicarlo con microk8s.kubectl apply -f nginx-deployment.yaml. El sistema proporciona un control de errores que comprobaría la sintaxis del fichero antes de ejecutarlo y en el caso de que lo ejecutásemos más de una vez, sólo aplicaría los cambios que hubiesemos realizado en el fichero.
microk8s.kubectl apply -f orig.yaml
deployment.apps/nginx unchanged
Por último, vamos a crear un nuevo fichero para gestionar el servicio que nos permita conectarnos a nuestro Deployment:
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
type: NodePort
ports:
- protocol: TCP
port: 8000
targetPort: 80
En el fichero le estamos indicando a K8s lo siguiente:
-
Que cree un Service con nginx como nombre
-
Que enlace con los contenedores cuya etiqueta sea “app: nginx”
-
Que el Service sea del tipo NodePort, exponga el puerto 8000 al exterior y que lo enlace con el puerto 80 del contenedor.
Si volvemos a ejecutar microk8s.kubectl get all --all-namespaces, veremos que el resultado es muy similar (tenemos dos pods en lugar de uno) al obtenido cuando utilizabamos comandos sueltos, con la diferencia que ahora tenemos sendos ficheros de texto y controlamos mejor el hacer seguimiento a cualquier modificación que hagamos.
Y poco más por hoy, más Kubernetes en próximos posts :D
Documentación
-
Sistemas de ejecución de contenedores: Docker (ENG), Containerd (ENG) y LXC (ENG)
-
Sistemas de orquestación de contenedores: Kubernetes (ENG), Nomad (ENG) y Docker Swarm (ENG)
Revisado a 01-05-2023