Packer: migrando aplicaciones a la nube
2021-01-13 22:00¡La nube está de moda! Desde hace años, pero más desde la pandemia de COVID-19, todo el mundo quiere aprovechar sus ventajas y beneficios (pago por uso, escalabilidad, integraciones, mayor velocidad de desarrollo, etc).
Sin embargo, la forma en la que se usa la nube, puede variar mucho en función de las necesidades de cada cliente o usuario. Mientras unos apuestan por desarrollar todas sus aplicaciones futuras en ella, otros simplemente mueven aplicaciones ya desarrolladas. Por lo que me he encontrado a nivel personal, diría que la forma de uso suele estar entre esos dos extremos: con aplicaciones nuevas y aplicaciones legacy.
Considero que existen tres formas diferentes de llevar aplicaciones a la nube:
-
La primera es llamada Lift and Shift. Este modelo replica en la nube elegida, la infraestructura y la arquitectura de la aplicación legacy. Por ejemplo: si ésta se componía de tres servidores de aplicaciones, en tres máquinas virtuales y un balanceador, los creamos en nuestro proveedor y lo configuramos simulando a nuestro viejo CPD. Aunque es la forma más rápida y económica de utilizar la nube, también es la que menos permite aprovechar sus beneficios.
-
La segunda yo la llamo Mutated infrastructure. En ella se realizan pequeñas adaptaciones a la infraestructura para que ésta pueda integrarse con algunos servicios de la nube. De esta forma, nuestra aplicación puede ganar algunas ventajas como escalabilidad y resilencia. Es un proceso más lento que el primer modelo, pero aporta beneficios inmediatos a un coste relativamente bajo.
-
La tercera es Rearchitecture. Es la forma más laboriosa y requiere modificar partes del código de la aplicación para aprovechar toda la potencia de la nube. Requiere un proceso de reaquitectura de la aplicación completo, que puede ser muy costoso y por ello, no siempre se realiza.
Para los dos primeros casos, solemos partir de modelos basados en máquinas físicas o virtuales y en el tercero, se suele optar o bien por soluciones de tipo PaaS o por fragmentar dichas aplicaciones en contenedores.
Packer es una grandísima herramienta (de la que ya he hablado) para coger dichas máquinas virtuales o físicas y replicarlas en la nube, algo tremendamente útil en una migración a la nube.
En este post, vamos a simular una migración hacia la nube, realizando algunas mejoras y explicando los motivos de la misma. Manos a la obra :) .
Toma de requisitos
La fase inicial de cualquier migración, siempre es un poco más aburrida y consiste en tomar los requisitos de la aplicación y evaluar nuestro punto de partida: su infraestructura, qué características tiene, su rendimiento, su resilencia y sus dependencias.
Este primer paso es vital para el futuro, ya que si no lo realizamos bien y dejamos cabos sueltos, podemos tener problemas.
Debido a que esto es un laboratorio, voy a imaginar que hemos hablado con el responsable de la aplicación, nos ha dado su documentación y vemos obtenido los siguientes requisitos:
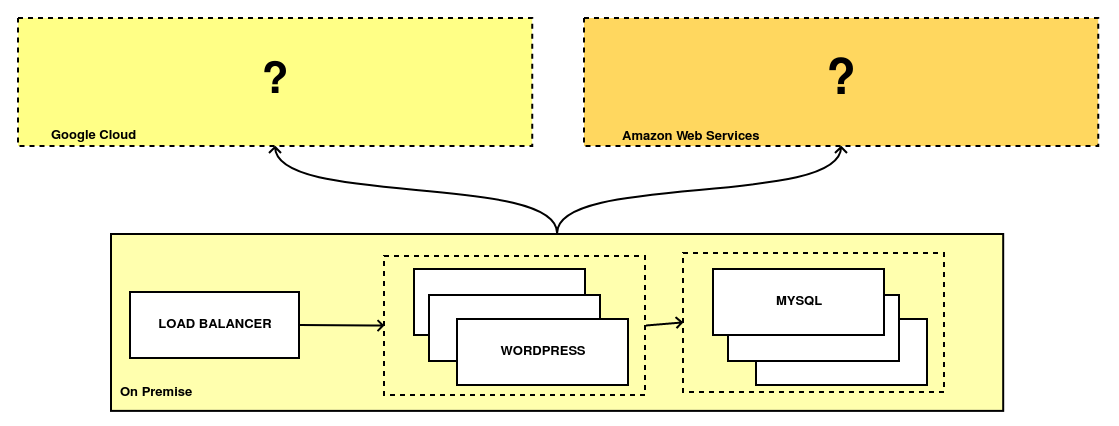
-
Su aplicación está desplegada en un pequeño CPD donde un balanceador distribuye carga entre diferentes máquinas virtuales y utiliza una base de datos en alta disponibilidad.
-
La aplicación está basada en Wordpress, un CMD de código abierto escrito en PHP. Actualmente tienen muchos problemas de escalabilidad y está en ocasiones impactando al funcionamiento de su negocio. Su infraestructura está sobredimensionada para paliar los problemas antes comentados.
-
Quieren migrar a la nube y aprovechar su elasticidad, pero sin realizar grandes inversiones, logrando reducir su coste base y sus costes de mantenimiento.
Una vez tenemos claros los requisitos y las necesidades de la aplicación, podemos ponernos manos a la obra. El siguiente paso es repensar la infraestructura, utilizando diferentes servicios de la nube para configurar la aplicación y lograr que ésta tenga un buen comportamiento.
Aunque para este laboratorio hemos utilizado Wordpress, este post puede utilizarse para casi cualquier aplicación que sea un CMS o que funciona de una forma similar a uno, con un “servidor” donde la aplicación se ejecuta, una base de datos donde se almacenan éstos y un “servidor” donde se almacenan ficheros y/o estáticos.
Migración paso a paso
Basándonos en lo que nos comenta el cliente, hemos diseñado una nueva infraestructura en la nube que consta de tres partes:
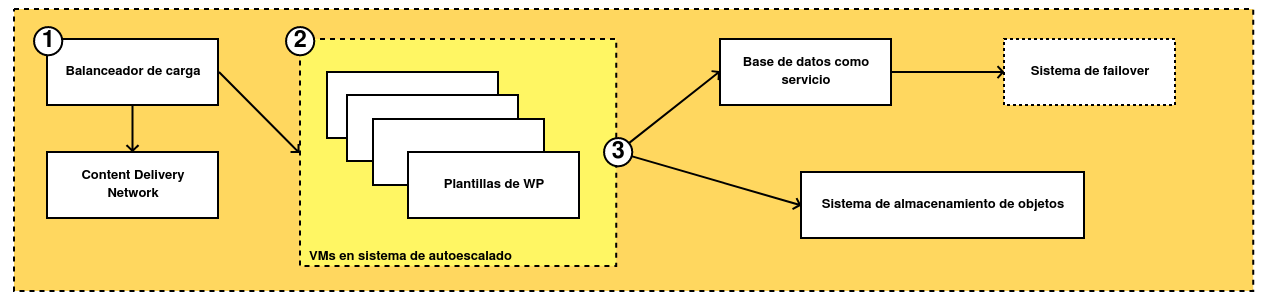
-
Los usuarios accederán a la aplicación a través de un balanceador de carga, que está conectado a un CDN que sirve los estáticos de una forma más eficiente. Así la experiencia de uso es mejor.
-
La aplicación se desplegará a través de un sistema de plantillas que generará de forma automática máquinas virtuales según la carga que tenga la aplicación. En Google Cloud será un Managed Instance Group y en AWS, un Autoscaler de EC2. En ambos casos dicha plantilla se deberá generar previamente.
-
Por último, vamos a utilizar dos sistemas de almacenamiento en la nube: por un lado tendremos una base de datos y en el otro, un sistema de almacenamiento de objetos (Google Cloud Storage o Amazon S3) donde guardaremos los ficheros del CMS.
Para crear la infraestructura, vamos a utilizar Terraform, pero la imagen base vamos a generarla utilizando Packer.
Conectando Packer a Google Cloud Platform
Para crear cualquier imagen, vamos a generar un fichero de configuración de Packer. En versiones anteriores, dichos ficheros utilizaban JSON como lenguaje, pero Packer ha continuado su evolución y desde la versión 1.5, podemos utilizar el lenguaje HCL, que es utilizado por Terraform y otras herramientas de Hashicorp.
En este post vamos directamente a generar los ficheros en el nuevo formato. Packer permite migrar el código de forma nativa utilizando el comando packer hcl2_upgrade $NOMBRE_FICHERO. A modo de ejemplo, podemos utilizar como origen uno de los ficheros del post anterior.
Ya en el nuevo formato, he dividido el código en dos ficheros: uno contiene todas las variables y es llamado variables.pkr.hcl y otro con el resto del código llamado wordpress.pkr.hcl. Así quedaría el código dedicado a Google Cloud Platform:
# Fichero de variables
variable "gcp_credentials_json" {
type = string
description = "Path to GCP JSON credentials""
}
variable "gcp_project_id" {
type = string
description = "ID of the Project in Google Cloud"
}
variable "gcp_region" {
type = string
default = "europe-west1"
description = "Default region to deploy in Google Cloud Platform"
}
variable "gcp_zone" {
type = string
default = "europe-west1-b"
description = "Default zone to deploy in Google Cloud Platform"
}
variable "image_naming" {
type = string
description = "Template name for the images created"
}
variable "username" {
type = string
default = "administrator"
description = "Default username used to customize the base machine"
}
# Fichero de configuración
# "timestamp" template function replacement
locals { timestamp = regex_replace(timestamp(), "[- TZ:]", "") }
# Sources used in Packer 1.5+
source "googlecompute" "gcp_compute_tangelov" {
account_file = var.gcp_credentials_json
image_family = var.image_naming
image_name = "${var.image_naming}-${local.timestamp}"
machine_type = "n1-standard-1"
project_id = var.gcp_project_id
source_image_family = "ubuntu-2004-lts"
ssh_username = var.username
zone = var.gcp_zone
}
# Builds used in Packer 1.5+
build {
sources = [
"source.googlecompute.gcp_compute_tangelov"
]
provisioner "shell" {
inline = ["sleep 90", "sudo apt-get update", "sudo apt-get install python3-pip -y", "sudo pip3 install ansible"]
}
# provisioner "ansible-local" {
# playbook_file = "./wordpress.yml"
# }
}
Este código actual no funcionaría sin realizar algunos pasos previos. Packer necesita tener permisos para crear la máquina virtual temporal que va a utilizar para crear la plantilla y tener conectividad a la misma. Para ello, debemos hacer lo siguiente:
-
Crear una cuenta de servicio en el proyecto de GCP donde vayamos a crear la imagen, con los permisos Compute Instance Admin (v1) y Service Account User. Para crear la cuenta y descargarnos su llave en formato JSON, podemos seguir la documentación oficial.
-
Añadir una llave SSH a los metadatos del proyecto donde vayamos a crear la imagen. De esta forma, Packer podrá conectarse y realizar todas sus tareas sin problemas. Aunque podríamos utilizar bastiones como punto de salto o algún otro sistema de autenticación, vamos a usar SSH plano para una mayor simplicidad. Para añadir la clave también podemos seguir el procedimiento estándar recogido en la documentación oficial.
Tras realizar estos pasos, ya tan sólo tenemos que definir el valor de las variables que hemos definido antes de la siguiente forma:
# Definimos las variables que nos faltan en el entorno
export PKR_VAR_gcp_credentials_json=RUTA_A_LAS_GCP_CREDENTIALS/CREDENTIAL.json
export PKR_VAR_gcp_project_id=PROYECTO_GCP
export PKR_VAR_image_naming=wordpress
Al ejecutar ahora packer build ., podríamos generar una imagen en GCP, pero todavía no tendría el código de la aplicación.
Si preferimos definir las variables en un fichero, podemos crear un fichero llamado variables.pkrvars.hcl con el siguiente contenido:
gcp_credentials_json = "RUTA_A_LAS_GCP_CREDENTIALS/CREDENTIAL.json"
gcp_project_id = "PROYECTO_GCP
image_naming = "wordpress"
Y tan sólo tendríamos que ejecutar Packer, pasándole el fichero de variables como parámetro:
packer build -var-file=variables.pkrvars.hcl .
Conectando Packer a Amazon Web Services
El código anterior, sólo conecta la herramienta con GCP y ahora vamos a proceder a generar un nuevo provider con su propia configuración:
# Sources used in Packer 1.5+
source "amazon-ebs" "aws_ec2_tangelov" {
shared_credentials_file = var.aws_credentials_file
ami_name = "${var.image_naming}-${local.timestamp}"
instance_type = "t2.micro"
iam_instance_profile = var.aws_iam_profile
source_ami_filter {
filters = {
virtualization-type = "hvm"
name = "ubuntu/images/*ubuntu-focal-20.04-amd64-server-*"
root-device-type = "ebs"
}
owners = ["099720109477"]
most_recent = true
}
security_group_ids = var.aws_security_groups
ssh_username = var.username
region = var.aws_region
}
# Builds used in Packer 1.5+
build {
sources = [
"source.amazon-ebs.aws_ec2_tangelov"
]
provisioner "shell" {
inline = ["sleep 90", "sudo apt-get update && sudo apt-get install python3-pip -y"]
}
provisioner "file" {
source = "../ansible/"
destination = "/tmp/"
}
provisioner "shell" {
script = "../ansible/launcher.sh"
}
}
# Fichero de variables
variable "aws_credentials_file" {
type = string
description = "Path to AWS credentials file"
}
variable "aws_region" {
type = string
default = "eu-west-1"
description = "Default region to deploy in Amazon Web Services"
}
variable "aws_zone" {
type = string
default = "eu-west1-1a"
description = "Default zone to deploy in Amazon Web Services"
}
variable "image_naming" {
type = string
description = "Template name for the images created"
}
variable "aws_security_groups" {
type = list(string)
description = "List of Security Groups to attach to the EC2 Instance"
}
variable "aws_iam_profile" {
type = string
description = "Name of the IAM Profile to be used to connect to S3"
}
variable "username" {
type = string
default = "ubuntu"
description = "Default username used to customize the base machine"
Si nos fijamos, las variables son ligeramente diferentes aunque usen el mismo formato. Para utilizar AWS, debemos configurar la imagen que vamos a utilizar, su owner y su versión, que obtenemos a través de un filtro de búsqueda. También definimos el usuario por defecto, que en la imagen elegida es ubuntu y algunas configuraciones de seguridad extra (como la cuenta de IAM o los Security Groups que debe utilizar).
Ansible como sistema de personalización de imágenes
Aunque Packer sea el encargado de generar las imágenes de las máquinas virtuales en los proveedores, utiliza algún sistema de gestión de la configuración para personalizarlas. De todas las herramientas soportadas por Packer, yo voy a utilizar Packer para realizar dicha configuración.
Los pasos a seguir por Ansible serían los siguientes:
-
Primero instalamos PHP y las dependencias de Wordpress.
-
Después instalamos las dependencias (si aplica) de nuestro proveedor de nube.
-
En tercer lugar instalamos (WP CLI) y sus dependencias.
-
Utilizando WP-CLI, instalamos Wordpress, los plugins y los temas que hayamos configurado.
-
Finalizamos la configuración, mejorando la seguridad de los ficheros desplegados de cara a que la imagen que vamos a crear sea segura y fiable.
Para generar toda la configuración, voy a basarme en unos playbooks que hice para uso personal y que están disponibles aquí.
El código resultante se encuentra en otro repositorio y está disponible aquí.
El contenido de la carpeta ansible de dicho repositorio contiene todo lo necesario para que Ansible instale y configure Wordpress a nuestro gusto. Para ello tan sólo tenemos que rellenar el fichero de variables localizado en (ansible/vars/vars.yml).
# PHP configuration vars
php_version: "7.4"
php_default_version_debian: "{{ php_version }}"
php_enable_webserver: false
php_use_managed_ini: false
php_enable_php_fpm: false
php_enable_env_vars: "true"
php_fpm_pool_user: "www-data"
php_fpm_pool_group: "www-data"
php_fpm_pm_max_children: "25"
php_fpm_pm_start_servers: "8"
php_fpm_pm_min_spare_servers: "8"
php_fpm_pm_max_spare_servers: "25"
# Nginx vars
nginx_user: "www-data"
nginx_group: "www-data"
# Wordpress vars
tools_folder: "{{ ansible_user_dir }}/tools"
wordpress_web_directory: "/var/www/html"
wordpress_version: "5.9.1"
wpcli_version: "2.4.0"
wordpress_mysql_database: wordpressdb
wordpress_mysql_user: wpdbuser
wordpress_mysql_user_password: wordpresspassword
wordpress_mysql_host: "127.0.0.1"
wordpress_locale: "es_ES"
wordpress_domain: "pruebamolona.ga"
wordpress_admin: "tangelov"
wordpress_admin_password: "1234567890"
wordpress_admin_email: "person@tangelov.me"
wordpress_plugins:
- "wpforms-lite"
- "wordpress-seo"
- "amazon-s3-and-cloudfront"
wordpress_themes:
- "neve"
# Google Cloud Platform only vars
cloud_sql_proxy_connection_name: gcp-tangelov-project:europe-west1:instancia-prueba
cloud_sql_proxy_tcp_port: "3306"
Estas variables son orientativas. Existen algunas variables como las contraseñas que en cualquier entorno productivo deben ser almacenadas en un Vault o en algún sistema de almacenamiento seguro. Para más información sobre cómo utilizar Ansible Vault, podemos acceder aquí
Una vez hemos configurado Ansible, sólo necesitamos modificar el código de Packer ligeramente para que utilice nuestros scripts y playbooks:
# Builds used in Packer 1.5+
# File used for Google Cloud Platform
build {
sources = [
"source.googlecompute.gcp_compute_tangelov"
]
provisioner "shell" {
inline = ["sleep 90", "sudo apt-get update && sudo apt-get install python3-pip -y"]
}
provisioner "file" {
source = "../ansible/"
destination = "/tmp/"
}
provisioner "shell" {
script = "../ansible/launcher.sh"
# Builds used in Packer 1.5+
# File used for Amazon Web Services
build {
sources = [
"source.amazon-ebs.aws_ec2_tangelov"
]
provisioner "shell" {
inline = ["sleep 90", "sudo apt-get update && sudo apt-get install python3-pip -y"]
}
provisioner "file" {
source = "../ansible/"
destination = "/tmp/"
}
provisioner "shell" {
script = "../ansible/launcher.sh"
}
}
Gracias a estos cambios, Packer ejecutará el fichero launcher.sh, ubicado en la carpeta ..ansible/ y éste lanzará automáticamente todo el proceso, desde el aprovisionamiento de la instancia temporal, pasando por la configuración de la aplicación y la generación de la imagen final.
Ya tenemos casi todo preparado para crear las imágenes que necesitamos. Ahora tan sólo nos faltaría crear una base de datos y configurar su conexión en Ansible para que el proceso se haga de forma transparente en cualquiera que sea el proveedor que hayamos elegido (GCP o AWS):
- En GCP, vamos a utilizar el proxy de Cloud SQL para conectarnos de forma segura al servicio. Dicho proxy hace que la conexión siempre sea aparentemente en local, por lo que siempre escuchará en la IP 127.0.0.1 y en un puerto local. Si ejecutamos el proceso se nos creará una imagen ya configurada que utilizaremos en el futuro:

- En AWS, es todavía más sencillo puesto que conectamos a la base de datos directamente a través endpoint privado que podemos (y debemos) generar en nuestra VPC. La única variable que deberemos cambiar es wordpress_mysql_host por el DNS del endpoint y volver a lanzar Packer:

Cuando el proceso finaliza, podremos encontrar una nueva imagen privada en nuestra cuenta de Amazon Web Services:

Si alguien quiere fácilmente todo el proceso, he generado código en Terraform para replicar todo este laboratorio de forma transparente.
Cada proveedor tiene una carpeta en dicho repositorio con dos carpetas, una llamada pre-packer que debemos ejecutar antes de lanzar packer y crea las bases de datos y buckets previos que necesitamos y otra llamada post-packer, que crea los balanceadores y todos los elementos necesarios para que podamos ejecutar dicha imagen en nuestra nube de la mejor forma posible. En la raíz de cada proveedor se encuentran los ficheros de Packer que hemos visto en este post.
Conclusión
Packer facilita muchísimo las pruebas entre diferentes nubes al convertirse en una especie de navaja suiza que nos proporciona una interfaz única para crear y configurar imágenes de cualquier proveedor de nube que soporta.
Tras el trabajo realizado en este artículo, ahora sólo tendríamos que crear el resto de la infraestructura necesaria y con muy poco trabajo podríamos tener nuestra aplicación funcionando a pleno rendimiento. También facilitaría muchísimo la migración a otros proveedores o incluso la vuelta a un CPD gracias al código realizado en Ansible.
En el siguiente post de esta serie, crearemos el resto de la infraestructura en ambos proveedores y compararemos ciertos aspectos como las arquitecturas entre una nube y otra, su coste, su complejidad y su rendimiento.
Espero que os guste y ¡nos vemos en el siguiente episodio!
Si algún lector quiere replicar el contenido de este post, que no se olvide de borrar la infraestructura creada por Terraform, así cómo las imágenes creadas tanto en GCP, como en AWS (donde debemos borrar también una snapshot) para evitar costes. En cualquier caso, si simplemente se hacen pruebas y se tienen las instancias un par de horas, no debería ser un coste superior a los dos euros.
Documentación
-
Documentación oficial de Packer a partir de la versión 1.5 (ENG)
-
Repositorio con el tutorial con el código de Ansible, Packer y Terraform (ENG)
-
Módulo de Terraform de creación de buckets en Cloud Storage (ENG)
-
Módulo de Terraform de creación de instancias de Cloud SQL (ENG)
-
Módulo de Terraform de creación de buckets en Amazon S3 (ENG)
-
Módulo de Terraform de creación de instancias de Amazon RDS (ENG)
Revisado a 01-05-2023