Kubernetes (VI): asignando recursos y autoescalado
2020-08-31 10:00Cada día utilizamos más servicios online: servicios accesibles a través de Internet que podemos operar y utilizar por nuestra cuenta, pero que forman parte de un conjunto mucho más grande.
Vamos a imaginarnos que Netflix o Spotify tuvieran que desplegar una aplicación para cada uno de sus usuarios. Sería mucho más difícil mantener y operar el servicio y haría casi imposible su escalabilidad y disponibilidad general. Tanto para ofrecer un mejor servicio como para ahorrar costes, cada plataforma digital suele funcionar como si fuese una única aplicación, dentro de la cual se nos asigna una pequeña parte de la misma y que podemos utilizar de manera independiente. Este sistema de compartición de recursos es una de las bases de la computación en la nube y recibe el nombre de Multi-tenancy.
Es un sistema que inicialmente añade complejidad al conjunto, pero que bien diseñado, puede aportar mucha robustez y ahorro a futuro.
Pese a que hay compañías que deciden desplegar una aplicación por clúster de Kubernetes para evitar complicaciones, esto puede ser muy ineficiente. Además, Kubernetes ofrece multitud de mecanismos para garantizar una buena gestión del multi-tenancy.
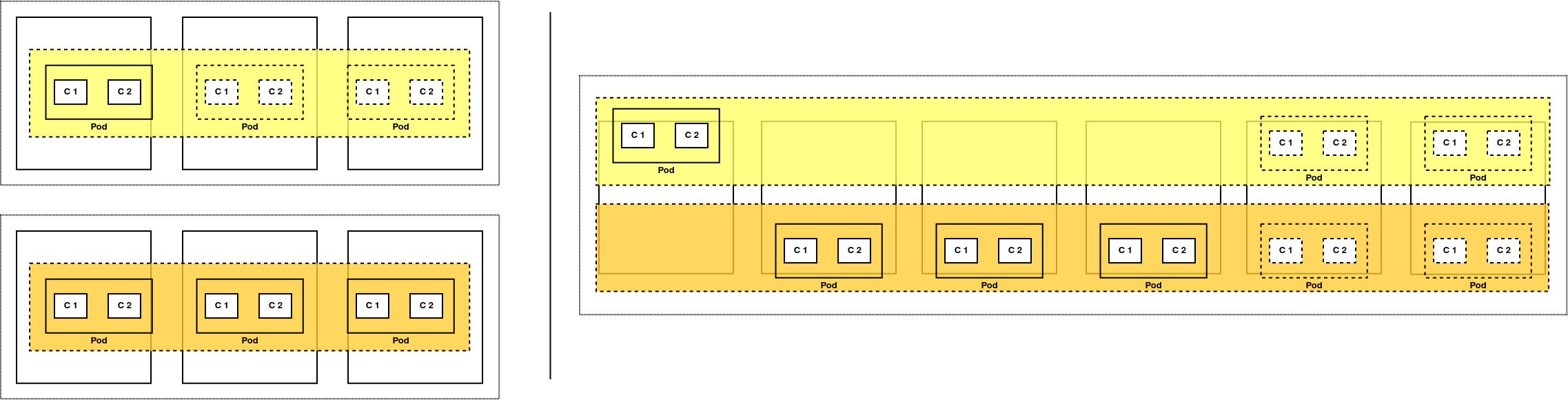
Por ejemplo: a la izquierda tenemos dos clústers separados con una aplicación cada uno. El superior tiene demasiados recursos para la carga que tiene, mientras que el inferior ya está al máximo y no puede aprovechar los recursos sobrantes del primero. A la derecha, ambas aplicaciones comparten el clúster y cualquiera de ellas puede aprovechar los recursos sobrantes si fuese necesario.
En anteriores post hemos visto como aislar pods y aplicaciones dentro del mismo clúster tanto a nivel de seguridad y permisos como a nivel de red. Hoy vamos a aprender cómo asignar y aislar los recursos computacionales que utilizan nuestras aplicaciones sobre Kubernetes.
Recursos y límites
Lo primero a tener en cuenta es que cada vez que desplegamos un Deployment en Kubernetes, podemos (y debemos) definir la cantidad de recursos que va a necesitar. Podemos definir la cantidad de recursos con los que arranca la aplicación y el límite máximo que puede utilizar.
En el siguiente ejemplo, nuestro Nginx tiene asignado por defecto 0,05 unidades de CPU y utiliza 150 MB, pudiendo crecer hasta 0,1 unidades de CPU y 300 MB de RAM. La cantidad de recursos con los que arranca un pod y el máximo que pueden acaparar se llaman respectivamente resources y limits.
Vamos a guardar el contenido de este YAML con el nombre nginx-resources.yml para utilizarlo más adelante.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: prueba
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:stable-alpine
ports:
- containerPort: 80
resources:
limits:
cpu: 100m
memory: 300Mi
requests:
cpu: 50m
memory: 150Mi
La definición de unidades de recursos, ante un hardware tan distinto como el que hay en computación, puede ser un problema. Por ello definimos cada unidad de CPU con un hilo de hyperthreading en una CPU física o un core en cualquier proveedor de nube pública.
Namespaces: recursos y límites
Asignando recursos y límites a los Deployments de nuestras aplicaciones, podemos controlar dentro de unos umbrales el consumo de nuestra aplicación. Sin embargo, los resources y los limits son valores opcionales. Sin embargo, la ausencia de estos valores tiene consecuencias: si un Deployment no tiene ningún valor en el campo limits, sus pods podrían consumir tanta CPU o memoria RAM como tengan disponible en dicho nodo e impactar en terceros. Evidentemente, éste no es un comportamiento adecuado si queremos garantizar la calidad en nuestro clúster compartido.
Para evitar que alguien despliegue una aplicación sin limits, Kubernetes posee diversos mecanismos para limitar el consumo de nuestros pods. Desde la versión 1.10, existe un tipo de objeto llamado LimitRange, que nos permite controlar las asignaciones de recursos de los pods que hayan sido desplegados en un determinado namespace. Funciona de la siguiente forma:
-
Primero creamos un LimitRange y lo asociamos an namespace.
-
Cualquier pod que despleguemos a partir de entonces en dicho namespace, tendrá unos valores por defecto heredados de los que hayamos definido en el LimitRange. Podemos utilizarlo tanto para recursos de computación como de almacenamiento.
-
Permite evitar que ciertas aplicaciones consuman demasiado. Si un usuario intenta desplegar un pod que supera los límites definidos por el LimitRange, éste no será creado y dará un error. Esta funcionalidad depende del uso de Admission Controllers y es posible que tengamos que habilitarlos.
El siguiente paso es crear nuestro primer LimitRange: queremos que los pods oscilen entre 0.3 y 0.5 de consumo de CPU y 150Mi y 300Mi de memoria RAM. Cogemos este código y lo guardamos con el nombre de limit-range.yml:
apiVersion: v1
kind: LimitRange
metadata:
name: default-cpu-memory
namespace: prueba
spec:
limits:
- default:
cpu: 0.5
memory: 300Mi
defaultRequest:
cpu: 0.3
memory: 150Mi
type: Container
Vamos a realizar algunas pruebas con los YAML que hemos creado hasta ahora. Creamos el namespace prueba y desplegamos tanto el LimitRange como el Deployment de Nginx que generamos en el punto anterior:
# Creamos el namespace
kubectl create namespace prueba
# Aplicamos el LimitRange
kubectl apply -f limit-range.yml
# Creamos el Deployment de nginx del punto anterior
kubectl apply -f nginx-resources.yml -n prueba
Debido a que nuestro Deployment tenía definidos los valores de resources/limits, éstos se mantienen, sin embargo, si borramos dichos valores del YAML y lo volvemos a desplegar, éstos tomarían el valor definido en el LimitRange.
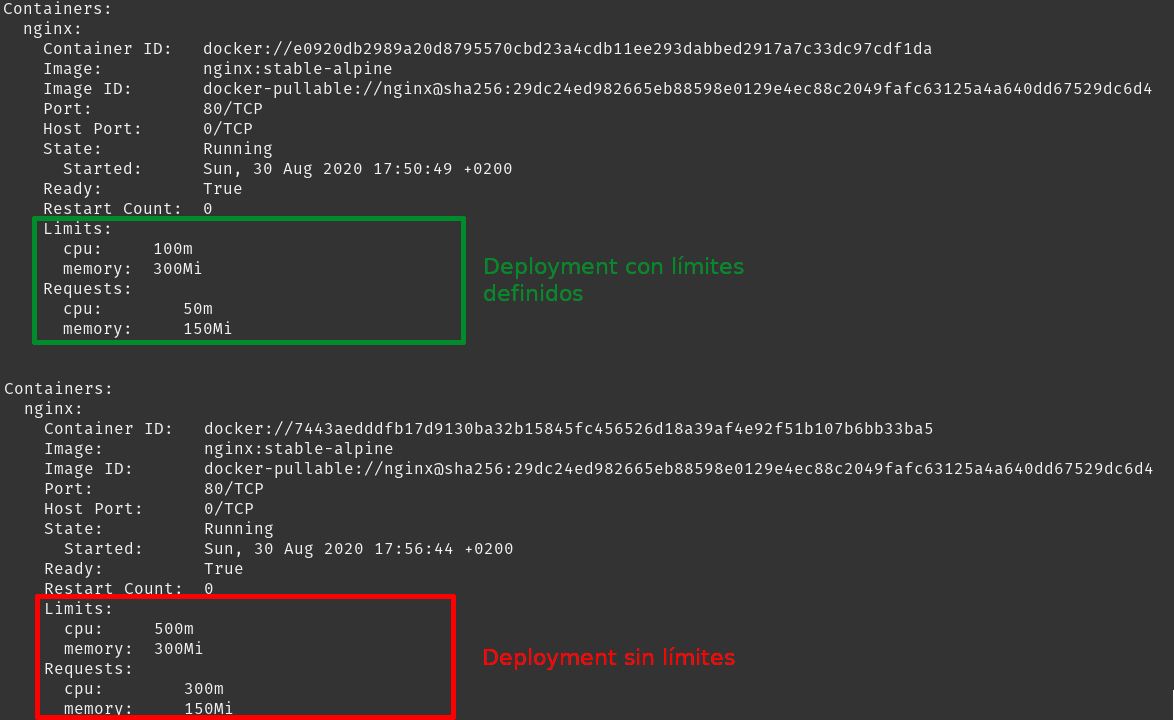
No sólo podemos definir la asignación por defecto, sino también el umbral máximo y mínimo que pueden tener todos los pods desplegados en un namespace. Modificamos el LimitRange para añadir valores máximos y mínimos:
apiVersion: v1
kind: LimitRange
metadata:
name: default-cpu-memory
namespace: prueba
spec:
limits:
- default:
cpu: 0.5
memory: 300Mi
defaultRequest:
cpu: 0.3
memory: 150Mi
max:
cpu: 0.7
min:
cpu: 0.05
type: Container
Tras aplicar el cambio, si intentamos crear un pod que tenga unos recursos superiores o inferiores a los definidos en el LimitRange, éste fallará. Para ver el fallo, debemos utilizar el comando kubectl get events -n prueba

Este comportamiento se consigue gracias al uso de Admission Controller. En este caso, el Admission Controller LimitRanger valida que nuestros pods tienen valores adecuados antes de que los pods sean ejecutados y en el caso de ser necesario, deniega su creación.
Los Admission Controller Son una serie de validadores que están imbuidos en Kubernetes y que se ejecutan tras recibir una petición autenticada y autorizada. Estas validaciones son de muchos tipos y podemos ver toda la información al respecto aquí.
Cuotas y control de recursos
Hoy en día se habla mucho de la elasticidad de la computación en la nube y del pago por uso. Es muy común utilizar Kubernetes en proveedores de nube pública que lo integran con sus servicios y que permiten ampliar la potencia de nuestros clústers en función de la demanda que tengamos. Si utilizamos Kubernetes en nuestro CPD, es posible que no sea algo tan sencillo y que tengamos que controlar un poco más cuanto consumen nuestras aplicaciones.
Hasta ahora hemos visto como definir valores por defecto o limitar el consumo por pod, pero no cómo limitar el total de recursos utilizados por aplicación. Si habilitamos algún sistema de escalado automático, una aplicación podría impactar en otras pese a tener bien definidos sus resources y limits.
Para evitar este tipo de problemas, Kubernetes puede utilizar cuotas que permiten limitar el número de recursos que puede consumir cada namespace. A través del objeto ResourceQuota, podemos limitar el número de objetos de X tipo (secrets, configmaps, pods, services, etc) o la cantidad de recursos totales asignados (CPU, memoria, almacenamiento, etc) a un namespace. Desde la versión 1.15, soporta hasta CustomResources, de los que hablaremos en siguientes posts.
En el siguiente ejemplo vamos a limitar un máximo de requests/limits de 0.7/1 para CPU y 500Mi/1Gi para memoria. Cogemos el siguiente contenido y lo guardamos en un fichero YAML de nombre resourceQuota.yml:
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-max-prueba
spec:
hard:
requests.cpu: "0.5"
requests.memory: 500Mi
limits.cpu: "1"
limits.memory: 1Gi
Antes de nada vamos a borrar todos los Deployments y los pods que ya hemos desplegado para dejar limpio el entorno y ver cómo se comporta la cuota:
# Primero borramos los despliegues que habíamos hecho antes.
# En mi caso eran nginx y nginx-2
kubectl delete deployment nginx -n prueba
kubectl delete deployment nginx-2 -n prueba
# Ahora vamos a aplicar el ResourceQuota
kubectl apply -f resourceQuota.yml -n prueba
# Podemos ver el tamaño de la cuota y cuanto está ocupado con el siguiente comando
kubectl get resourceQuota -n prueba
NAME AGE REQUEST LIMIT
mem-cpu-max-prueba 14s requests.cpu: 0/500m, requests.memory: 0/500Mi limits.cpu: 0/1, limits.memory: 0/1Gi
Una vez tenemos el entorno limpio, ya podemos desplegar de nuevo el fichero nginx-resources.yml. En dicho fichero cada pod consume 50m de CPU y 150Mi de memoria RAM. Tras realizar el despliegue podemos volver a consultar la cuota, para recibir el siguiente resultado:
# Vemos los pods de nuestro Deployment
kubectl get pods -n prueba
NAME READY STATUS RESTARTS AGE
nginx-7944c7b5df-dvb6p 1/1 Running 0 16s
nginx-7944c7b5df-jwjnc 1/1 Running 0 16s
# Vemos el estado de la cuota en el namespace de prueba
kubectl get resourceQuota -n prueba
NAME AGE REQUEST LIMIT
mem-cpu-max-prueba 83m requests.cpu: 100m/500m, requests.memory: 300Mi/500Mi limits.cpu: 200m/1, limits.memory: 600Mi/1Gi
Si ahora escalamos el servicio a cuatro pods, veremos que no todos se despliegan debido a que sobrepasan la cuota definida:
# Escalamos el Deployment a cuatro copias
kubectl scale --replicas=4 deployment/nginx -n prueba
deployment.apps/nginx scaled
# Vemos que cuatro pods no entrarían en nuestra cuota
kubectl get resourceQuota -n prueba
NAME AGE REQUEST LIMIT
mem-cpu-max-prueba 87m requests.cpu: 150m/500m, requests.memory: 450Mi/500Mi limits.cpu: 300m/1, limits.memory: 900Mi/1Gi
# El Deployment se queda con 3 de 4 pods desplegados
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 3/4 3 3 5m53s
Una vez finalizada la prueba, vamos a desescalar el despliegue otra vez a dos copias con kubectl scale --replicas=2 deployment/nginx -n prueba.
Utilizando los ResourceQuota podemos aplicar algunas restricciones a nuestro clúster: desde limitar el número de objetos creados por namespace hasta asignar automáticamente un ResourceQuota en función de la prioridad que tengan los pods de nuestra aplicación. Podemos ver ejemplos en la documentación oficial.
Ajustando recursos a la demanda
Ya sabemos cómo asignar y controlar los recursos que usan nuestras aplicaciones desplegadas en Kubernetes, ahora vamos a ver cómo hacer que nuestra aplicación se adapte automáticamente en función de sus necesidades.
Desde la versión 1.6, Kubernetes dispone de un tipo de objeto llamado Horizontal Pod Autoscaler, que permite ajustar el número de copias de una aplicación de forma automática, utilizando como base algún tipo de métrica.
Este tipo de escalado permite utilizar por defecto las mediciones de CPU y Memoria RAM que marcamos en los resources y limits para crecer y si éstos no están definidos, no funcionará correctamente.
Vamos a crear un HPA utilizando el contenido de este YAML, que guardamos con el nombre de nginx-hpa.yml:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
Voy a explicar ligeramente su contenido:
-
Utiliza la API de autoescalado v2 para soportar métricas personalizadas además de las nativas de Kubernetes (CPU y memoria).
-
Recibe el consumo de CPU de los pods del Deployment y si éste sobrepasa el 70% de la CPU (en una media de todos los pods), aumentará las copias del Deployment hasta controlarlo por debajo del umbral (hasta un máximo de 10 copias).
-
El deployment a escalar tiene de nombre Nginx y está desplegado sobre la apiVersion apps/v1.
Ahora vamos a desplegar nuestro HPA en el clúster y exponemos el Deployment para poder hacerle una pequeña prueba de carga.
# Habilitamos el Metrics Server para poder utilizar bien el HPA
minikube addons enable metrics-server
# Desplegamos el HPA en nuestro clúster
kubectl apply -f nginx-hpa.yml -n prueba
# Exponemos el servicio
kubectl expose deployment nginx --type=NodePort --name=nginx-service -n prueba
# Como estoy utilizando Minikube, obtenemos la URL del servicio fuera del clúster
minikube service list -n prueba
|-----------|---------------|-------------|-----------------------------|
| NAMESPACE | NAME | TARGET PORT | URL |
|-----------|---------------|-------------|-----------------------------|
| prueba | nginx-service | 80 | http://192.168.59.128:32549 |
|-----------|---------------|-------------|-----------------------------|
# Ahora podremos acceder al pod a través de la URL que minikube nos ha dado
Si en nuestro HPA vemos que los recursos salen en estado Unknown, tenemos un problema con el Metric server de Kubernetes y debemos solucionarlo primero. Recomendamos buscar incidencias en Github, pero es un fallo que puede producirse por muchos motivos.
Ahora que tenemos desplegado nuestro HPA, podremos realizar algunas pruebas de escalado:
# Vemos el estado de nuestro HPA en reposo
kubectl get hpa -n prueba
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 0%/70% 2 10 2 10m
# Si realizamos algo de carga podemos ver como pasa de los umbrales y comienza a escalar
ab -n 10000 -c 50 http://192.168.59.128:32549/
# Volvemos a ver el estado de nuestro HPA veremos que ha cambiad el umbral
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 122%/70% 2 10 2 11m
Nuestro Horizontal Pod Autoscaler escalará nuestro Deployment automáticamente hasta que el target quede por debajo del 70%. Debido a los límites que hemos creado antes, solo generará un máximo de 3 copias.
Aunque no voy a profundizar más en este post, si que me gustaría reseñar que podemos utilizar métricas externas a Kubernetes para escalar nuestras aplicaciones: de Prometheus, de Stackdriver o cualquier otro sistema que proporcione un sistema de métricas compatible. Si a alguien le interesa, aquí tiene algunos ejemplos:
Y ya se ha terminado el sexto post sobre Kubernetes. Espero que os guste y que sirva para entender mejor cómo gestionar con cabeza el multi-tenancy.
Documentación
-
Configurar límites de consumo para CPU y memoria por namespace (ENG)
-
Escalado horizontal de pods en Kubernetes, por Alfredo Espejel
Revisado a 01-05-2023