Terraform 0.14 y Data Studio
2021-01-19 19:00Cuando decidí comenzar este blog, me puse algunas algunas lineas rojas a la hora de gestionarlo y evolucionarlo. Una se basaba en el respeto a los usuarios, evitando el uso de sistemas de tracking como Google Analytics y obteniendo datos sólo de las peticiones recogidas por los servicios que utilizo en Google Cloud.
Los únicos datos en mi mano son los que dejan las peticiones de los visitantes en el balanceador que tiene incorporado Google App Engine. Gracias a ellos, pude crear un par de informes en Google Data Studio, una herramienta gratuita de visualización de datos, que permite hacer unos informes bastante vistosos y que me permitieron conocer al menos qué posts eran los más visitados.
En aquel momento, mi conocimiento de Data Studio era casi nulo así que el resultado de dicha prueba fue bastante mediocre. A día de hoy, esto ha cambiado y dominio tanto Data Studio como BigQuery con bastante soltura, por lo que decidí darle una vuelta de tuerca y hacer un nuevo panel en condiciones.
En este post, vamos a hablar de toda la infraestructura creada para poder generar dichos paneles, cómo adaptar nuestro código a la versión 0.14 de Terraform y cómo explotar los datos desde Data Studio de forma sencilla.
Actualizando Terraform 0.14
Tras los cambios sufridos en la versión 0.12 de Terraform, Hashicorp ha continuado mejorando su herramienta y añadiendo nuevas funcionalidades sin parar. Las más importantes bajo mi punto de vista, son las siguientes:
- Ha transformado completamente su documentación y unificado criterios, para que sea más clara y más fácil de entender. Ahora tanto proveedores como módulos están dentro del Registry público de Terraform.
- Se ha mejorado la gestión de variables, añadiendo validaciones personalizadas y la posibilidad de ocultar valores sensibles en las mismas.
- Se han potenciado los módulos y ahora soportan ciertas instrucciones como depends_on (¡Por fin!), for_each, etc.
- La usabilidad de la herramienta está más pulida y hay mejoras en la gestión del fichero de estado y de los proveedores de Terraform (lockfiles, proveedores obligatorios, etc).
Antes de añadir código alguno, vamos a comenzar adaptando el código ya existente a la última major versión. Para realizar el salto de la versión 0.12 a la 0.14, necesitamos que nuestro código esté creado con la última versión disponible de la 0.12 (0.12.30) y tener instaladas una versión de Terraform 0.13 y otra de la versión 0.14.
En este caso, el comando terraform13 se corresponde con la versión 0.13 y terraform a secas con la versión 0.14 de la herramienta.
El código previo de la infraestructura puede verse aquí.
Los cambios en el código son pequeños, pero afectan a la definición de proveedores y cambian su estructura. Aquí podemos ver la diferencia entre un proveedor de la versión 0.12 y uno de cualquiera de las posteriores:
# Proveedor de la versión 0.12 de Terraform
provider "google" {
credentials = file("../terraform.json")
project = var.gcp_default_project
region = var.gcp_default_region
}
# Proveedor de la versión 0.13/0.14 de Terraform
terraform {
required_providers {
google = {
source = "hashicorp/google"
version = "~> 3.52"
}
}
}
provider "google" {
credentials = file("../terraform.json")
project = var.gcp_default_project
region = var.gcp_default_region
}
Tan sólo tenemos que definir un nuevo bloque donde le indicamos a Terraform cuales son las versiones de los proveedores que vamos a necesitar.
Realizar la migración es un proceso sencillo puesto que Terraform ofrece algunos comandos personalizados que nos ayudan a en la tarea. Debemos realizarlos en un cierto orden y si lo hacemos mal o sin cumplir todos los pasos, podemos encontrarnos con errores como el siguiente:
You must complete the Terraform 0.13 upgrade process before upgrading to later versions.
Para realizar la migración vamos a utilizar la versión 0.13 de Terraform ejecutando los siguientes pasos:
# Ejecutamos el comando de actualización en cada carpeta donde hayamos definido el proveedor
terraform13 0.13upgrade
# Se nos creará un fichero versions.tf con la versión de Terraform mínima que nuestro código soporta. Su contenido será similar a éste:
terraform {
required_version = ">= 0.14"
}
# También deberemos revisar el fichero de proveedores (en este caso provider.tf) para ver si la estructura es la correcta.
# Debe contener la estructura de required_providers comentada anteriormente
# Si tenemos dudas, podemos ir al Registry a ver cómo se configura
terraform {
required_providers {
$NOMBRE_DEL_PROVEEDOR = {
source = $PROVEEDOR_EN_HASHICORP_REGISTRY
version = "~> $VERSION_DEL_PROVEEDOR
}
}
}
Aunque la migración ya podría estar finalizada, es posible que debamos realizar un paso extra debido a que los proveedores del remote state de Terraform, no estén en la sintaxis correcta. En caso afirmativo, cuando intentaramos usar la versión 0.14 recibiríamos un error similar a este:

La solución es sencilla, lo primero que tenemos que hacer es ver que proveedor tiene registrado y Terraform posee un comando para ello terraform13 providers:

Dicho comando imprime por pantalla los proveedores que tenemos en nuestros ficheros .tf y los registrados en nuestro ficho de estado. En este caso, ambos difieren y mientras en local tenemos registry.terraform.io/hashicorp/google, en remoto tenemos registry.terraform.io/-/google.
¡Que nadie se asuste!. No necesitamos modificar a mano el estado remoto y podemos utilizar Terraform para hacer dicho cambio de forma transparente. Con el siguiente comando, ya tendremos la migración a la versión 0.13 completa:
# Si alguien usa otros proveedores deberá poner cada uno en su lugar.
# Como se puede observar el primer provider es el del remote state que vamos a eliminar
# y el segundo es el que queremos poner en su lugar. Los datos los sacamos del comando anterior
terraform13 state replace-provider registry.terraform.io/-/google registry.terraform.io/hashicorp/google
Con todos los cambios realizados a la versión 0.13, simplemente modificamos en los ficheros versions.tf la versión requerida a 0.14 y ya podemos utilizar dicha versión: terraform init && terraform plan.
Bola extra: arreglar Gitlab CI con Terraform 0.14
Otro inconveniente no esperado que encontré al actualizar, fue la rotura del sistema de CICD del repositorio. Lo utilizo para sincronizar el código de Terraform y el código en Python de las funciones que utilizo. Si alguien desea más información al respecto, escribí un post sobre ello.
Corregirlo fue fácil y sólo fue necesario modificar dos puntos:
-
La versión de Terraform usada en el pipeline, que seguía anclada en la última versión disponible de Terraform 0.12. Modifiqué las variables en Gitlab para utilizar la 0.14.
-
Para evitar que Terraform descargue sus dependencias en cada paso del pipeline, reutilizo siempre la misma caché en un directorio. Dicho directorio almacena los plugins y los providers necesarios por el código para funcionar y su ubicación ha cambiado en la versión 0.14.
Sólo he necesitado modificar el valor de la variable PLUGIN_DIR a "../terraform/providers"_ para que el pipeline volviera a la vida. Adjunto un step a modo de ejemplo, pero cualquiera puede consultar el fichero completo en el repositorio:
validate:
image:
name: hashicorp/terraform:$TF_VERSION
entrypoint:
- '/usr/bin/env'
- 'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
stage: validate
before_script:
- echo 'nameserver 1.1.1.1' > /etc/resolv.conf
- echo 'nameserver 1.0.0.1' >> /etc/resolv.conf
- cat "$GOOGLE_APPLICATION_CREDENTIALS" > $PWD/terraform.json
- terraform init
script:
- cd functions && terraform init -plugin-dir=$PLUGIN_DIR && terraform validate
variables:
PLUGIN_DIR: "../.terraform/providers"
Google Data Studio y Terraform
Data Studio es un Saas sin coste: sólo tenemos que loguearnos en la herramienta con una cuenta de GMail o G Suite para utilizarlo y cada informe que creemos se guardará automáticamente en nuestro almacenamiento de Google Drive.
Data Studio es la herramienta que voy a utilizar para visualizar la información de quien visita tangelov.me: me interesa especialmente que sistema operativo y navegador utilizan, cuales son los posts más visitados o su procedencia. Aunque Data Studio soporta una enorme cantidad de fuentes de datos distintas, yo sólo voy a utilizar los registros que genera Google App Engine en Cloud Logging y que ya se exportaban previamente y de forma automática a un dataset de BigQuery (una de las fuentes de datos soportadas).
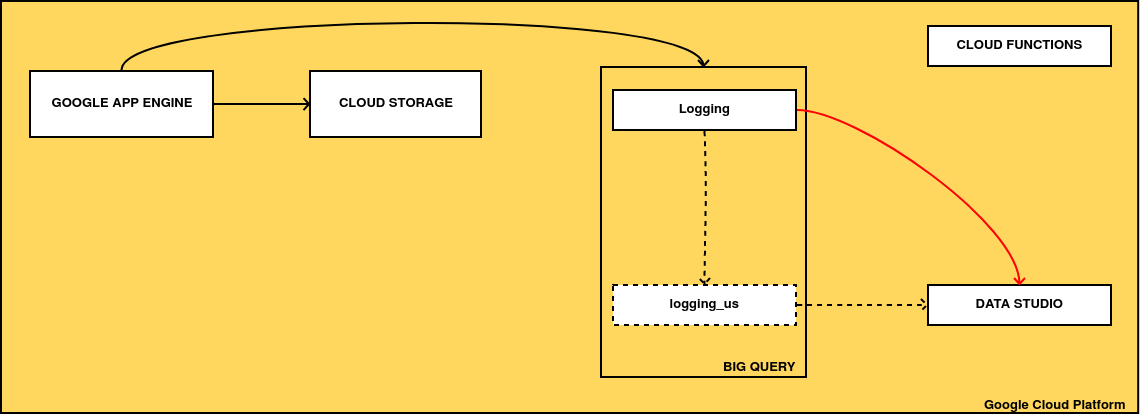
Desgraciadamente, Terraform no soporta Data Studio puesto que su API es muy limitada y sólo vamos a crear con él algo de infraestructura extra, a la que conectaremos informes creados a mano. En la siguiente imagen podemos ver todos los cambios que voy a añadir:
-
Los recuadros con lineas intermitentes se corresponden con recursos que todavía no existen. Voy a crear un nuevo dataset de BigQuery en Estados Unidos y un sistema de transferencia periódica de datos para refrescarlos. El motivo de crear una copia de los datos en Estados Unidos es la limitación de BigQuery de realizar consultas entre datos de distintas regiones y la necesidad de cruzar los datos de las visitas, con un dataset público (que siempre suelen estar localizados en EEUU) que posee listas de IPs por países.
-
Vamos a modificar el informe de Data Studio para que en lugar de tirar del dataset original, lo haga del nuevo ubicado en Estados Unidos, puesto que éste contiene todos los datos que necesitamos.
El código final es muy sencillo:
# Transferencia de datos entre EU y US para cruzar datos con datasets publicos
resource "google_bigquery_data_transfer_config" "transfer_from_eu_to_us" {
display_name = var.gcp_bq_dataset_exports_data_transfer_dname
data_source_id = "cross_region_copy"
schedule = "every day 16:30"
destination_dataset_id = google_bigquery_dataset.logging_us.dataset_id
disabled = false
data_refresh_window_days = 0
params = {
overwrite_destination_table = "true"
source_dataset_id = google_bigquery_dataset.logging.dataset_id
source_project_id = data.google_project.tangelov_project.project_id
}
schedule_options {
disable_auto_scheduling = false
start_time = "2021-01-17T16:30:00Z"
}
depends_on = [google_project_iam_member.data_transfer_user]
La documentación de este recurso es malísima, tanto en la API de Google Cloud como en la página de Terraform y he necesitado crearlo primero en la consola, importarlo y, finalmente adaptar mi código para conseguir el estado final deseado.
Aunque este fragmento sólo recoge el código de la transferencia de datos, el código completo está disponible en el repositorio tangelov-infra y crea un dataset adicional en Estados Unidos, habilita la API necesaria para transferir los datos entre regiones y da permisos a una cuenta robot para hacerlo.
Si aplicamos el nuevo código y nos vamos a la consola de GCP, veremos que el sistema funciona correctamente:

El último paso antes de ponernos a modelar en Data Studio es crear la consulta que vamos a utilizar como fuente de datos. Accedemos a la consola de BigQuery y creamos una vista con un código similar a éste:
WITH source_of_ip_addresses AS (
SELECT protoPayload.resource as Resource,
protoPayload.ip as OriginIP,
protoPayload.startTime as StartTime,
protoPayload.referrer as Referrer,
protoPayload.userAgent as UserAgent,
timestamp as Timestamp
FROM `project-id.logging_us.appengine_googleapis_com_request_log_*`
WHERE
(
protoPayload.resource LIKE '/posts/%.html' OR
protoPayload.resource = '/' OR
protoPayload.resource LIKE '/pages/%.html'
)
AND
(
protoPayload.UserAgent LIKE '%Mozilla%' AND
protoPayload.resource NOT LIKE '%/categories/%' AND
protoPayload.resource NOT LIKE '%/tags/%'
)
)
SELECT country_name, Resource, UserAgent, StartTime
FROM (
SELECT originIP, country_name, Resource, UserAgent, StartTime
FROM (
SELECT *, NET.SAFE_IP_FROM_STRING(originIP) & NET.IP_NET_MASK(4, mask) network_bin
FROM source_of_ip_addresses, UNNEST(GENERATE_ARRAY(9,32)) mask
WHERE BYTE_LENGTH(NET.SAFE_IP_FROM_STRING(OriginIP)) = 4
)
JOIN `fh-bigquery.geocode.201806_geolite2_city_ipv4_locs`
USING (network_bin, mask)
)
La consulta está dividida en dos partes:
-
Primero obtengo ciertos datos de los registros de las visitas al blog: su dirección IP, cuando se produjo, su Referrer y su UserAgent. Para evitar añadir a las visitas los escaneos maliciosos que se realizan automáticamente en Internet y descartar algunas URLs del mismo que no me interesan (las listas de categorías o tags), filtro todas las peticiones que no vayan a la raíz de la página web, a algún post o página y que no tenga un UserAgent común.
-
Después, cruzo los datos del punto uno con los de un Dataset público que contiene listas geolocalizadas de IP y que realiza la asignación entre direcciones IP y países.
Informes en Google Data Studio
Nota del autor: En 2023, Data Studio ha sido renombrado a Looker Studio, pero sus funcionalidades no han cambiado por lo que el contenido de este post sigue siendo perfectamente funcional.
Con todo preparado, ya puedo ir a Data Studio y diseñar el informe. Lo primero que voy a hacer es agregar una fuente de datos que tire de la vista creada en el paso anterior:
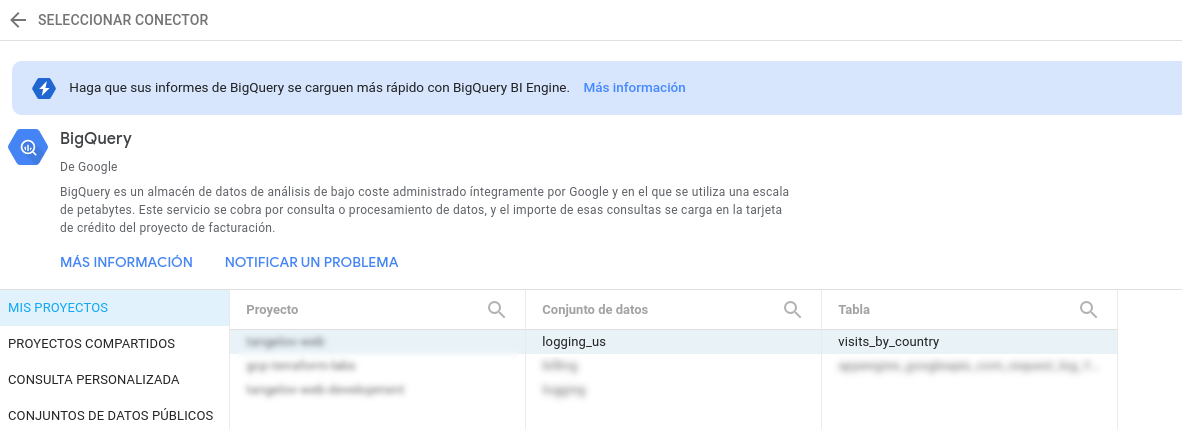
Para añadir potencia a informes de Data Studio, he creado varios campos computados que agrupan el contenido de la fuente de datos. De esta forma puedo obtener el sistema operativo, el navegador del usuario o la categoría del post que éste ha visitado. A modo de ejemplo, este es el código que agrupa los distintos navegadores:
CASE
WHEN REGEXP_MATCH(UserAgent, '(.*)Chrome(.*)')
THEN "Chrome"
WHEN REGEXP_MATCH(UserAgent, '(.*)Firefox(.*)')
THEN "Firefox"
WHEN REGEXP_MATCH(UserAgent, '(.*)Safari(.*)') OR
REGEXP_MATCH(UserAgent, '(.*)AppleWebKit(.*)')
THEN "Safari"
WHEN REGEXP_MATCH(UserAgent, '(.*)Trident(.*)')
THEN "Internet Explorer"
ELSE
"Desconocido"
END
Aunque los datos son aproximados, sí me permiten conocer un poco mejor a las personas que me visitan :).
El informe final consta de tres páginas y proporciona la siguiente información:
-
El número de visitantes por país que recibo.
-
El navegador y sistema operativo del visitante.
-
Los posts más visitados y las visitas totales.
Aquí podemos ver un mapa de calor según los visitantes de cada país entre el día 18 de diciembre de 2020 y el 16 de enero de 2021:
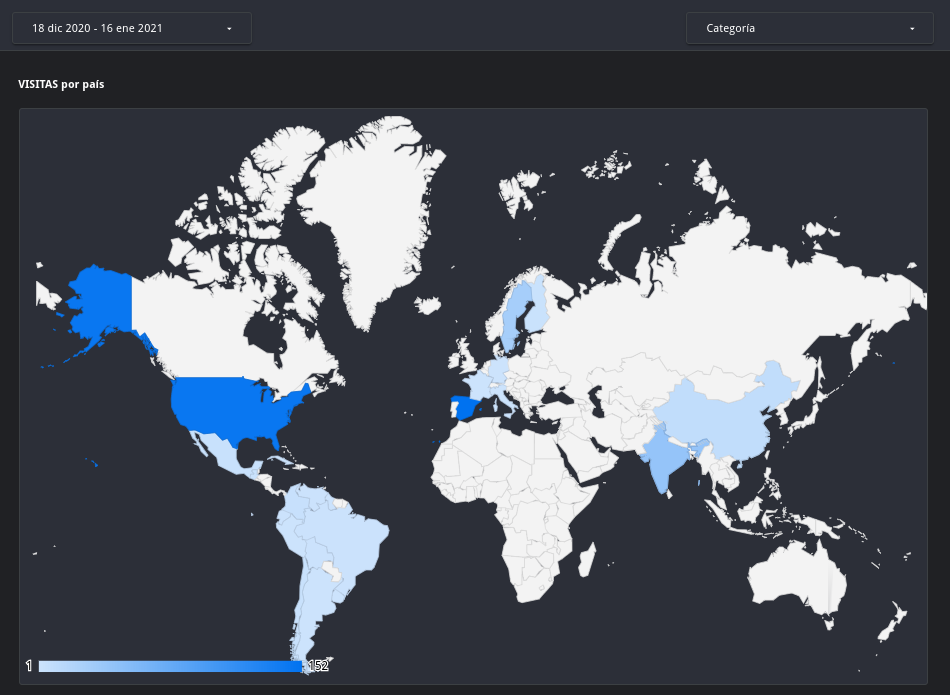
El proceso de creación de este post ha sido tremendamente divertido. Me ha permitido afianzar conceptos y quitarme una espinita que tenía clavada desde hace mucho, pero también me ha proporcionado algunos datos inesperados. Nunca me hubiera imaginado que el número de visitas de Estados Unidos fuera casi tan elevado como el de España o que mucha gente en la India acabe llegando de alguna manera a mis posts de integración continua.
En cualquier caso, un saludo a todos los que me leeis y ¡os espero en siguientes entregas!.
Documentación
-
Anuncio oficial de la versión 0.13 de Terraform por Hashicorp (ENG)
-
Anuncio oficial de la versión 0.14 de Terraform por Hashicorp (ENG)
-
Conectores a fuentes de datos soportados por Data Studio (ENG)
Revisado a 01-05-2023