Restic: Backups fáciles y flexibles para todo el mundo
2023-08-07 20:00Cuando mantenemos un servicio o un servidor y éste almacena información importante, siempre puede salir algo mal. Aunque no son muy comunes, las catástrofes ocurren y en algún momento de tu vida te enfrentarás a la posible pérdida de dicha información. Un disco duro puede fallar, un usuario puede borrar datos vitales sin querer y en casos extremos, un CPD puede salir ardiendo por completo, impactando a millones de usuarios en el globo.
Ante una posible pérdida de datos, es importante disponer de un plan B y poder recuperar de alguna manera nuestros datos, por lo que antes de poner cualquier servicio en producción, siempre diseño su sistema de respaldos y su Disaster Recovery Plan, por si hiciera falta en el futuro.
Pese a que estos eventos son muy inusuales (lo que hace que se dejen un poco de lado), cuando ocurren, estar bien preparados es la diferencia entre una pequeña molestia y perderlo absolutamente todo.
Como ya comenté en el post anterior, he estado trabajando en una versión mejorada de mi sistema de backups para volverlo más flexible y moderno, y en este post voy a comentar en profundidad por qué he decidido cambiarlo, el resultado final y mi opinión al respecto. Vamos allá.
Como diseñar un buen sistema de backups
Antes de comenzar, voy a explicar brevemente qué tenemos que tener en cuenta a la hora de diseñar un sistema de backups. Principalmente, dos cosas: cuantos datos estamos dispuestos a perder y cuanto tiempo estamos dispuestos a invertir para volver a tener nuestros servicios funcionando.
En general, en la fase de diseño nos enfrentamos a dos tradeoffs:
- Cuanto más complejo es el sistema, más difícil es volver a dejar el servidor en el estado deseado. Generalmente es más fácil y suele requerir menos trabajo (y tiempo) restaurar un único backup completo del día de hoy, que uno completo de hace 6 días y 5 incrementales.
- Cuantos menos datos estamos dispuestos a perder, más almacenamiento vamos a necesitar y más coste computacional vamos a tener. No es lo mismo hacer uno diario, que uno cada dos horas, pero ante una catástrofe, la potencial pérdida de datos es mayor en un caso que en el otro.
Esto es lo que se conoce como Recovery Time Objective (RTO) y Recovery Point Objective (RPO) y es algo que tenemos que definir en nuestro Disaster Recovery Plan (DRP).
Un sistema de backups por si mismo no te va a salvar del desastre. Debes probarlo regularmente para ver que podemos recuperar nuestra información. Esto es a lo que llamamos un Disaster Recovery Plan, un documento que explica cómo recuperar los datos, que podemos recuperar y en cuanto tiempo. Es algo importante puesto que no sería la primera vez que una empresa tiene que rescatar datos de un backup, para darse cuenta que los datos estaban corruptos, que su plan no funcionaba o que simplemente, no era realista.
Al diseñar el nuevo sistema y mi DRP tuve en cuenta cuatro variables:
- Deseaba tener una copia de respaldo en remoto para protegerme ante discos duros que fallan, incendios y otra serie de catástrofes.
- La posibilidad de recuperar información de al menos los últimos 15 días, aunque preferiría un mes.
- Una buena seguridad: el contenido debe estar cifrado y bajo mi control para poder asegurar de forma inequívoca la integridad de los datos.
- Mi RTO debería ser de 3-4 horas (desde cero) y mi RPO de 24, puesto que no suelo almacenar datos que cambien todos los días.
Con todo ello, diseñé un documento que explicaba cómo aplicar los scripts de Ansible para crear un nuevo servidor y cómo restaurar los datos para dejarlo como nuevo. Aunque realizaba una prueba anual, gracias a dicho documento pude migrar mi vieja Banana Pi a otro servidor sin apenas esfuerzo en un par horas.
Mi antiguo sistema
En un post de 2020, expliqué un poco el funcionamiento del sistema original y ya de aquella, comenté que me había encontrado con algunos problemas.
Aunque generalmente funciona bien, sí he tenido algunas incidencias desde que lo implementé, todas ellas relacionadas con la imposibilidad de subir el respaldo al destino remoto (tokens expirados, discos remotos llenos, etc).
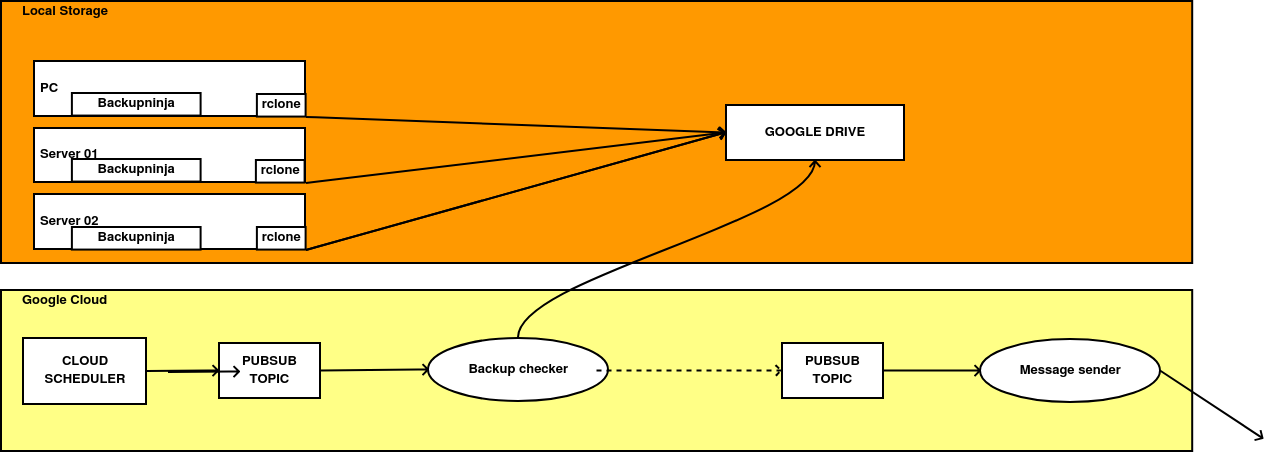
El sistema funcionaba así:
- Un cron se ejecutaba una vez al día y generaba una copia de un servidor al completo (para reducir la complejidad).
- Después se cifraba con GPG para que el contenido no fuera accesible salvo que se tuviera acceso a una llave privada (para garantizar la seguridad).
- El archivo cifrado era subido automáticamente a algún sistema de almacenamiento en la nube, para tener una copia externa al servidor (para garantizar la durabilidad).
- Todos los días se ejecutaba una Cloud Function, que verificaba que los ficheros cifrados estuvieran a buen recaudo en Google Drive y en caso negativo, generaba un mensaje que era enviado a mi teléfono móvil.
Cada ejecución proporcionaba un paquete que permitía la recuperación relativamente rápida de un servidor entero cuando lo combinaba con Ansible. Sin embargo, realizar una copia de seguridad completa diaria también tenía sus inconvenientes:
El tamaño de los datos siempre tiende a crecer y poco a poco, me vi forzado a ir reduciendo el número de copias que podía subir en remoto, de 15 días a 4 en los últimos meses. Además, llenar el almacenamiento remoto terminó convirtiéndose en una incidencia habitual, que solucionaba a mano cuando me cansaba de recibir notificaciones.
Un mayor tamaño, también implicaba que un mayor tiempo de ejecución y la realización del proceso pasó de unos 15-20 minutos hace tres años a más del doble actualmente, impactando a veces en el funcionamiento del servidor y su fiabilidad.
Con todo esto en mente y teniendo en cuenta que tengo pensado poner más servicios en Producción, decidí que era el momento de dedicarle un tiempo y rehacer todo el sistema de cero, solucionando de golpe todos los problemas que me había encontrado.
Restic y ResticProfile
Para el nuevo sistema era importante añadir tres mejoras del que el sistema anterior carecía:
- El poder realizar backups incrementales. Así reducía el espacio almacenado en remoto y el tiempo necesario para completarse.
- Una mayor flexibilidad: El sistema anterior sólo permitía restaurar los ficheros de forma completa y quería uno que me permitiera hacerlo por directorios de forma independiente. Si por ejemplo necesitaba probar algo de forma puntual, me veía obligado a descomprimir todo el paquete y luego copiar a mano solo el contenido que me interesaba.
- La misma fiabilidad y seguridad que el sistema anterior.
Aunque Backupninja era una herramienta fiable, era también bastante antigua y con unas funcionalidades bastante limitadas, que ya me había visto obligado a ampliar a través del uso de scripts en Bash.
Tras leer sobre muchas alternativas y probar algunas de ellas, al final decidí quedarme con Restic. Es una herramienta Open Source, escrita en Go, que permite la creación y gestión de backups tanto en local como en sistemas remotos (desde SFTP a una gran cantidad de sistemas de almacenamientos de objetos), de forma eficiente y segura. Que el sistema funcione de forma incremental por defecto y que la calidad de su documentación fuese excelente, hizo que tomar la decisión fuera fácil.
Restic no sólo permite seleccionar una serie de carpetas y generar una copia de las mismas, tiene muchas otras funcionalidades útiles. Por ejemplo:
- Permite implementar y gestionar una política de retención a nuestros respaldos desde la propia herramienta.
- Restaurar carpetas de forma independiente.
- La utilización de tags, tanto para identificar backups como para aplicar políticas basándonos en ellas.
- Gestionar errores en la propia aplicación, así cómo añadir scripts que se ejecuten de forma automática, antes, después o tras un error.
Aunque su falta de soporte de llaves GPG no fue de mi agrado, estuve buscando más información sobre la seguridad de su cifrado y vi que era totalmente seguro y de fiar.
Una vez descargado, comencé a ver cómo podía adaptar sus funcionalidades a los requerimientos que quería en mi nuevo sistema:
-
Cada ordenador tendría una copia propia, guardando los datos de algunas carpetas y en caso de que hubiese alguna base de datos, una copia de la misma.
-
Los respaldos se harían de forma diaria y serían incrementales para los ficheros y completos para las bases de datos (son pequeñas).
-
Se aplicaría una política de retención de 7 días, reteniendo una copia mensual y otra semanal.
-
En caso de error al realizar el backup, una notificación debería llegar a mi teléfono móvil para revisar qué ha ocurrido de forma manual.
Restic sigue bastante a rajatabla los principios KISS (Keep It Simple, Stupid) y toda su configuración se hace a través de parámetros que le pasamos a su CLI.
Para comenzar a utilizarlo sólo tenemos que crear un repositorio e indicarle donde queremos almacenar los datos. A modo de ejemplo, si queremos crear un nuevo repositorio local, crear un nuevo backup y asegurarnos que se guardan al menos cuatro copias, tendríamos que lanzar los siguientes comandos:
# Primero creamos nuestro repositorio e introducimos la contraseña de cifrado
restic init --repo /media/external/backups
enter password for new repository:
enter password again:
created restic repository f4b5832g at /media/external/backups
Please note that knowledge of your password is required to access the repository.
Losing your password means that your data is irrecoverably lost.
# Después ejecutamos nuestro backup y le indicamos la política de retención a seguir
restic -r /media/external/backups --verbose backup ~/var/www/html
restic forget --keep-last 4 --prune
Como ya he comentado, Restic gestiona todas sus funcionalidades a través de parámetros que le pasamos a su interfaz. Pese a que esto no era un problema y que podía escribir algunos scripts en Bash para arreglarlo, si que me resultaba algo engorroso. También me parecía extraño que la herramienta no tuviera dicha funcionalidad y entre buscando entre sus issues en Github, me encontré con lo siguiente.
En resumen, que dicha funcionalidad todavía no existe, pero que hay herramientas de terceros que la proporcionan. De todas ellas, la que más me gustó y me pareció que estaba mejor mantenida era Resticprofile. Esta pequeña aplicación nos permite tener un fichero de configuración en formato YAML, TOML o INI y que éste le pase todos los parámetros necesarios a Restic para funcionar, convirtiendo dicho fichero en la fuente de verdad del nuevo sistema.
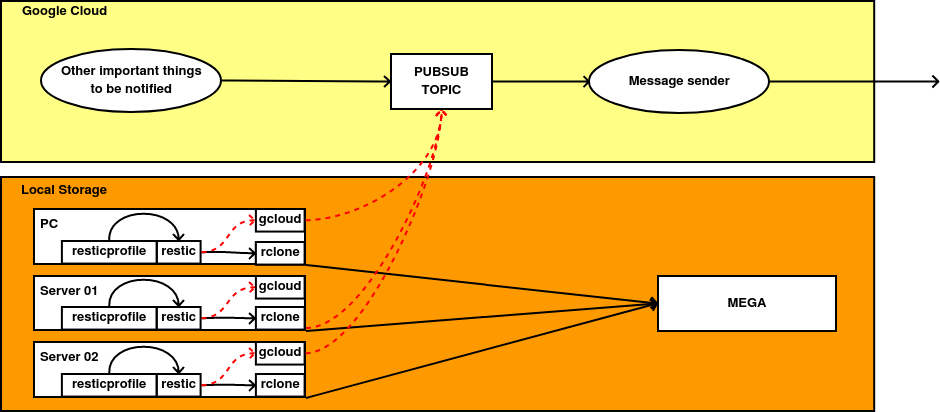
Este sería el esquema final del sistema:
- Definimos cómo queremos que sea nuestro sistema de backups en Resticprofile.
- A través de un cron, ejecutamos Resticprofile. Éste se encarga de llamar a Restic y ejecutar paso a paso lo que hemos definido en nuestro fichero de configuración.
- Restic se conecta al servicio de almacenamiento en la nube a través de Rclone.
- En caso de fallo, se crea un mensaje con la CLI de Google Cloud, que es enviado a una cola de PubSub, procesado y enviado a una sala privada de Matrix donde un bot me notifica del fallo.
Despliegue con Ansible
Tras investigar todo lo necesario para crear nuestro sistema de backups, vamos a integrarlo en mi sistema de despliegues basado en Ansible. En este post, vamos a asumir que se tienen algunos conocimientos básicos de Ansible (qué es un inventario, uso de plantillas Jinja2, etc), pero en el caso de tener dudas, recomiendo visitar mis posts sobre este gestor de configuración tan chulo y potente.
Lo primero que tenemos que hacer es descargar y desplegar tanto Restic como Resticprofile (ya utilizaba rclone previamente):
- name: Installing Restic and ResticProfile
block:
- name: Checking Restic version
ansible.builtin.command: "restic version"
register: restic_installed_version
ignore_errors: yes
- name: Downloading Restic for creating backups after Rclone installation
ansible.builtin.get_url:
url: "https://github.com/restic/restic/releases/download/v{{ restic_version }}/restic_{{ restic_version }}_linux_{{ restic_arch }}.bz2"
dest: "/tmp/"
when: restic_version not in restic_installed_version.stdout
- name: Unpack and rename Restic binary
ansible.builtin.shell:
cmd: bzip2 -d restic_{{ restic_version }}_linux_{{ restic_arch }}.bz2 && mv restic_{{ restic_version }}_linux_{{ restic_arch }} restic
chdir: /tmp
when: restic_version not in restic_installed_version.stdout
- name: Copy Restic to final destination
ansible.builtin.copy:
src: /tmp/restic
dest: /usr/local/bin/restic
mode: 0744
remote_src: yes
when: restic_version not in restic_installed_version.stdout
- name: Delete temporal file for Restic
ansible.builtin.file:
path: /tmp/restic
state: absent
when: restic_version not in restic_installed_version.stdout
- name: Installing ResticProfile
ansible.builtin.unarchive:
src: "https://github.com/creativeprojects/resticprofile/releases/download/v{{ resticprofile_version }}/resticprofile_no_self_update_{{ resticprofile_version }}_linux_{{ restic_arch }}.tar.gz"
dest: "/usr/local/bin"
mode: 0744
owner: root
group: root
extra_opts:
- "--wildcards"
- "resticprofile"
remote_src: yes
La instalación de Resticprofile utiliza el módulo de Ansible unarchive, pero la de Restic es más complicada. Restic se encuentra empaquetada dentro de un fichero .bzip2 y este formato no es soportado de forma nativa por ningún módulo de Ansible así que compruebo de forma manual si Restic está instalado o si se encuentra en una versión no deseada y sólo ante esos supuestos, instalo la herramienta.
El siguiente paso es instalar la CLI de Google Cloud que utilizaremos en caso de errores o fallos:
- name: Installation of Google Cloud SDK from official ppa
tags: gcp
block:
- name: Installing Google Cloud repository key
become: true
get_url:
url: "https://packages.cloud.google.com/apt/doc/apt-key.gpg"
dest: /usr/share/keyrings/cloud.google.asc
mode: 0644
force: true
- name: Installation of Google Cloud SDK prerrequisites
become: true
ansible.builtin.apt:
name:
- apt-transport-https
- ca-certificates
- gnupg
update_cache: no
state: present
- name: Installation of Google Cloud SDK repository
become: true
ansible.builtin.apt_repository:
repo: "deb [signed-by=/usr/share/keyrings/cloud.google.asc] https://packages.cloud.google.com/apt cloud-sdk main"
filename: google-cloud-sdk
state: present
- name: Installation of Google Cloud CLI from GCP repository
become: true
ansible.builtin.apt:
name: google-cloud-cli
state: present
Antes de proceder a configurar Restic, necesitamos cumplir con una serie de prerrequisitos:
- Cuando iniciamos un repositorio en Restic, éste nos pregunta por una contraseña que tenemos que introducir cada vez que queramos interactuar con él. Podemos definirla de tres formas: introduciéndola manualmente o almacenándola en un fichero o una variable de entorno. Puesto que nuestro sistema se va a ejecutar de forma automática, tenemos que elegir una de las dos últimas.
- Si nuestro servidor ejecuta alguna base de datos y queremos realizar una copia, tenemos que permitir el acceso a la misma a través del usuario que ejecuta Restic a través de mysqldump. Para ello, podemos crear un fichero de credenciales con un usuario y contraseña de MySQL y para poder copiar el contenido de la base de datos.
- Por último, queremos que Restic pueda enviarnos un mensaje en caso de encontrar un error, necesitando crear una cuenta de servicio en Google Cloud y descargar su JSON. Los permisos mínimos que debe tener dicha cuenta es PubSub Publisher.
Con los prerrequisitos cumplidos, podemos continuar configurando el sistema. Consta fundamentalmente de dos partes: la creación del fichero de Resticprofile y la de la CLI de Google Cloud para que utilice la cuenta de servicio que acabamos de crear.
La plantilla de Resticprofile es la siguiente:
version: "1"
global:
default-command: snapshots
initialize: false
priority: low
min-memory: 200
groups:
full-backup:
- data
{% if 'servers' in group_names %}
- mysql
{% endif %}
default:
password-file: key
repository: rclone:megarestic:{{ custom_hostname }}
run-after-fail: gcloud pubsub topics publish {{ gcp_pubsub_topic_name }} --message "Your backup has failed in {{ custom_hostname }}." --project {{ gcp_project }}
retention:
before-backup: false
after-backup: true
keep-daily: 7
keep-weekly: 1
keep-monthly: 1
keep-tag:
- forever
prune: true
tag: true
host: true
data:
inherit: default
initialize: false
lock: /tmp/resticprofile-data.lock
backup:
exclude-caches: true
one-file-system: false
source:
{% for path in restic_folders %}
- {{ path }}
{% endfor %}
tag:
- data
{% if 'servers' in group_names -%}
mysql:
inherit: default
initialize: false
lock: /tmp/resticprofile-mysql.lock
backup:
stdin: true
exclude-caches: true
one-file-system: false
tag:
- mysql
no-error-on-warning: true
stdin-command: [ 'mysqldump --defaults-file=/etc/mysql/backup.cnf {{ restic_databases }} --order-by-primary' ]
stdin-filename: "dump.sql"
{% endif %}
Esta plantilla de Ansible se despliega de forma dinámica según los valores que hayamos configurado en esas variables. Por ejemplo, restic_databases se corresponde con las bases de datos que queremos salvar y gcp_project lo hace con el ID del proyecto de Google Cloud donde se encuentra nuestro topic de Pub/Sub. En general utilizo nombres bastante descriptivos.
Ahora voy a explicar que hace cada parte de la plantilla para resolver cualquier posible duda y evitar que alguien tenga que leerse toda la documentación de Resticprofile:
-
En global definimos ciertos parámetros utilizados por defecto por Resticprofile como el comando de Restic a utilizar cuando no indiquemos ninguno, si tiene o no que inicializar los repositorios, etc.
Inicializar un repositorio, es una operación destructiva y que debemos de tener muy bien controlada.
-
En groups definimos agrupaciones de backups. En mi caso, los grupos me permiten ejecutar de forma secuencial distintas configuraciones en función de las necesidades de cada servidor.
-
default es la primera definición de backups que tenemos en el fichero. Sin embargo, sólo lo utilizo como una plantilla para otras configuraciones. En este caso, aquí definimos el repositorio a utilizar, su contraseña, los comandos a ejecutar si falla y su política de retención.
-
data hereda la configuración por defecto y simplemente añade que carpetas deben de ser guardadas.
-
mysql al igual que data, hereda la configuración por defecto, pero sólo se activa si Ansible se ejecuta sobre una máquina que se encuentre dentro del grupo de servers en su inventario. Utilizando la capacidad de poder guardar con Restic lo que creamos a través del stdin, guardamos ciertas bases de datos y las añadimos al respaldo.
El último paso se corresponde con la configuración de la CLI de Google Cloud:
- name: Installing Restic and ResticProfile
block:
- name: Configuring ResticProfile
vars:
ansible.builtin.template:
src: templates/resticprofile.j2
dest: ".config/restic/profiles.yaml"
mode: "0640"
- name: Creating key file for ResticProfile
ansible.builtin.copy:
content: "{{ restic_password }}"
dest: .config/restic/key
mode: "0640"
- name: Configuring cron to launch restic using Resticprofile
ansible.builtin.cron:
name: "rclone"
minute: "{{ rclone_cron_minute }}"
hour: "{{ rclone_cron_hour }}"
job: "resticprofile -c .config/restic/profiles.yaml -n full-backup backup"
- name: Configuring GCP Service Account for sending messages
block:
- name: Deployment of the Service Account into Restic folder
ansible.builtin.copy:
content: '{{ gcp_service_account | b64decode }}'
dest: ".config/restic/gcp.json"
mode: "0640"
register: gcp_account
- name: Configuring GCP account in GCloud CLI
ansible.builtin.command: "gcloud auth activate-service-account --key-file=.config/restic/gcp.json"
when: gcp_account.changed
Si alguien quiere ver todo el código junto, puede acceder a él aquí.
Y ya estaría, ahora podríamos ejecutarlo a mano o simplemente consultar su estado.
resticprofile -c .config/restic/profiles.yaml -n data status
Analyzing backup schedule 1/1
=================================
Original form: daily
Normalized form: *-*-* 00:00:00
Next elapse: Mon 2023-08-07 00:00:00 CEST
(in UTC): Sun 2023-08-06 20:00:00 UTC
From now: 1h 43min left
Recent log (>= warning in the last month)
==========================================
-- No entries --
Mi opinión personal
Llevo utilizando este sistema un par de semanas y la verdad es que no podría estar más contento. Tremendamente fiable, está utilizando un 20% del almacenamiento comparado con el sistema anterior y con muchas más puntos de respaldo. Hasta he probado forzar algún error y la notificación ha llegado sin demora a mi teléfono.
Más allá del beneficio directo, he tenido uno extra que no había tenido en cuenta: Restic no crea “paquetes” como Backupninja así que ya no necesito mantener la Cloud Function que comprobaba si se habían relacionado correctamente ni tampoco mantener el código del rol de Ansible que utilizaba para instalar y configurar Backupninja. Es cierto que era poco trabajo, pero algo es algo.
Por último, me gustaría comentar un par de cosas que no me han gustado tanto y que me gustaría dejar por escrito.
Aunque el sistema funciona muy bien, me ha impresionado la cantidad de herramientas encadenadas que necesito para tener un sistema completo. Al final, estoy utilizando cuatro diferentes (Resticprofile, Restic, Rclone y la CLI de Google Cloud) y yo siempre he apostado por la simplificada. Siento que quizás podría renunciar a alguna funcionalidad a cambio de simplificar el sistema, pero de momento se va a quedar así.
Tampoco me siento muy cómodo teniendo que guardar tantas contraseñas en local. Al final, el sistema necesita tener acceso a la contraseña para abrir el repositorio de Restic, un fichero con un usuario y contraseña de MySQL para poder acceder al contenido de la base de datos y una cuenta de servicio de Google Cloud. Sin embargo, estuve dándole vueltas y no es algo tan grave: a la hora de seleccionar las cuentas he aplicado una política de less privilege, asegurando que los programas tengan sólo los permisos que necesitan y al estar todo codificado, es muy sencillo rotar las credenciales. Y si tienen permisos para acceder a dichas credenciales y a los backups, ese sería el menor de mis problemas.
Así que nada, esto es todo. Espero que os haya gustado y nos vemos en el siguiente post. ¡Un saludo a todos!
Documentación
Revisado a 07-08-2023