Terraformando funciones en Google Cloud Platform
2020-06-10 10:00El uso de funciones en la nube no es una moda pasajera y ha llegado para quedarse. Pese a sus limitaciones, tienen algunos puntos fuertes que las hacen una baza imprescindible a la hora de potenciar la automatización de la administración de la nube.
Ya escribí un post sobre funciones en el que explicaba cómo utilizo las funciones para vigilar el estado de los backups de mis servicios a coste 0 y sin tener que preocuparme por su gestión.
Hoy vamos a darle una vuelta extra a dicho post, terraformando dichas funciones e integrándolas en un sistema de CICD completo.
Llevando el código a GCP
A la hora de terraformar nuestras funciones, lo primero que tenemos que tener es nuestro código disponible y accesible desde Google Cloud. Para crear una función de 0, podemos introducir su código de tres formas: pegándolo en el editor incorporado, subiendo su código en un ZIP desde nuestro PC o Cloud Storage o bien, utilizando los repositorios de código integrados en Google Cloud. Dichos repositorios se llaman Cloud Source Repositories.
Para comenzar a terraformar las funciones, lo primero es terraformar sus repositorios. Hacerlo es bien sencillo puesto que tan sólo tenemos que indicar su nombre y el proyecto en el que se desplieguen. El nombre de de los repositorios en Google va a ser similar al que ya tienen en Gitlab para una mayor simplicidad:
# Código de ejemplo con el contenido de un repositorio en CSR
resource "google_sourcerepo_repository" "gsr-checking-drive-backups" {
name = var.csr_backups_checker_name
project = var.gcp_default_project
}
Tras aplicar los cambios, nuestros repositorios son accesibles a través de la siguiente URL. Al estar recién creados, los repositorios están vacíos y para empezar a trabajar con ellos, debemos añadir alguna forma de acceder a ellos. Abrimos en una pestaña el link Register the SSH key y nos copiamos el link del paso 2 del tutorial que podemos ver en la siguiente imagen:

El siguiente paso es llevar el código de Gitlab a Google de forma automática. La forma más sencilla de hacerlo es utilizar el sistema de Mirroring incorporado en Gitlab. Para habilitarlo nos vamos a Settings / Repository y una vez allí seleccionamos Mirroring Repositories. Tenemos que completar los siguientes campos antes de pulsar Mirror repository:
-
Git repository URL: Copiamos la url del paso 2 (lo podemos ver en la captura anterior). Tiene una estructura similar a ssh://$usuario@source.developers.google.com:2022/p/$project-id/r/$repositorio
-
Mirror direction: Seleccionamos Push y le damos al botón Detect host keys.
-
Authentication method: Seleccionamos SSH public key en lugar de password.
Para completar el proceso, copiamos la llave SSH que nos genera Gitlab (el cuadrado resaltado en rojo) y la introducimos en Google Cloud en el siguiente link:

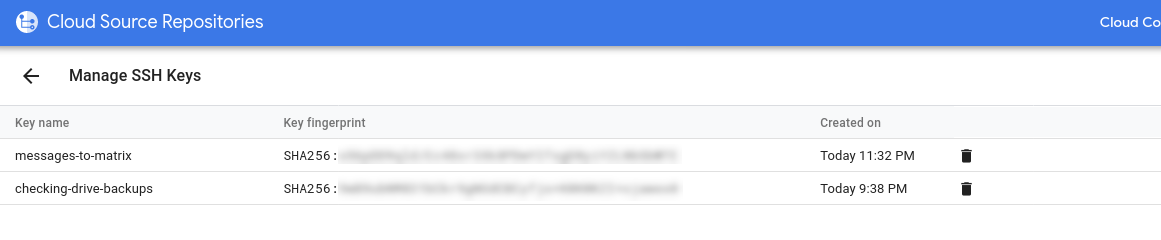
Pulsamos el botón Update now para que el código se sincronice automáticamente hacia Google Cloud:

Terraformando funciones
Tras salvar el primer obstáculo y ahora podemos empezar a picar el código de nuestas funciones en Terraform.
El código de cada una de nuestras funciones sería similar a éste:
resource "google_cloudfunctions_function" "gcp_function_checking_backups" {
name = var.cfunction_check_backup_name
description = "Function to connect to Google Drive and check the status of the backups"
runtime = "python37"
entry_point = var.cfunction_check_backup_name
region = var.gcp_default_region
source_repository {
url = "https://source.developers.google.com/projects/${var.gcp_default_project}/repos/${var.csr_backups_checker_name}/moveable-aliases/master/paths/"
}
available_memory_mb = 256
event_trigger {
event_type = "google.pubsub.topic.publish"
resource = "projects/${var.gcp_default_project}/topics/${var.orchestator_topic_name}"
failure_policy {
retry = false
}
}
labels = {
deployment-tool = "terraform"
}
environment_variables = {
"GCP_PUBSUB_TOPIC" = "projects/${var.gcp_default_project}/topics/${var.matrix_notifications_topic_name}"
"GCS_BUCKET" = var.gcp_bucket_functions_name
}
service_account_email = data.google_service_account.sa_functions.email
project = var.gcp_default_project
}
Voy a explicar algunas de las variables del código, pero si todo el código está disponible aquí:
-
runtime se corresponde con el lenguaje en el que está escrita la función.
-
source repository es el origen del código utilizado para las funciones (repositorio, rama y directorio). Google Cloud utiliza una estructura personalizada para elegir el origen (https://source.developers.google.com/projects/$id-proyecto/repos/$nombre-repo/moveable-aliases/$rama-a-usar/paths/$path-esta-la-funcion). También podemos utilizar commits o tags.
-
event trigger: podemos utilizar distintos triggers en las funciones. Para mi caso de uso, todas son ejecutadas a través de eventos de PubSub por lo que tenemos que indicarles el tipo de evento que las lanzan (al publicarse un mensaje) y el topic en el que esperarán a la aparición de los mensajes.
-
service account email: se corresponde con la cuenta de servicio que va a invocar a la función. Ésta tiene que tener los permisos adecuados, en mi caso Storage Legacy Bucker Reader y Storage Object Admin.
Y con esto ya tendríamos nuestras funciones terraformadas :) .
Pipelines
Nuestras funciones ya están plenamente codificadas, tanto el código de Python como la infraestructura en Terraform, así que podemos empezar a plantear cómo integrar dicho código en un sistema de CI/CD.
Si nos fijamos, las funciones dependen de dos repositorios distintos: el que contiene su código y el que contiene la infraestructura. ¿Cuando lanzamos el proceso de actualización de la infraestructura? ¿Al actualizar el código en Python o al modificar el código en Terraform de su infraestructura?
Bajo mi punto de vista, la respuesta correcta es en los dos. Al modificar cualquiera de los otros dos repositorios, deberíamos forzar un redespliegue de la función en el caso en el que sea necesario.
Este es el esquema de eventos que he pensado para este caso de uso:
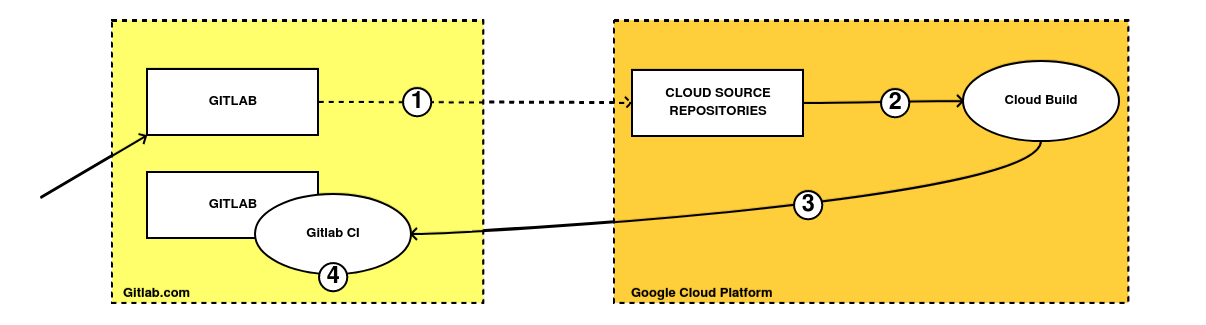
-
Subimos el código de Python de nuestra función a Gitlab. Éste se pushea de forma automática a su homólogo en los repositorios de Google utilizando el sistema de Mirroring de Gitlab.
-
Al actualizar el repositorio de CSR, un evento debería desencadenar una acción en Cloud Build.
-
Cloud Build lanza un webhook al repositorio donde se encuentra almacenado el código de la infraestructura y que lanza algún pipepline que la actualiza de forma automática.
-
Un pipeline almacenado en el repositorio de tangelov-infra, se encarga de redesplegar a través de Gitlab CI, la infraestructura mediante comandos de Terraform.
Cada caja cuadrada del esquema representa un repositorio diferente. La primera caja de Gitlab representa el repositorio del código Python de las funciones y la segunda representa el código completo de toda la infraestructura del proyecto en Terraform.
Terraform y Gitlab CI
En estos momentos tenemos generado sólo el primer punto de todo el proceso de CICD que acabamos de diseñar. Como aquí los elementos están entrelazados, necesitamos crear primero el pipeline del paso 4 antes de poder integrar las dos partes.
Conozco bastante gitlab-ci y ya he escrito anteriormente algunos artículos (I y II) al respecto, así que no voy a profundizar mucho. Aquí está el código que he generado para este caso concreto:
stages:
- validate
- plan
- apply
validate:
image:
name: hashicorp/terraform:$TF_VERSION
entrypoint:
- '/usr/bin/env'
- 'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
stage: validate
before_script:
- echo 'nameserver 1.1.1.1' > /etc/resolv.conf
- echo 'nameserver 1.0.0.1' >> /etc/resolv.conf
- cat "$GOOGLE_APPLICATION_CREDENTIALS" > $PWD/terraform.json
- terraform init
script:
- cd functions && terraform init -plugin-dir=$PLUGIN_DIR && terraform validate
variables:
PLUGIN_DIR: "../.terraform/plugins/linux_amd64"
plan:
image:
name: hashicorp/terraform:$TF_VERSION
entrypoint:
- '/usr/bin/env'
- 'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
stage: plan
before_script:
- echo 'nameserver 1.1.1.1' > /etc/resolv.conf
- echo 'nameserver 1.0.0.1' >> /etc/resolv.conf
- cat "$GOOGLE_APPLICATION_CREDENTIALS" > $PWD/terraform.json
- terraform init
script:
- cd functions && terraform init -plugin-dir=$PLUGIN_DIR && terraform plan
variables:
PLUGIN_DIR: "../.terraform/plugins/linux_amd64"
apply:
image:
name: hashicorp/terraform:$TF_VERSION
entrypoint:
- '/usr/bin/env'
- 'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
stage: apply
before_script:
- echo 'nameserver 1.1.1.1' > /etc/resolv.conf
- echo 'nameserver 1.0.0.1' >> /etc/resolv.conf
- cat "$GOOGLE_APPLICATION_CREDENTIALS" > $PWD/terraform.json
- terraform init
script:
- cd functions && terraform init -plugin-dir=$PLUGIN_DIR && terraform apply --auto-approve
variables:
PLUGIN_DIR: "../.terraform/plugins/linux_amd64"
dependencies:
- validate
rules:
- if: '$CI_COMMIT_BRANCH == "master"'
Este código tiene las siguientes peculiaridades:
-
El código del pipeline contiene tres jobs diferentes: el primero es validate, donde comprobamos la sintaxis de nuestro código, en el segundo donde podemos ver la salida de nuestros planes de Terraform y en el último llamado apply, llevamos los cambios al entorno productivo. Este último paso sólo se ejecuta en la rama master.
-
La parte de before script se corresponde con la parte de inicializar Terraform (descargar las dependencias y los backends). También he añadido una cuenta de servicio de GCP como variable y la he denominado GOOGLE APPLICATION CREDENTIALS. Los pasos de echo se corresponden con algunos bugs que me he encontrado: he tenido que modificar los DNSs de los workers donde se ejecutan los pasos del pipeline porque Terraform no podía descargarse sus dependencias (creo que algo relacionado con el hecho de que Gitlab.com esté desplegado en Google Cloud).
-
Utilizo las imágenes de Docker oficiales de Hashicorp para ejecutar Terraform. La versión de Terraform es configurable para irla adecuando a la que yo utilizo en mi ordenador. También he definido dicha variable en Gitlab (TF VERSION)
-
Cacheo los plugins de Terraform en una carpeta fija: actualmente el pipeline sólo aplica a funciones, pero lo extenderé en el futuro y para evitar que Terraform descargue continuamente sus plugins.
NOTA: El código utilizado en este post puede ser peligroso: está pensado para servir de ejemplo y bajo una mala ejecución podríamos destruir infraestructura sin querer. Para ver cómo proteger nuestra infraestructura en sistemas de CICD, podemos visitar este post.
Nuestro pipeline ya está operativo: si actualizamos el código de Terraform de nuestras funciones, también lo hará automáticamente nuestra infraestructura. Pero necesitamos una cosa más: para que los pipelines puedan ser ejecutados desde agentes externos a Gitlab (como Cloud Build), necesitamos generar un Trigger. Se habilita en en Settings / CICD en la opción de Pipeline triggers, simplemente añadiendo un nombre. También debemos guardar el token que nos aparece para guardarlo en el futuro:

Notificando a Gitlab desde CSR
Con esto ya hemos creado los pasos 1 y 4 de todo el diseño de CICD. El siguiente paso es generar la integración restante entre ambas plataformas desde Google Cloud. Para hacerlo, vamos a utilizar las funcionalidades de un servicio gestionado de GCP llamado Cloud Build.
Cloud Build es el servicio de integración continua y Continuous Deployment de Google Cloud. Su funcionamiento es similar al de otros servicios como gitlab-ci o travis-ci, pero no es un servicio que me gusta mucho. Me parece algo limitado en opciones por lo que suelo preferir alguna de sus alternativas.
Cloud Build es suficiente para las necesidades de este ejemplo. El servicio utiliza un fichero de nombre cloudbuild.yaml que debemos introducir en los repositorios de Python de cada una de las funciones. Estos son los requisitos mínimos que tiene que tener el job de Cloud Build:
-
No debe almacenar credenciales en su código puesto que el fichero va a estar subido a Git y va a ser público.
-
Debe llamar al Trigger antes generado en Gitlab y pedir que se ejecute para la rama Master del código.
Vamos a empezar a terraformar los triggers de Cloud Build para cada uno de los repositorios de Google. A modo de ejemplo, éste sería el código del trigger de una de las dos funciones:
resource "google_cloudbuild_trigger" "gcp_cb_messages_to_matrix_trigger" {
name = "${var.csr_messages_to_matrix_name}-trigger"
description = "Trigger to update functions when Messages to Matrix function is updated"
trigger_template {
branch_name = "^master$"
repo_name = google_sourcerepo_repository.gsr-messages-to-matrix.name
}
filename = "cloudbuild.yaml"
substitutions = {
_GITLAB_TOKEN = var.cb_gitlab_token_variable
_GITLAB_PROJECT = var.cb_gitlab_project_variable
}
project = var.gcp_default_project
}
El trigger funciona así:
-
Detecta los cambios realizados en la rama master y en caso afirmativo, aplica lo que hayamos definido en el fichero cloudbuild.yaml.
-
Cloud Build soporta el uso de secretos, pero requiere el uso de Cloud KMS que no entra dentro de tier gratuito de GCP. Para no guardar los secretos en código, vamos a almacenar las variables en Terraform y éstas serán sustituidas automáticamente por Cloud Build.
En este modelo, las variables son accesibles a través de la consola de Google Cloud si se tienen los permisos adecuados, pero no se loguean en Cloud Build.
Tras crear los triggers para los repositorios de las funciones, ahora tenemos que definir los pasos necesarios para que Cloud Build le diga a Gitlab que lance los pipelines. Para ello, tan sólo tenemos que hacer una llamada muy simple a la API a través de curl o alguna herramienta equivalente.
El encargado de ejecutar cada paso en Cloud Build es llamado Cloud Builder y son contenedores preparados por la comunidad o Google para realizar algunas acciones. En nuestro caso, tan sólo tenemos que definir lo siguiente en el fichero cloudbuild.yaml
steps:
- name: 'gcr.io/cloud-builders/curl'
args:
[
'-X',
'POST',
'-F',
'token=${_GITLAB_TOKEN}',
'-F',
'ref=master',
'https://gitlab.com/api/v4/projects/${_GITLAB_PROJECT}/trigger/pipeline'
]
En dicho código, le estamos diciendo a Cloud Build lo siguiente:
-
Debes utilizar el builder de curl para ejecutar la acción.
-
La acción que vas a ejecutar es un POST a Gitlab donde le indicamos el token de acceso, la rama sobre la que lanzarla y el endpoint de pipelines de nuestro proyecto (o repositorio) de Gitlab.
Con estos últimos retoques, ya hemos terminado todos los pasos del pipeline. Si ahora modificamos el código de alguna de nuestas funciones en Gitlab, se lanzará un proceso que no sólo actualizará el código Python sino que también la redesplegará con dicho código en la nube. Voy a realizar un cambio para que veamos el proceso completo:
Al subir el código a Gitlab, lo primero que veríamos es cómo el proceso de mirroring se ha ejecutado, enviando el código de Gitlab a los Cloud Source Repositories.
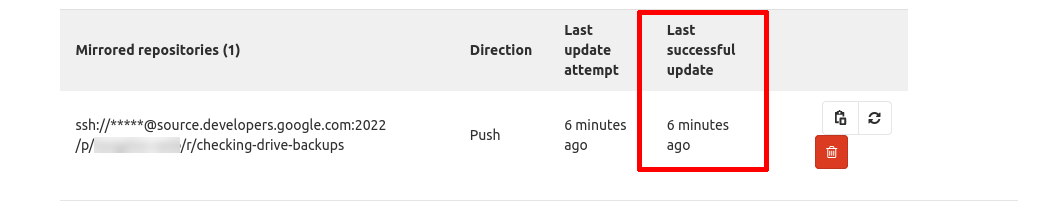
Una vez el código ha llegado a CSR, veríamos cómo saltan los triggers al recibir el código en la rama master:

Por último, si volvemos a Gitlab podemos ver cómo se ha ejecutado Terraform y se han aplicado los cambios en la infraestrutura de forma automática. Este último paso también se ejecutaría si modificamos el código del repositorio de Terraform igualmente.
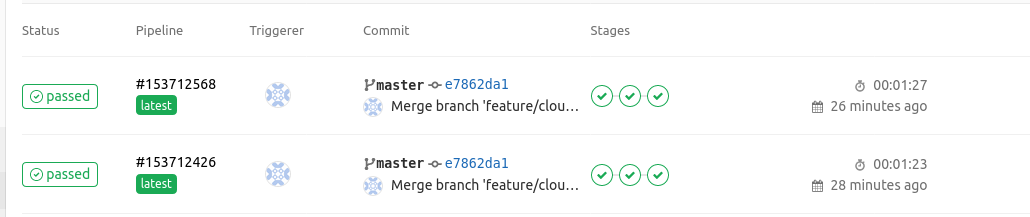
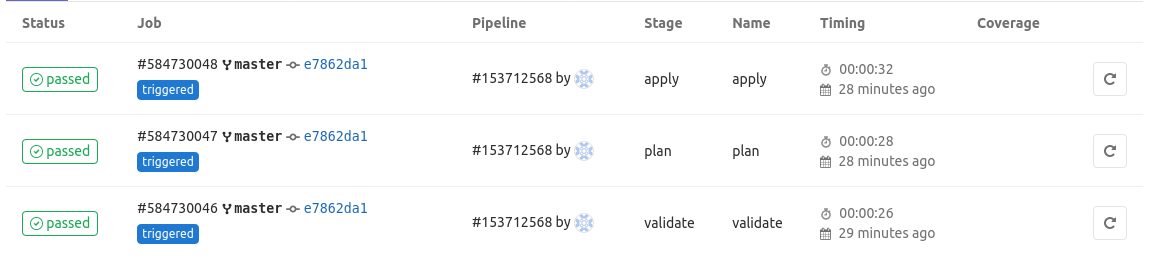
Y ya tendríamos el proceso completo. En el futuro mejoraré el pipeline para que soporte todos los elementos, añadirle tests más complejos y haré alguna refactorización que he visto para adaptarse mejor a estas automatizaciones. Espero que os guste y nos vemos en el siguiente post.
Documentación
-
Cómo clonar un repositorio de Gitlab a Google Cloud Source Repositories (ENG)
-
Mejorando la sintáxis de las configuraciones de Google Cloud Build (ENG)
-
Referencias sobre cómo utilizar Terraform con Gitlab CI (ENG): I y II
Revisado a 01-05-2023