Kubernetes (IV): autenticación y autorización
2020-04-28 10:00Hoy vamos a continuar con la serie de posts relacionados con Kubernetes. Tras el contenido de los post I, II y III, ya sabemos un poco qué es Kubernetes, cómo almacenar datos en nuestro clúster y cómo acceder a nuestros servicios.
En cada post hemos visto como K8s está diseñado para ser escalable y para ello, cualquier servicio necesita ingentes cantidades de hardware (host, switchs, routers, cableado, discos duros, etc).
Si utilizamos una nube pública, nuestro proveedor se encargará de aprovisionar los recursos necesarios, pero seguirá de nuestra mano el tener que distribuir las cargas de trabajo a lo largo del clúster para lograr nuestros objetivos de servicio (alta disponibilidad, distribución en zonas o regiones, etc).
La gran necesidad de recursos nos lleva a hacernos una pregunta: ¿Cómo podemos aprovechar al máximo los recursos de nuestro clúster? La forma más completa se basa en desplegar diferentes aplicaciones que compartan hardware, pero puede no ser lo más seguro.
Así que, ¿cómo podemos aprovechar al máximo y de la manera más segura posible, los recursos de nuestro clúster?
Namespaces
Kubernetes está pensado para que podamos compartir los recursos de nuestro clúster entre diferentes aplicaciones. Esto permite generar clústers más grandes donde pueden convivir varias cargas de trabajo, en lugar de tener clústers pequeños y que dificultan la gestión del conjunto.
Aunque siempre hemos podido desplegar pods y asignarles unos límites en el consumo de recursos (trataremos esto en otros posts), eso solo distribuye los recursos entre las aplicaciones.
Para poder agrupar, aislar o etiquetar objetos en K8s, así como para aplicar cuotas tenemos que utilizar una especie de carpetas lógicas llamadas namespaces. Por el momento, sólo voy a utilizarlos para agrupar los recursos.
Gran parte de los objetos de Kubernetes están ligados al namespace en el que es creado y si no le indicamos ninguno, utiliza el namespace default. Éste es junto a kube-system (donde se despliegan las herramientas propias del clúster) uno de namespaces que suelen existir por defecto en cualquier clúster.
La creación de namespaces es muy sencilla: si quisiésemos crear uno de nombre ghost, tan sólo ejecutaríamos el siguiente comando kubectl create namespace ghost y ya podríamos empezar a utilizarlo.
kubectl get namespaces
NAME STATUS AGE
default Active 1d
ghost Active 1d
kube-node-lease Active 1d
kube-public Active 1d
kube-system Active 1d
Ya podríamos desplegar objetos en él. Algunos de ellos, como los Persistent Volumes o las Storage Class son comunes al clúster, pero otros como los Deployment o los Persistent Volume Claim si lo son. Para ver que objetos son comunes al clúster y no se encuentran “namespaceados” (¡Toma palabro!), podemos ejecutar el siguiente comando kubectl api-resources. Así podemos ver los tipos de objeto que podemos crear y si se definen a nivel de namespace o no.
NAME SHORTNAMES APIVERSION NAMESPACED KIND
bindings v1 true Binding
componentstatuses cs v1 false ComponentStatus
configmaps cm v1 true ConfigMap
endpoints ep v1 true Endpoints
events ev v1 true Event
limitranges limits v1 true LimitRange
namespaces ns v1 false Namespace
nodes no v1 false Node
persistentvolumeclaims pvc v1 true PersistentVolumeClaim
persistentvolumes pv v1 false PersistentVolume
pods po v1 true Pod
podtemplates v1 true PodTemplate
replicationcontrollers rc v1 true ReplicationController
resourcequotas quota v1 true ResourceQuota
secrets v1 true Secret
serviceaccounts sa v1 true ServiceAccount
services svc v1 true Service
mutatingwebhookconfigurations admissionregistration.k8s.io/v1 false MutatingWebhookConfiguration
validatingwebhookconfigurations admissionregistration.k8s.io/v1 false ValidatingWebhookConfiguration
customresourcedefinitions crd,crds apiextensions.k8s.io/v1 false CustomResourceDefinition
apiservices apiregistration.k8s.io/v1 false APIService
controllerrevisions apps/v1 true ControllerRevision
daemonsets ds apps/v1 true DaemonSet
deployments deploy apps/v1 true Deployment
replicasets rs apps/v1 true ReplicaSet
[...]
Autenticación en K8s
Aunque hayamos creado un namespace nuevo, sigue sin hacer separación lógica. Nuestro usuario puede ver los objetos del clúster independientemente del namespace en el que se encuentren. Esto es debido a que podemos hacerlo: nuestra autenticación y autorización (somos administradores) lo permite. La configuración por defecto de Microk8s es ésta.
Para comenzar a limitar lo que se puede hacer en Kubernetes, primero debemos entender que cada usuario tiene primero que autenticarse (quien es) y autorizarse (que puede hacer dentro del clúster). Cualquier operador, cuenta robot o servicio necesita credenciales para interactuar contra el clúster, o mejor dicho, contra las APIs del clúster.
Podemos autenticarnos frente a Kubernetes de diferentes maneras: podemos utilizar certificados, cuentas de servicio o tokens JWT (a través de OpenID). Para simplificar el post, voy a utilizar service account, pero si alguien desea más información al respecto, puede revisar cómo funcionan el resto de sistemas en la documentación adjunta.
Cuentas de servicio
Tras crear nuestro namespace vamos a crear una service account o cuenta de servicio de Kubernetes. Es un tipo de objeto que creamos a nivel de namespace y que nos permite autenticar nuestras aplicaciones dentro del clúster. Para generar una cuenta, podemos aplicar el siguiente código:
apiVersion: v1
kind: ServiceAccount
metadata:
name: ghost-sa
namespace: ghost
Si aplicamos ese fichero, se habrá generado una cuenta de servicio llamada ghost-sa en el namespace ghost. También habrá aparecido un nuevo secreto que contiene el token que podemos utilizar para loguearnos en el clúster.
kubectl get sa,secrets -n ghost
NAME SECRETS AGE
serviceaccount/default 1 1d
serviceaccount/ghost-sa 1 26s
NAME TYPE DATA AGE
secret/default-token-nstql kubernetes.io/service-account-token 3 1d
secret/ghost-sa-token-9qvks kubernetes.io/service-account-token 3 26s
Cuando utilizamos las cuentas de servicio dentro del clúster, éstas se autentican automáticamente, pero para probar nosotros vamos a obtener el token y a añadirlo a nuestro kubeconfig. Para obtener el token ejecutamos el siguiente comando:
kubectl get secrets -o jsonpath="{.items[?(@.metadata.annotations['kubernetes\.io/service-account\.name']=='ghost-sa')].data.token}" -n ghost | base64 --decode
Utilizando dicho token vamos a añadir una entrada en nuestro kubeconfig (suele estar en ~/.kube/config):
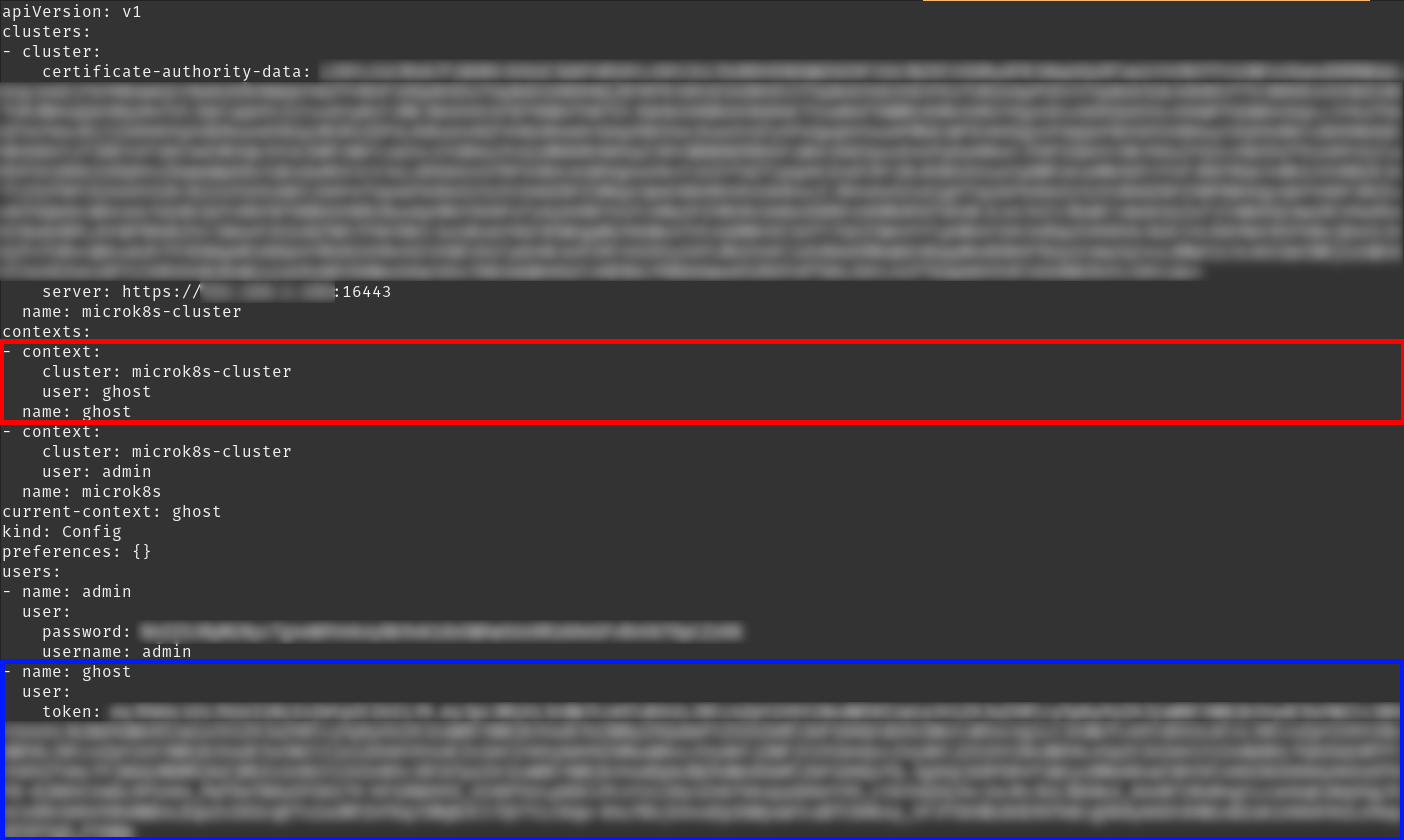
-
La parte azul es la configuración del nuevo usuario que utiliza directamente el token que hemos obtenido en el paso anterior.
-
La parte roja se corresponde con un nuevo contexto que utilizaremos para conectarnos con esta cuenta de servicio.
Autorización en K8s
Ya tenemos nuestro namespace y nuestra cuenta de servicio, pero antes de explicar cómo funciona la autorización, es necesario comentar cómo interactuamos contra Kubernetes:
-
Kubernetes tiene diferentes APIs.
-
Cada una posee diversos recursos sobre los que podemos realizar acciones.
-
Cada API tiene una serie de verbs o acciones, que podemos realizar sobre uno o más recursos.
Imaginemos que hemos generado una cuenta de servicio y nos hemos autenticado contra el clúster. Ahora cada operación que hagamos,
Una forma de interactuar es utilizar kubectl apply -f $fichero. Si utilizaramos este fichero de ejemplo estaríamos haciendo lo siguiente:
-
Interactuaríamos contra la API de apps/v1.
-
El resource creado sería un Deployment.
-
Sería necesario tener una serie de verbs para que el recurso pueda ser creado. Podrían ser get, delete, create, etc.
Para poder configurar qué puede hacer cada usuario del clúster, tenemos que utilizar alguna de las estrategias de autorización de Kubernetes.
Autorización mediante RBAC en K8s
RBAC significa Role-based access control es un sistema que nos permite definir qué puede hacer qué y sobre qué dentro de nuestro clúster. Es la política más extendida y la recomendada por Kubernetes.
RBAC no es la única política disponible. ABAC es otra política de permisos en Kubernetes pero es más antigua y compleja, por lo que no se recomienda. No voy a explicarla, pero si alguien desea más información al respecto, podemos hacer click aquí.
La mejor forma de entender cómo funciona RBAC es mediante un ejemplo. Imaginemos que hemos creado una cuenta de servicio y hemos asignado unos permisos que le permiten hacer las siguientes acciones:
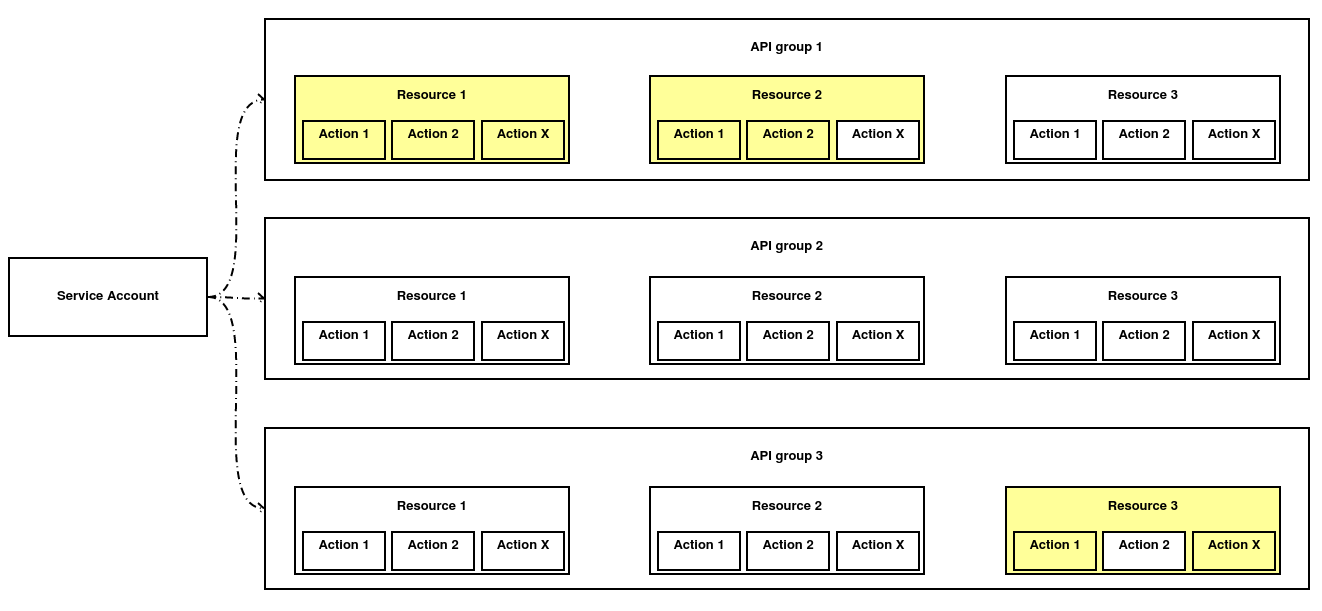
-
En el API Group 1, puede ejecutar cualquier acción en el recurso 1 y un par de acciones en el tipo de recurso 2.
-
En el API Group 2, sólo puede ejecutar una acción en un tipo de recursos concreto.
-
En el API Group 3, puede ejecutar algunas acciones en un tipo de recurso concreto.
Para utilizar RBAC, antes de nada tenemos que ver si éste se encuentra habilitado o no. Si nuestro clúster es muy antiguo, podemos ejecutar el comando kubectl api-versions | grep rbac.authorization.k8s.io/v1 y si nos devuelve algún resultado es que está habilitado.
Si no estuviese habilitado, podemos habilitarlo en en clúster ya existente, relanzando el API Server de K8s con la flag –authorization-mode=RBAC. Si utilizamos algún proveedor de nube, nos encontramos con este estado:
-
En Microsoft Azure, a día de hoy todavía no podemos habilitar RBAC en un clúster ya creado y debemos hacerlo en la creación del clúster. Si utilizamos la CLI de Azure, lo haríamos añadiendo la flag –enable-rbac al comando.
-
En AWS el servicio se lanzó habilitado por defecto.
-
En Google Cloud está habilitado por defecto desde la versión de Kubernetes 1.6. Si deseamos actualizar un clúster ya existente para que utilice RBAC debemos actualizar el clúster con la opción –no-enable-legacy-authorization.
En MicroK8s tenemos que habilitarlo con el comando microk8s.enable rbac.
microk8s.kubectl api-versions | grep rbac.authorization.k8s.io/v1
rbac.authorization.k8s.io/v1
Roles y scopes
En estos momentos ya tenemos RBAC habilitado y una cuenta de servicio asociada en nuestro kubeconfig. Vamos a activarla con kubectl config use-context ghost
Si ahora intentamos ejecutar cualquier comando, recibiremos un error:
~ kubectl get pods
Error from server (Forbidden): pods is forbidden: User "system:serviceaccount:ghost:ghost-sa" cannot list resource "pods" in API group "" in the namespace "default"
~ kubectl get pods -n ghost
Error from server (Forbidden): pods is forbidden: User "system:serviceaccount:ghost:ghost-sa" cannot list resource "pods" in API group "" in the namespace "ghost"
Estos errores demuestran que no tenemos permisos en nuestra cuenta de servicio. Para ilustrar como funciona RBAC vamos a añadirle dos permisos:
-
Un permiso global a todo el clúster que nos permita ver que pods y los logs de los mismos en cualquier namespace del clúster. Dicho permiso no va a permitir borrar, desplegar nuevos pods o ver el contenido de los secretos.
-
Un permiso específico para poder gestionar cualquier tipo de carga de trabajo en nuestro namespace, pero sin permitir que podamos borrarlos. Tampoco queremos que pueda tener permisos para modificar permisos en dicho namespace.
Antes de nada, cambiamos nuestro contexto con kubectl config use-context microk8s para volver a tener permisos.
Cada grupo de permisos que definamos en Kubernetes, tiene un alcance o scope. Si éste aplica a un único namespace, estamos generando un objeto de tipo Role y si aplica a todo el clúster, un objeto de tipo ClusterRole.
Para el permiso general, vamos a crear un fichero con el siguiente contenido:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cluster-reader
rules:
- apiGroups: [""]
resources: ["pods", "pods/log"]
verbs: ["get", "list"]
De esta forma le indicamos a Kubernetes (a través de la API de autorización rbac.authorization.k8s.io/v1), que el ClusteRole cluster-reader puede realizar las acciones (verbs) en los siguientes objetos (resources). Así definimos “el qué” puede hacer de la autorización.
NOTA: apiGroups está vacío debido a que nos estamos refiriendo a la API por defecto.
Ya hemos generado unos permisos para nuestras cuentas, pero todavía no se los hemos asignado. Para asignar un permiso general a todo el clúster debemos crear otro objeto llamado ClusterRoleBinding. Este sería el código de ejemplo:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: ghost-cluster-reader-binding
subjects:
- kind: ServiceAccount
name: ghost-sa
namespace: ghost
apiGroup: ""
roleRef:
kind: ClusterRole
name: cluster-reader
apiGroup: ""
En este ejemplo, la cuenta de servicio ghost-sa es asignado al ClusterRole de nombre cluster-reader. Así definimos “el quién” de la autorización.
Ahora procedemos a aplicar los dos ficheros para generar el permiso y asignarlo a nuestra cuenta de servicio.
kubectl apply -f clusterrole.yaml
clusterrole.rbac.authorization.k8s.io/cluster-reader created
kubectl apply -f clusterrolebinding.yaml
clusterrolebinding.rbac.authorization.k8s.io/ghost-cluster-reader-binding created
El siguiente permiso es más específico y restringido en scope. En lugar de dar permisos sobre todo el clúster vamos a hacerlo sobre un único namespace. Este tipo de objetos son similares a los anteriores, pero sin el “clúster”: Role y RoleBinding respectivamente. Éste sería su código:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: ghost-operator
namespace: ghost
rules:
- apiGroups: [""]
resources: ["pods", "pods/log"]
verbs: ["get", "watch", "list", "create", "update", "patch"]
- apiGroups: ["extensions"]
resources: ["deployments"]
verbs: ["get", "watch", "list", "create", "update", "patch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["get", "watch", "list", "create", "update", "patch"]
- apiGroups: [""]
resources: ["secrets", "configmaps", "persistentvolumeclaims"]
verbs: ["get", "watch", "list", "create", "update", "patch"]
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: ghost-operator-binding
namespace: ghost
subjects:
- kind: ServiceAccount
name: ghost-sa
namespace: ghost
apiGroup: ""
roleRef:
kind: Role
name: ghost-operator
apiGroup: ""
Una vez hayamos aplicado estos ficheros, podemos cambiar de contexto a la cuenta de ghost con kubectl config use-context ghost y verificar qué acciones podemos y cuales no podemos hacer.
NOTA: Estoy utilizando los ficheros de mi repositorio de ejemplo y el acortador de URLs Opensource Kutt para que el post quede más pequeño.
# Desplegamos un Secret y un Configmap
kubectl apply -f https://kutt.it/SPtVom -n ghost
kubectl apply -f https://kutt.it/gs7T79 -n ghost
# Desplegamos un Deployment que utiliza dichos objetos
kubectl apply -f https://kutt.it/w2VfXM -n ghost
Como podemos ver, los permisos funcionan correctamente. ¿Pero y si intentamos desplegar un StatefulSet?
kubectl apply -f https://kutt.it/GbZiMq -n ghost
statefulset.apps/nginx-with-state created
kubectl get pvc -n ghost
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-nginx-with-state-0 Pending local-storage 9s
El PVC está en Pending porque nuestro StorageClass no permite el autoaprovisionamiento de discos. Si intentamos crear el PersistentVolume veremos que no tenemos permisos y que debe crearlo alguien que si pueda.
Si intentamos crear otros objetos como Daemonsets, un Service o intentamos modificar nuestros permisos, también recibiremos un error.
# Intentamos crear un Daemonset
kubectl apply -f https://kutt.it/cJeX5g -n ghost
Error from server (Forbidden): error when retrieving current configuration of:
Resource: "apps/v1, Resource=daemonsets", GroupVersionKind: "apps/v1, Kind=DaemonSet"
Name: "fluentd", Namespace: "ghost"
from server for: "basic-fluentd-daemonset.yml": daemonsets.apps "fluentd" is forbidden: User "system:serviceaccount:ghost:ghost-sa" cannot get resource "daemonsets" in API group "apps" in the namespace "ghost"
# Intentamos crear un Service
kubectl apply -f https://kutt.it/9QAO3m -n ghost
Error from server (Forbidden): error when retrieving current configuration of:
Resource: "/v1, Resource=services", GroupVersionKind: "/v1, Kind=Service"
Name: "nginx", Namespace: "ghost"
from server for: "basic-nginx-service-nodeport.yml": services "nginx" is forbidden: User "system:serviceaccount:ghost:ghost-sa" cannot get resource "services" in API group "" in the namespace "ghost"
# Intentamos añadirnos al grupo de cluster-admins de RBAC
kubectl create clusterrolebinding ghost-cluster-admin-binding --clusterrole=cluster-admin --user=ghost-sa
Error from server (Forbidden): clusterrolebindings.rbac.authorization.k8s.io is forbidden: User "system:serviceaccount:ghost:ghost-sa" cannot create resource "clusterrolebindings" in API group "rbac.authorization.k8s.io" at the cluster scope
Por último, podemos ver que los permisos generales funcionan al listar los pods de otros namespaces como default
# Aunque no hay nada
kubectl get pods -n default
No resources found in default namespace
Conclusiones
El uso de RBAC nos abre un abanico infinito de posibilidades: podemos utilizarlo para dividir las responsabilidades en un grupo amplio de trabajo (un equipo de seguridad puede gestionar los Roles y sus asignaciones, un equipo de almacenamiento los volúmenes y otro equipo los aplicativos y los Services) o simplemente como en mis ejemplos, podemos utilizarlo para dividir las responsabilidades por aplicación y que diferentes equipos multidisciplinares trabajen sobre la misma infraestructura.
Sin embargo, sólo soluciona parte de los problemas de compartir infraestructura: nada limita que un pod de un namespace se comunique con otro pod de otro namespace y esto puede provocar problemas de seguridad, pero eso dará para otro post…
Espero que os haya gustado y… ¡os veo en el pŕoximo post!
Documentación
Revisado a 01-05-2023