Terraform y OPA: el dúo perfecto para automatizar nuestra infraestructura
2021-02-16 18:00Aunque 2020 ha sido un año muy duro en términos sociales, la verdad es que yo he tenido suerte: ni yo ni nadie cercano ha cogido la COVID-19 (toquemos madera), he podido continuar realizando mi trabajo con relativa normalidad y, además he podido profundizar más en algunos de los aspectos de mi carrera profesional.
Uno de estos aspectos ha sido la infraestructura como código. Terraform es una herramienta muy útil y potente, pero como ya sabemos: un gran poder conlleva una gran responsabilidad. Al igual que nos permite crear infraestructuras muy complejas rápidamente, también permita meter la pata de forma estrepitosa si no tomamos las debidas precauciones. Un terraform apply desafortunado puede eliminar toda la infraestructura desplegada y los datos de la aplicación en ella contenida.
En este post vamos a mostrar como evitar este tipo de problemas, refactorizando el código de Terraform actual utilizado en tangelov.me y a crear un proceso automático y un sistema de tests que asegure que la aplicación de cualquier cambio sea segura, incluso en entornos productivos.
Reorganizando la infraestructura
Esta web tiene una infraestructura relativamente sencilla: apenas la forman un par de buckets, una instancia de App Engine, varios Datasets de BigQuery, varias Cloud Functions y un par de cuentas y permisos en IAM. A groso modo, sigue siendo lo mismo que ya describí en este post.
Si clonamos su repositorio, nos encontraremos con una estructura de carpetas similar a ésta:
.
├── appengine
├── bigquery
├── cloud-storage
├── functions
├── iam
└── pubsub
Cada carpeta se corresponde con un tipo de recurso y sus dependencias. Así controlamos la granularidad de los despliegues, pero a cambio se vuelve más engorroso desplegar toda la infraestructura de forma completa puesto que obliga a ejecutar terraform carpeta por carpeta.
Al automatizar un despliegue, el problema se repite: el pipeline terraformaría nuestros recursos carpeta por carpeta hasta alinear la infraestructura y nuestro código. Para solucionar esta cuestión, fruto de una decisión tomada hace un par de años, podemos optar por alguna de las siguientes soluciones: podemos generar un script que vaya entrando carpeta por carpeta y mantenerlo, o bien simplificar las divisiones de nuestro código para simplificar el proceso
Aunque cualquiera es totalmente válida, prefiero agrupar todo el código actual en una carpeta única llamada gcp. Pretendo simplificar el código de cada proveedor y añadir a futuro otros proveedores que sean tratados de forma independiente (cada uno con sus propios tests y credenciales).
Unificando el código en Terraform
El sistema actual por carpetas no sólo contiene los recursos y sus dependencias, sino que también posee un fichero de estado propio (tfstate). Nuestro primer reto es mover todos los recursos disperdigados en distintos tfstates a uno conjunto y después adaptar nuestro código sin romper nada durante el proceso.
Antes de comenzar, vamos a descargar todos los tfstates y a guardar una copia en otro lugar, para en el caso de ser necesario poder dar marcha atrás fácilmente si metemos la pata.
# Definimos el bucket donde tenemos nuestro tfstate desplegado
export GCS_BUCKET="mi-bucket-privado"
gsutil -m cp -r \
"gs://$GCS_BUCKET/appengine/" \
"gs://$GCS_BUCKET/bigquery/" \
"gs://$GCS_BUCKET/cloud-storage/" \
"gs://$GCS_BUCKET/functions/" \
"gs://$GCS_BUCKET/iam/" \
"gs://$GCS_BUCKET/pubsub/" \
.
Ahora creamos una carpeta en la raíz del repositorio de nombre gcp, donde vamos a ir agrupando todo el código ya unificado. También va a ser el nombre que va a tener la clave del tfstate en el remoto de Google Cloud Storage.
Tras realizar estos pasos previos, podemos empezar a mover los recursos de un tfstate a otro. Primero vamos a acceder a una de las carpetas del repositorio (en este caso appengine) y a listar todos los recursos de su tfstate:
# Primero vemos todos los recursos guardados en el tfstate con el siguiente comando
terraform state list
# Por ejemplo en la carpeta de appengine veremos algo similar a lo siguiente
google_app_engine_application.app_engine
Cuando ejecutamos terraform state list, se muestran por pantalla todos los recursos cuyo estado se encuentra en dicho tsfstate. Una vez tenemos la lista, ahora podemos moverlos de un tfstate a otro, simplemente utilizando Terraform y teniendo cuidado.
Recurso a recurso, tenemos que ejecutar el comando terraform state mv -state-out=$1 $2 $3 pasándole como parámetros la ruta local del nuevo tfsate ($1), el nombre del recurso en el antiguo tfsate ($2) y el nuevo nombre que queramos que tenga dicho recurso en el nuevo ($3).A modo de ejemplo, si quisieramos mover la aplicación de App Engine, haríamos lo siguiente:
# El comando funciona de la siguiente manera: le indicamos el fichero local donde vamos
# a guardar el estado, el nombre en origen del recurso y el nombre del recurso que queramos
# que tenga en el nuevo tfstate destino
#
# Si quisieramos mover el recurso anterior, tendríamos que ejecutar el siguiente comando:
terraform state mv -state-out=../gcp/default.tfstate google_app_engine_application.app_engine google_app_engine_application.app_engine
Move "google_app_engine_application.app_engine" to "google_app_engine_application.app_engine"
Successfully moved 1 object(s).
Al migrar cualquier recurso, se habrá creado en la carpeta local gcp un fichero llamado default.tfstate donde está almacenado el estado del recurso o recursos que hayamos movido.
Carpeta por carpeta, vamos moviendo uno a uno todos los recursos y los data hasta finalizarlos todos. Terraform valida el proceso y si por algún casual intentáramos mover un recurso ya existente, recibiríamos un error como el siguiente:
Error: Invalid target address
Cannot move to data.google_project.tangelov_project: there is already a
resource instance at that address in the current state
Una vez hayamos movido todos los recursos al nuevo tfstate, ahora debemos agrupar el código de todos los ficheros .tf de todas las carpetas a su nuevo destino. Tenemos que copiarlo todo: los ficheros de variables, de recursos, los de fuentes de datos, así cómo los de configuración de Terraform (provider, versions, etc). Para facilitar el proceso, adjunto el código de un script que automatiza los pasos:
# Ejecutamos estos comandos desde la raíz del repositorio
# Primero movemos los ficheros comunes de Terraform
cp provider.tf gcp/provider.tf
cp vars.tf gcp/vars.tf
cp appengine/versions.tf gcp/versions.tf
# Movemos los ficheros de la carpeta appengine
cp appengine/main.tf gcp/appengine.tf
cat appengine/vars.tf >> gcp/vars.tf
# Movemos los ficheros de la carpeta bigquery
cp bigquery/main.tf gcp/bigquery.tf
cat bigquery/data.tf >> gcp/data.tf
cat bigquery/vars.tf >> gcp/vars.tf
# Movemos los ficheros de la carpeta cloud-storage
cp cloud-storage/main.tf gcp/cloud-storage.tf
cat cloud-storage/data.tf >> gcp/data.tf
cat cloud-storage/vars.tf >> gcp/vars.tf
# Movemos los ficheros de la carpeta functions
cp functions/main.tf gcp/functions.tf
cat functions/data.tf >> gcp/data.tf
cat functions/vars.tf >> gcp/vars.tf
# Movemos los ficheros de la carpeta iam
cp iam/main.tf gcp/iam.tf
cat iam/data.tf >> gcp/data.tf
cat iam/vars.tf >> gcp/vars.tf
# Movemos los ficheros de la carpeta de pubsub
cp pubsub/main.tf gcp/pubsub.tf
cat pubsub/data.tf >> gcp/data.tf
cat pubsub/vars.tf >> gcp/vars.tf
Tras mover los ficheros, la migración casi está completa. Tan sólo debemos limpiar algunos data sources y variables duplicados en los ficheros gcp/data.tf y gcp/vars.tf y crear un nuevo fichero remote_state.tf dentro de la carpeta gcp:
# Este es el código de ejemplo que debemos utilizar para crear el nuevo remote_state.tf
# No olvidemos sustituir el nombre del bucket de la plantilla
terraform {
backend "gcs" {
bucket = "$NOMBRE_DEL_BUCKET"
prefix = "gcp"
}
}
Ahora ya sí que hemos terminado. Nuestro último paso es subir el estado de Terraform que tenemos en local a Cloud Storage y ejecutar terraform plan. Si todo ha ido bien, la salida del comando debería de salir limpia:
# Primero inicializamos terraform
terraform init
# Segundo pusheamos el estado a su lugar remoto en un bucket
terraform state push
# Tercero comprobamos que está todo OK y bien importado
terraform plan
No changes. Infrastructure is up-to-date.
This means that Terraform did not detect any differences between your
configuration and real physical resources that exist. As a result, no
actions need to be performed.
Llegamos a este punto, si se tiene algún sistema de CICD, recomiendo su desactivación temporal para evitar posibles cambios no deseados hasta que hayamos adaptado el pipeline al nuevo código.
En el código final, he cambiado además algunas referencias no necesarias puesto que ahora algunos data sources sobran y añadido algunas dependencias al código para aportarle una mayor robustez.
Protegiendo recursos en Terraform
La finalidad de este post es crear un pipeline completamente funcional, que a través de Gitlab CI, permita desplegar de forma automática y segura nuestra infraestructura.
En el estado actual, una mala ejecución de Terraform sin supervisión humana puede romper nuestra aplicación y hacernos perder todos nuestros datos. ¿Acaso no posee Terraform alguna funcionalidad para asegurar que esto no pase? La respuesta es SI y es mediante el uso de meta-argumentos.
A través de dichos meta-argumentos, Terraform permite gestionar la creación y destrucción de los recursos. Gracias a ellas podemos modificar ciertos comportamientos por defectos, ignorar los cambios de algunos cambios, cambiar cómo se destruyen los recursos o simplemente bloquear la destrucción de algún recurso.
La instancia de Google App Engine y el bucket donde se almacenan las imágenes y videos de la web son los recursos más importantes de toda la infraestructura. Vamos a protegerlos añadiendo un fragmento de código llamado lifecycle, donde se configuran las directivas antes comentadas. El código final quedaría de la siguiente manera:
# Estado actual del código de GAE
resource "google_app_engine_application" "app_engine" {
project = var.gcp_default_project
location_id = var.gcp_app_engine_location
lifecycle {
prevent_destroy = true
}
}
# Estado actual del código del bucket de imágenes
resource "google_storage_bucket" "gcp_bucket_images" {
name = var.gcp_bucket_images_name
location = var.gcp_default_region
storage_class = var.gcp_bucket_images_storage_class
project = var.gcp_default_project
lifecycle {
prevent_destroy = true
}
}
Si ahora intentásemos borrar cualquiera de ellos, recibiríamos un error similar al anterior:
terraform destroy --target=google_storage_bucket.gcp_bucket_images
Error: Instance cannot be destroyed
on cloud-storage.tf line 14:
14: resource "google_storage_bucket" "gcp_bucket_images" {
Resource google_storage_bucket.gcp_bucket_testing_delete has
lifecycle.prevent_destroy set, but the plan calls for this resource to be
destroyed. To avoid this error and continue with the plan, either disable
lifecycle.prevent_destroy or reduce the scope of the plan using the -target
flag.
Sin embargo, esta protección es muy limitada, más centrada en evitar posibles pérdidas de datos al reemplazar un recurso (destruirlo y volverlo a crear) que en evitar meteduras de pata humanas. Por ejemplo, si alguien borrara el código de uno de los dos recursos protegidos, Terraform no pondría pegas a la hora de borrarlo y por ello, es necesario implementar medidas de protección complementarias que verifiquen el proceso automáticamente. Y aquí es donde entra en juego OPA.
Análisis estático con Open Policy Agent
OPA u Open Policy Agent es un motor de políticas para implementar un sistema de gobierno y validaciones a través de código, desarrollado por la compañía norteamericana Styra. OPA permite la creación de políticas que realizan ciertas comprobaciones en ficheros estructurados (como YAML o JSON) y validar algunos comportamientos. Dichas políticas se escriben en un lenguaje de alto nivel creado para la ocasión, llamado Rego.
OPA fue ideado para funcionar como una navaja suiza que funcionara para cualquier tipo de política en entornos Cloud Native y se integra con una cantidad inmensa de tecnologías. Podemos utilizar OPA para verificar los grupos a los que pertenece un usuario, para validar reglas de autorización y/o autorización o para verificar que se siguen ciertas reglas de compliance (algunas políticas de nombres, validar características como la región de un recurso, etc).
El funcionamiento de OPA es el siguiente:
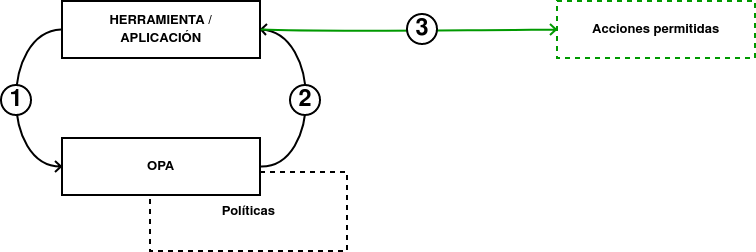
-
Una herramienta o una aplicación genera una salida en un lenguaje estructurado (normalmente JSON) y se lo envía a Open Policy Agent.
-
Open Policy Agent valida la entrada recibida con las políticas que hayamos definido y responde a la herramienta o aplicación inicial si la acción debe ser permitida o no.
-
Si se cumplen los tests escritos en Rego, el proceso continúa de manera normal. En el caso contrario, se muestra un error.
Open Policy Agent puede integrarse de diferentes formas:
-
En Kubernetes podemos instalar un Admission Controller llamado OPA Gatekeeper, que es el encargado de denegar o permitir las operaciones enviadas a nuestro clúster. Por ejemplo, podemos validar que los recursos tengan una serie de etiquetas o que todos nuestros discos sean de tipo SSD.
-
También posee una CLI para integrar OPA en procesos de CICD, llamada conftest y que es la que vamos a utilizar para validar nuestro código de Terraform.
-
Soporta el uso de WebAssembly si tenemos conocimientos de Javascript.
-
Más formas disponibles en la documentación oficial de la herramienta.
No voy a hablar mucho sobre Rego en este post puesto que lo haría mucho más largo y debido a la complejidad del lenguaje, recomiendo ir directamente al curso de la academia de Styra si se tienen dudas (es gratis y está disponible en la documentación). A futuro, hablaré más de este tema.
Integrando Terraform con Open Policy Agent
Como ya hemos comentado vamos a utilizar conftest para validar nuestro código de Terraform en un proceso de CICD. El que vamos a implementar en nuestro pipeline es el siguiente:
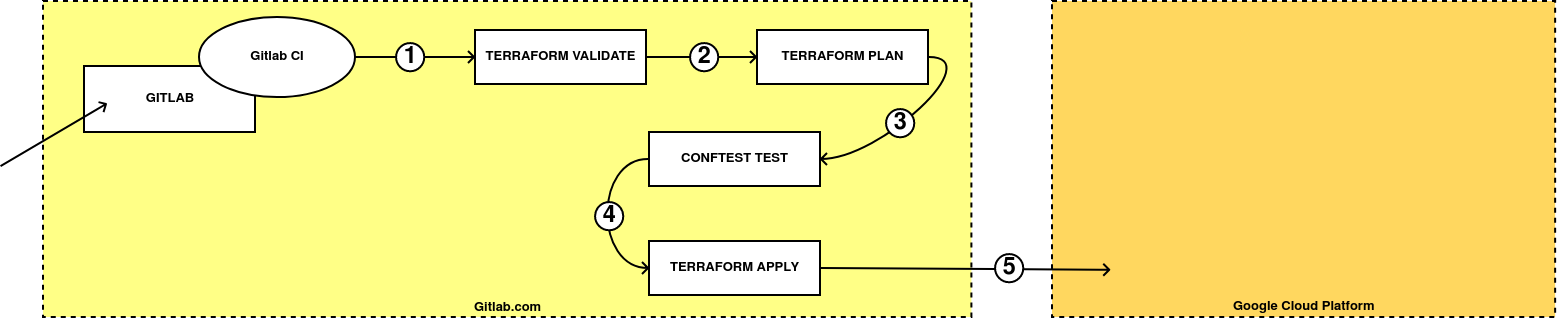
-
Cuando realicemos un cambio en el repositorio, se lanzará automáticamente un terraform validate que comprobará si el código es mínimamente correcto.
-
El siguiente paso será generar un plan en Terraform y exportarlo a un fichero. Por defecto, estos planes se generan en un formato binario, pero se pueden transformar a JSON.
-
Una vez hemos transformado el plan a formato JSON, se lo pasamos a conftest para que valide contra las políticas que hayamos definido (que ningún elemento es destruido o reemplazado de forma automática).
-
Si se cumplen todas las políticas, continuamos con el pipeline y ejecutamos terraform apply sobre el plan antes generado.
-
Gitlab CI aplicará los cambios de forma automática en el proveedor elegido, sólo cuando mergeamos el contenido a master.
Para conseguir los pasos 2, 3 y 4 necesitamos hacer algunos cambios en nuestro pipeline.
Primero tenemos que añadir el fichero remote_state.tf_ como un fichero dentro de los pipelines. Este fichero se encuentra fuera de git y le indica a Terraform la ubicación remota del tfstate. Al añadirlo al pipeline, Terraform podrá leerlo y generar los ficheros de los planes que necesitamos.
También necesitamos añadir una variable llamada CT_VERSION con la versión de Conftest que vamos a utilizar en el pipeline.
El siguiente paso es modificar el job de plan para que éste genere los ficheros de _plan con los nombres tangelov.plan (en formato binario) y tangelov-tfplan.json (en formato JSON). Para generar dichos ficheros tenemos que añadir los siguientes comandos:
terraform plan -out tangelov.plan && terraform show -json tangelov.plan > tangelov-tfplan.json
Los ficheros se generan dentro de un job de Gitlab CI y ahora debemos pasar dichos ficheros a otros jobs. Para ello, tenemos que definir una entrada llamda artifacts y configurar un tiempo de expiración para los mismos.
artifacts:
paths:
- gcp/tangelov-tfplan.json
- gcp/tangelov.plan
expire_in: 5 mins
Una vez hemos creado los ficheros de plan, vamos a crear un nuevo job que utilizando la imagen oficial de conftest, verifiquemos que se cumplen todas nuestras políticas. En este caso sólo verificamos que ningún elemento sea destruido o recreado durante el despliegue.
conftest:
image:
name: openpolicyagent/conftest:$CT_VERSION
entrypoint:
- ""
stage: conformance
before_script:
- conftest --version
script:
- conftest test --all-namespaces gcp/tangelov-tfplan.json
dependencies:
- validate
- plan
Para pasar los artefactos entre los jobs, tenemos que poner los pasos dentro de dependencies. De esta forma podremos acceder a dichos artefactos en varios pasos del pipeline. Si ahora hacemos un cambio e intentamos borrar algún objeto, veríamos cómo la ejecución es interrumpida con un error:

Para finalizar vamos a añadir un último paso que aplique el plan antes generado y sólo cuando se ejecute sobre la rama master.
apply:
image:
name: hashicorp/terraform:$TF_VERSION
entrypoint:
- '/usr/bin/env'
- 'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
stage: apply
before_script:
- echo 'nameserver 1.1.1.1' > /etc/resolv.conf
- echo 'nameserver 1.0.0.1' >> /etc/resolv.conf
- cat "$GOOGLE_APPLICATION_CREDENTIALS" > $PWD/terraform.json
- cat "$GCP_TFSTATE" > $PWD/gcp/remote_state.tf
script:
- cd gcp && terraform init && terraform apply -input=false "tangelov.plan"
dependencies:
- conftest
- plan
rules:
- if: '$CI_COMMIT_BRANCH == "master"'
Para ver el fichero completo, podemos hacer click aquí.
Limpieza y conclusiones
Aunque nuestro código ya es funcional, también es muy ineficiente. Ciertos pasos se repiten constantemente y deberíamos simplificar el proceso y utilizar algún sistema de cacheos.
Para evitar el código duplicado en los pasos de Terraform, vamos a utilizar el sistema de plantillas de Gitlab CI. Para crear una plantilla creamos una entrada con el siguiente contenido:
.tftemplate:
image:
name: hashicorp/terraform:$TF_VERSION
entrypoint:
- '/usr/bin/env'
- 'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
before_script:
- echo 'nameserver 1.1.1.1' > /etc/resolv.conf
- echo 'nameserver 1.0.0.1' >> /etc/resolv.conf
- cat "$GOOGLE_APPLICATION_CREDENTIALS" > $PWD/terraform.json
- cat "$GCP_TFSTATE" > $PWD/gcp/remote_state.tf
cache:
key: terraform
paths:
- $PWD/gcp/.terraform
El código funciona de la siguiente manera:
-
Se crea una plantilla de nombre .tftemplate que contiene la imagen de Docker que vamos a utilizar, su entrypoint y los pasos necesarios para asegurar que el pipeline funciona bien dentro de gitlab.com.
-
Se define una caché de nombre Terraform que permite reutilizar la carpeta localizada en $PWD/gcp/.terraform entre los diferentes pasos. Esto nos permite ahorrar descargar los proveedores y módulos en cada paso y evitar hacer un Terraform init en cada uno de ellos.
Ahora podemos extender esta plantilla desde cualquier paso de Terraform, quedando el fichero gitlab-ci.yml de la siguiente manera:
stages:
- validate
- plan
- conformance
- apply
.tftemplate:
image:
name: hashicorp/terraform:$TF_VERSION
entrypoint:
- '/usr/bin/env'
- 'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
before_script:
- echo 'nameserver 1.1.1.1' > /etc/resolv.conf
- echo 'nameserver 1.0.0.1' >> /etc/resolv.conf
- cat "$GOOGLE_APPLICATION_CREDENTIALS" > $PWD/terraform.json
- cat "$GCP_TFSTATE" > $PWD/gcp/remote_state.tf
cache:
key: terraform
paths:
- $PWD/gcp/.terraform
validate:
extends: .tftemplate
stage: validate
script:
- cd gcp && terraform init && terraform validate
plan:
extends: .tftemplate
stage: plan
script:
- cd gcp && terraform plan -out tangelov.plan && terraform show -json tangelov.plan > tangelov-tfplan.json
artifacts:
paths:
- gcp/tangelov-tfplan.json
- gcp/tangelov.plan
expire_in: 5 mins
dependencies:
- validate
conftest:
image:
name: openpolicyagent/conftest:$CT_VERSION
entrypoint:
- ""
stage: conformance
before_script:
- conftest --version
script:
- conftest test --all-namespaces gcp/tangelov-tfplan.json
cache:
key: terraform
dependencies:
- validate
- plan
apply:
extends: .tftemplate
stage: apply
script:
- cd gcp && terraform apply -input=false "tangelov.plan"
dependencies:
- conftest
- plan
rules:
- if: '$CI_COMMIT_BRANCH == "master"'
Y ya tendríamos el pipeline completo y optimizado. Los siguientes pasos serán aumentar el número de tests sobre OPA, pero todo eso lo veremos en el siguiente post. ¡Hasta la vista!
Documentación
-
Gestión del ciclo de vida de los recursos en Terraform (ENG)
-
Representación en JSON de diferentes outputs de Terraform (ENG)
Revisado a 01-05-2023