Kubernetes (II): DaemonSets, StatefulSets, Ingress y almacenamiento
2020-02-01 18:00Tras unos pocos meses de atraso, continuamos con los posts de Kubernetes :)
En el post anterior aprendimos unos cuantos conceptos básicos (pods, namespaces, deployments, replicasets y services) de Kubernetes. Son lo mínimo que debería saber un usuario (que no un administrador) para empezar a utilizar nuestro timonel favorito con un mínimo de cabeza, pero no son los únicos y existen otros objetos importantes.
Hoy vamos a explicar algunos conceptos extra que mejorarán nuestra comprensión de la herramienta y ayudará a que desatemos todo su potencial.
De momento vamos a seguir utilizando MicroK8s para los ejemplos que hagamos, pero si algún lector tiene otro clúster instalado podrá utilizarlo también. Leña al mono.
Conceptos básicos II
Kubernetes es una solución muy completa para el despliegue y manejo de pods: podemos usarlo para casi cualquier cosa que se nos ocurra. Con los ReplicaSet y Services del anterior post podemos generar una gran cantidad de servicios web pero… ¿Y si tenemos otras necesidades?
DaemonSet
En la infraestructura tradicional, cuando añadidos un nuevo servidor a veces tenemos que desplegar ciertos servicios. Algunos ejemplos son un demonio de monitorización, un colector de logs o el cliente de una base de datos de conocimiento (CMDB).
En Kubernetes podemos generar un servicio, indicarle el número de copias y escalarlo. Pero de momento, no tenemos forma de garantizar que la distribución de pods a lo largo de los nodos sea la correcta. Si necesitamos como mínimo un pod corriendo en cada nodo de nuestro clúster, podemos utilizar los DaemonSet.
Un DaemonSet es un tipo de objeto que nos asegura que todos los nodos de nuestro clúster (o algunos, en función de lo que necesitemos), tengan corriendo una copia de un pod.
La creación de este tipo de objetos es muy parecida a las de un despliegue, cambiando su kind a DaemonSet y algunos pequeños cambios. A modo de ejemplo, vamos a desplegar un DaemonSet de Fluentd, un recolector de Logs desarrollado por Elastic.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
spec:
selector:
matchLabels:
name: fluentd
template:
metadata:
labels:
name: fluentd
spec:
containers:
- name: fluentd
image: quay.io/fluentd_elasticsearch/fluentd:v4.3
terminationGracePeriodSeconds: 30
Los DaemonSet necesitan algunos campos extra en su especificación como selector y template. No vamos a entrar aun a fondo en ellos, pero si alguien quiere adelantar información puede consultar la documentación.
Si aplicamos el código YAML anterior, veremos lo siguiente:
# Creamos el DaemonSet
kubetl apply -f daemonset.yml
daemonset.apps/fluentd created
# Vemos el estado de nuestro DaemonSet
kubectl get daemonset
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd 1 1 1 1 1 <none> 255s
Para limpiar lo creado anteriormente tan sólo tendríamos que ejecutar el comando bash kubectl delete daemonset fluentd
StatefulSet
Kubernetes gestiona eficazmente aplicaciones sin estado: los pods de un Deployment pueden ser sustituidos por otra copia idéntica o generar más copias si la carga de trabajo aumenta. Este comportamiento es muy útil para aplicaciones que procesan datos de una cola, pero no para otros como bases de datos, servidores de correo, etc.
Para que un pod pueda tener este comportamiento, debe ser stateless y no stateful. Si una aplicación es dependiente del estado de ésta para responder a los clientes, se dice que tiene estado. Es un concepto de arquitectura de software que impacta de lleno en la forma de gestionar los pods en Kubernetes. Todos estos ejemplos tendrían problemas con su estado:
-
Nuestra aplicación necesita los datos o el orden de peticiones anteriores para poder continuar trabajando y/o no está preparada para trabajar dichas peticiones en paralelo.
-
Nuestra aplicación utiliza sesiones: cuando nuestro pod se muera, la sesión lo hará con él, impactando a quien use la aplicación en el proceso.
-
Las bases de datos relacionales usan sistemas transaccionales para garantizar la coherencia y consistencia de los datos. Si un pod de este tipo fuese reemplazado en medio de una transacción, podría provocar inconsistencias en los datos almacenados.
Para ejecutar este tipo de cargas en Kubernetes podemos utilizar los llamados StatefulSet. A diferencia de los Deployment, los StatefulSet mantienen una identidad fija para cada uno de los pods y no son intercambiables entre sí, puesto que se encuentran asociados a un almacenamiento que se mantiene cada vez que el pod es reemplazado.
Con el siguiente código vamos a generar un servidor Nginx que mantiene su estado:
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-with-state
spec:
serviceName: "nginx-with-state"
replicas: 1
selector:
matchLabels:
app: nginx-with-state
template:
metadata:
labels:
app: nginx-with-state
spec:
containers:
- name: nginx
image: nginx:stable-alpine
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
En las plantillas de un StatefulSet, definimos un volumen para almacenar los datos. En este caso, creamos un volumen de nombre www para almacenar el estado del pod. Si utilizamos MicroK8s, es posible que falle debido a que nuestro clúster no pueda asignarle ningún tipo de volumen (salvo que habilitemos el addon de Storage), pero si utilizamos el siguiente YAML no tendremos ningún problema:
Debemos cambiar $NOMBREDEMIHOST por el nombre del host donde tengamos instalado microk8s.
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
annotations:
"storageclass.kubernetes.io/is-default-class": "true"
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: www
labels:
type: local
spec:
storageClassName: local-storage
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
local:
path: "/tmp/data"
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- $NOMBREDEMIHOST
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-with-state
spec:
serviceName: "nginx-with-state"
replicas: 1
selector:
matchLabels:
app: nginx-with-state
template:
metadata:
labels:
app: nginx-with-state
spec:
containers:
- name: nginx
image: nginx:stable-alpine
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
Al aplicar la plantilla veremos lo siguiente:
# Primero creamos todas las dependencias necesarias para que se ejecute en microk8s
kubectl apply -f full.yml
storageclass.storage.k8s.io/local-storage created
persistentvolume/www created
statefulset.apps/nginx-with-state created
# Vemos que el pod ha levantado dentro del StatefulSet
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-with-state-0 1/1 Running 0 10s
Para limpiar lo creado anteriormente, ejecutamos el siguiente comando:
# Borrado de los elementos ya creados
kubectl delete statefulset nginx-with-state
kubectl delete pvc www-nginx-with-state-0
kubectl delete pv www
kubectl delete StorageClass local-storage
Ingress
Los Ingress son objetos que controlan el acceso desde fuera del clúster a servicios dentro del mismo, generalmente a través de endpoints HTTP. Podemos obtener más funcionalidades que con un Service “pelao”: generar un único punto de entrada para diferentes Deployments, balanceo de carga, SSL Offloading y/o controlar varios virtualhosts con diferentes nombres (name-based virtual hosting). Todo el tráfico es enrrutado hacia el clúster a través de las reglas que definimos en el recurso Ingress.
Antes de utilizar un ingress, necesitamos habilitar previamente un Ingress Controller, que es una especie de enrrutador. Aunque el más conocido (y usado por defecto) es el NGINX ingress controller, no es el único y existen una gran variedad de ellos.
Para utilizarlo en Microk8s, tan sólo tenemos que habilitar el addon ingress con sudo microk8s.enable ingress.
Tras habilitarlo, ahora necesitamos algún servicio que enrrutar. Para ello, vamos a volver a utilizar las plantillas de Nginx del post anterior (Deployment y Service ).
# Creamos el Deployment y el Service genéricos
kubectl apply -f https://gitlab.com/tangelov/proyectos/raw/master/templates/kubernetes/basic-nginx-deployment.yml
kubectl apply -f https://gitlab.com/tangelov/proyectos/raw/master/templates/kubernetes/basic-nginx-service-nodeport.yml
Si ahora miramos los elementos que hemo desplegados, veremos nuestro Ingress Controller y el Nginx:
# Listamos todos los Deployment y los Services
kubectl get deployment,svc,ds --all-namespaces
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
kube-system deployment.apps/calico-kube-controllers 1/1 1 1 11m
default deployment.apps/nginx 2/2 2 2 6m50s
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default service/kubernetes ClusterIP 10.152.183.1 <none> 443/TCP 11m
default service/nginx NodePort 10.152.183.159 <none> 8000:32471/TCP 6m42s
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
ingress daemonset.apps/nginx-ingress-microk8s-controller 1 1 1 1 1 <none> 10m
kube-system daemonset.apps/calico-node 1 1 1 1 1 kubernetes.io/os=linux 11m
Si accedemos a la IP del Nodeport podremos acceder a nuestro Nginx, pero en lugar de utilizar dicho endpoint, vamos a crear un Ingress para acceder al mismo:
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /nginx
pathType: Prefix
backend:
service:
name: nginx
port:
number: 80
En esta plantilla le estamos indicando al Ingress Controller que acceda a nuestro service Nginx a través de la ruta /nginx y que envíe las peticiones al service Nginx al puerto 80.
Ahora nuestro servicio es accesible a través del Ingress Controller. Al utilizar MicroK8s, éste se genera por defecto en https://127.0.0.1 (El Ingress Controller también genera un certificado autofirmado). Debido a la regla que hemos creado, si accedemos a https://127.0.0.1/nginx podremos acceder al Nginx que acabamos de desplegar.
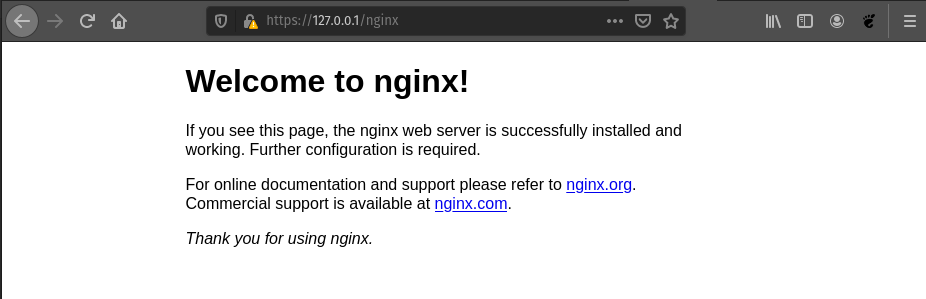
Si queremos borrar lo antes creado, ejecutamos los siguientes comandos:
# Borramos los elementos antes creados
kubectl delete ingress ingress
kubectl delete svc nginx
kubectl delete deployment nginx
Conceptos sobre almacenamiento
Una gestión correcta del estado de las aplicaciones es algo vital para que su funcionamiento sea óptimo en Kubernetes. Siempre podemos coger y almacenar los datos que necesite la aplicación en un volumen (que montaríamos en el arranque), pero los volúmenes pueden tener muchas limitaciones si pensamos en esta solución (especialmente en clústers multizonales).
Aunque una aplicación no tenga estado, siempre suele necesitar ciertos datos de configuración para funcionar: valores en un servidor, cadenas de conexión a bases de datos o endpoints, certificados o credenciales para funcionar, etc. De esta forma podríamos dividir los datos de una aplicación en tres partes:
-
Datos de estado: si la aplicación necesita los datos de ejecuciones anteriores para continuar, podemos crear un volumen y asociarlo a un pod a través de un StatefulSet como hemos hecho antes. Si utilizamos un proveedor de nube pública, podemos almacenar el estado de una aplicación (si ésta lo soporta), en uno de los servicios gestionados del mismo.
-
Datos de configuración: si almacenamos todos los datos en un sitio externo (como una base de datos) o si necesitamos algunos certificados para verificar quien se conecta, tan sólo necesitamos esos datos en los pods para que la aplicación acceda a ellos.
-
Otros: son datos que mejoran la experiencia de uso de la aplicación pero que no impiden su buen funcionamiento (como los logs que generan, etc).
La API de Kubernetes es muy completa, pudiendo gestionar todas estas necesidades. Para gestionar volúmenes de datos, necesitamos usar StorageClass, PersistentVolume y PersistentVolumeClaims. En cambio, si queremos gestionar ficheros sueltos (de configuración o no) o credenciales, tenemos que utilizar configmaps y secrets.
Configmaps y secrets
Para configurar una aplicación desplegada en K8s podemos utilizar dos tipos de objetos: configmaps y secrets. Aunque funcionan de manera parecida, el contenido de los secretos está ofuscado y permite almacenar datos sensibles a los que no puede acceder cualquiera en el clúster. Si asignáramos permisos de sólo lectura a un usuario en K8s, éste no podría ver el contenido de los secretos pero si el de los configmaps.
Para que un pod pueda utilizar un configmap o un secreto, éste debe ser asociado al mismo, ya sea como variable de entorno o como volumen, según las necesidades que tengamos. Si el contenido de nuestro objeto contiene más de un elemento clave-valor, al montarlo en un directorio, aparecerán tantos ficheros como elementos tengamos.
En el siguiente ejemplo vamos a montar un fichero index.html personalizado a través de un ConfigMap y vamos a cargar como variables de entorno un usuario y una contraseña procedentes de un secreto, en los dos de un deployment de Nginx.
Primero creamos un fichero index.html con el siguiente contenido…
<!DOCTYPE html>
<html>
<head>
<title>¡Bienvenido a nuestro Nginx en K8s!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>¡Bienvenido a nuestro Nginx en K8s!</h1>
<p>Si ves esta página en castellano es porque el laboratorio ha funcionado correctamente.</p>
</body>
</html>
utilizando el comando kubectl create configmap nginx-custom-index --from-file=index.html.
Tras crear el configmap, ahora vamos a crear un secreto con dos claves valor (usuario y contraseña), con el siguiente comando: kubectl create secret generic nginx-secret --from-literal=username=usuariobbdd --from-literal=password=contraseñamolona
Podemos ver que ambos se han creado correctamente:
NAME TYPE DATA AGE
secret/default-token-qnhrx kubernetes.io/service-account-token 3 7d22h
secret/nginx-secret Opaque 2 70s
NAME DATA AGE
configmap/nginx-custom-index 1 54s
Como ya hemos comentado la diferencia fundamental entre un secret y un configmap es que uno está almacenado cifrado y el otro no, si cambiamos el output a YAML podemos verlo mejor:
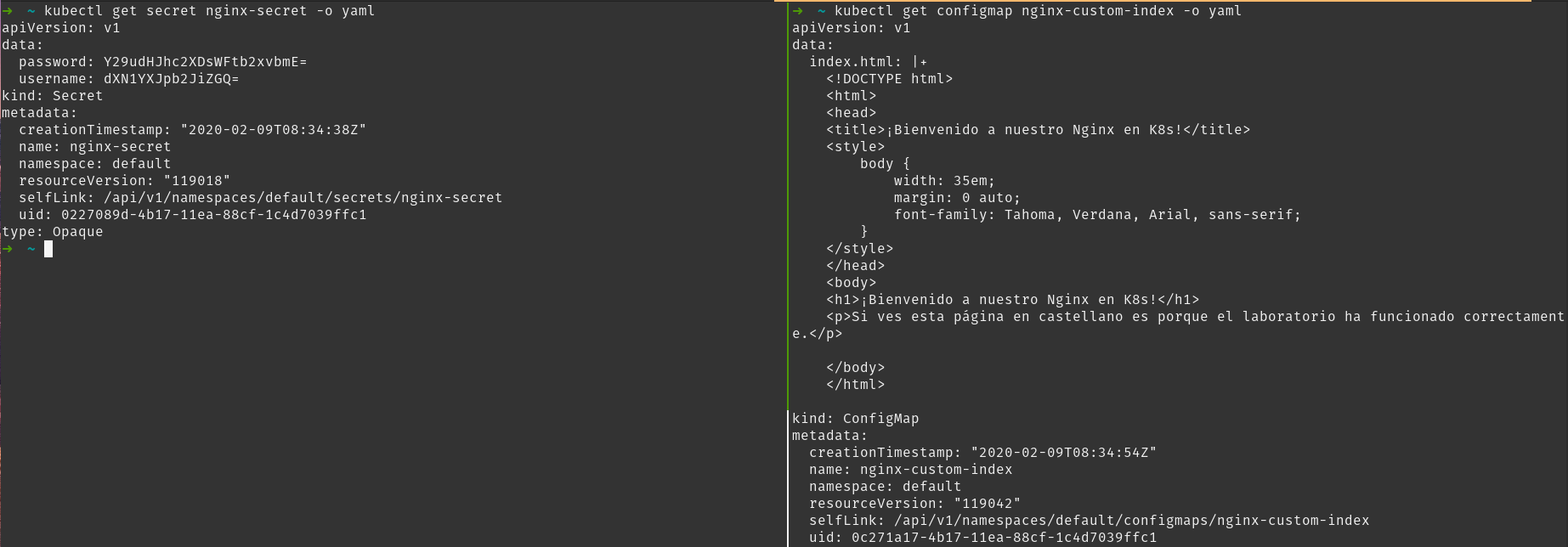
Si utilizamos ficheros YAML para generar secretos, tendremos que almacenar el valor de cada clave-valor en base64. Aquí podemos ver algún ejemplo y más explicaciones.
Ahora vamos a crear un Deployment que haga uso de dichos elementos con el siguiente código.
Si analizamos el YAML podemos ver cómo vamos a montar los configmaps como si fuesen un volumen y los secretos como si fuesen variables de entorno.
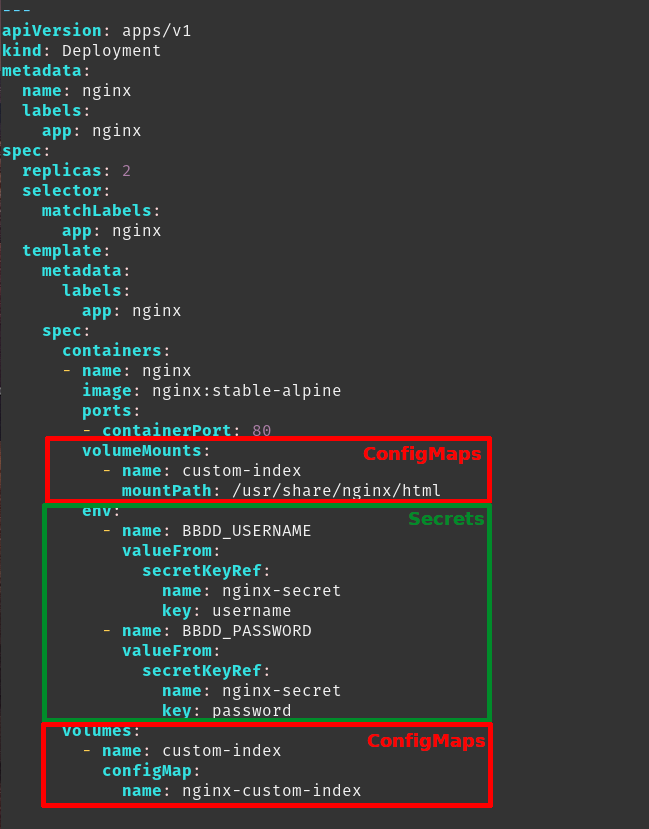
Esto no es una limitación del objeto: los secretos también pueden ser montados como volúmenes y los configmaps como variables de entorno. No vamos a tratar todas las posibilidades en este post y nos remitimos a la documentación oficial.
Ahora accedemos al pod para ver cómo nuestras variables de entorno y nuestro fichero son accesibles:
# Vemos los pods que hemos desplegado de nginx
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-84cdbdf6dd-8m885 1/1 Running 0 132m
nginx-84cdbdf6dd-n5skc 1/1 Running 0 132m
# Nos introducimos en uno de ellos
kubectl exec -ti nginx-84cdbdf6dd-8m885 -- sh
# Comprobamos que las variables están en su sitio:
root@nginx-84cdbdf6dd-8m885:~# echo $BBDD_USERNAME $BBDD_PASSWORD
usuariobbdd contraseñamolona
# Comprobamos el contenido del index.html de Nginx
root@nginx-84cdbdf6dd-8m885:~# cat /usr/share/nginx/html/index.html | grep castellano
<p>Si ves esta página en castellano es porque el laboratorio ha funcionado correctamente.</p>
Para limpiar nuestro clúster, ejecutamos lo siguiente:
# Borramos los elementos antes creados
kubectl delete deployment nginx
kubectl delete configmap nginx-custom-index
kubectl delete secret nginx-secret
Persistent Volumes
Si no vamos a gestionar credenciales y/o configuración y necesitamos modificar durante el proceso los datos de los volúmenes, podemos crear discos de datos y asociarlos a nuestros pods, tal y como hemos hecho en el caso del StatefulSet. Este tipo de volúmenes se llaman en Kubernetes Persistent Volumes.
Para crear, gestionar y asociar un disco como un volumen tenemos que tener en cuenta tres objetos de Kubernetes:
-
StorageClass: Es el tipo de almacenamiento que va a tener el volumen que vayamos a crear. Impacta directamente con las acciones que soporta el volumen: si creamos un volumen cuya clase es nfs, podremos asignarlo a diferentes pods en modo de lectura y escritura, pero no podremos hacerlo con otros tipos, sin que pueda haber corrupción de datos.
-
PersistentVolume: Es una pieza de almacenamiento del clúster que ha sido aprovisionado de una StorageClass y que podemos asociar a un pod. En función de la clase, pueden ser aprovisionados de forma dinámica (automática) o manual (debe ser creado previamente por un administrador).
-
PersistentVolumeClaim: Un PVC es la petición que un pod realiza para asignarse un volumen y en función de su configuración, puede crear un volumen de una clase, de un tamaño determinado, con diferentes modos de acceso (solo lectura, asociación en RW a más de un pod, etc).
Primero vamos a crear una StorageClass. Como estamos utilizando MicroK8s, vamos a apostar por utilizar una clase local, para poder aprovisionar discos locales.
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
En este caso, estamos creando una StorageClass que utiliza discos locales, que es la clase por defecto y que espera a que el disco sea aprovisionado de forma manual para asociarlo a un pod (no soporta en la versión 1.14 la creación automática).
En segundo lugar, vamos a crear un volumen que utilice la clase que acabamos de crear:
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-volume
labels:
type: local
spec:
storageClassName: local-storage
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
local:
path: "/tmp/data"
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- $NOMBREDEMIHOST
Este YAML generará en el hostname $NOMBREDEMIHOST (aquí también debemos cambiar el nombre), un volumen de hasta 10 GB que se encuentra localizado en el nodo en /tmp/data. También podemos crear algunos ficheros en /tmp/data/.
Ahora vamos a generar un PVC y asociar una parte del almacenamiento del volumen a un pod.
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nginx-pvc-storage
spec:
storageClassName: local-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
volumeName: "local-volume"
---
apiVersion: v1
kind: Pod
metadata:
name: nginx-pv-pod
spec:
volumes:
- name: nginx-storage
persistentVolumeClaim:
claimName: nginx-pvc-storage
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "nginx"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: nginx-storage
Podemos comprobar que hay ficheros en la ruta y que los volúmenes se han asociado con los siguientes comandos:
# Comprobamos que existe un PV y un PVC
kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/local-volume 10Gi RWO Retain Bound default/nginx-pvc-storage local-storage 81s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/nginx-pvc-storage Bound local-volume 10Gi RWO local-storage 76s
# Nos metemos dentro del pod y vemos el contenido del volumen
kubectl exec -ti nginx-pv-pod -- bash
root@nginx-pv-pod:/# ls /usr/share/nginx/html/
adios.html hola.html
Si queremos borrar todos los recursos del laboratorio anterior, podemos ejecutar los siguientes comandos:
kubectl delete pod nginx-pv-pod
kubectl delete pvc nginx-pvc-storage
kubectl delete sc local-volume
Y hasta aquí ha llegado el post número dos sobre elementos de Kubernetes. Con esto ya hemos terminado la primera tanda de conceptos y en el siguiente post veremos como ejecutar una aplicación tradicional dentro de un clúster de Kubernetes. ¡Un saludo a todos!
PD: Si deseamos todos los ficheros YAML utilizados en este post, podemos descargarlos desde aquí.
Documentación
-
Conceptos varios de Kubernetes (ENG): DaemonSets, StatefulSets, Ingress e Ingress Controllers, Volúmenes, Configmaps y Secrets
-
Distribución de credenciales de forma segura utilizando secrets (ENG)
-
Configurar volúmenes de datos en clústeres de Kubernetes (ENG)
-
Conceptos sobre almacenamiento en Kuberntes (ENG): Storage Classes, Persistent Volumes and Persistent Volume Claims
Revisado a 01-05-2023