Raspberry Cloud: servicios desde casa
2023-07-05 06:00Considero que soy una persona con una gran curiosidad investigadora. Cada año diseño mi propio programa de formación con tecnologías para aprender, libros para leer y habilidades que me gustaría conseguir. Llevo unos diez años haciéndolo y aunque los plazos que me autoimpongo no se cumplen jamás, el resultado general es positivo
Este es uno de los motivos por los que me gestiono algunos servidores caseros. Me permiten aprender nuevas tecnologías y probar cosas a cambio de complicarme un poco la vida. Un ejemplo de esto es Ansible: aunque llevo sin usarlo en el trabajo años, sigo manteniendo amplios conocimientos en dicha tecnología al utilizarlo habitualmente en casa.
Trato de dar a mis proyectos personales el mismo mimo que cuando trabajo: un buen mantenimiento, un ciclo de actualizaciones serio y un sistema de testeo relativamente completo para poder iterar sin problemas.
Sin embargo, cada tecnología tiene sus limitaciones, ventajas e inconvenientes. Por eso en este post, voy a explicar los problemas a los que me he enfrentado y cómo voy a transformar estos servidores de cara al futuro.
Introducción
Antes de en materia, necesito dar un poco de contexto puesto que mis últimos posts datan de 2021(I y II).
Mis servidores personales siempre han sido plaquitas basadas en ARM. Me gusta su gran eficiencia energética y pese a que al principio opté por el primer modelo de la Banana Pi, actualmente he migrado todo a distintas versiones de la Raspberry Pi (4B y 3B) por la gran comunidad de la que disponen.
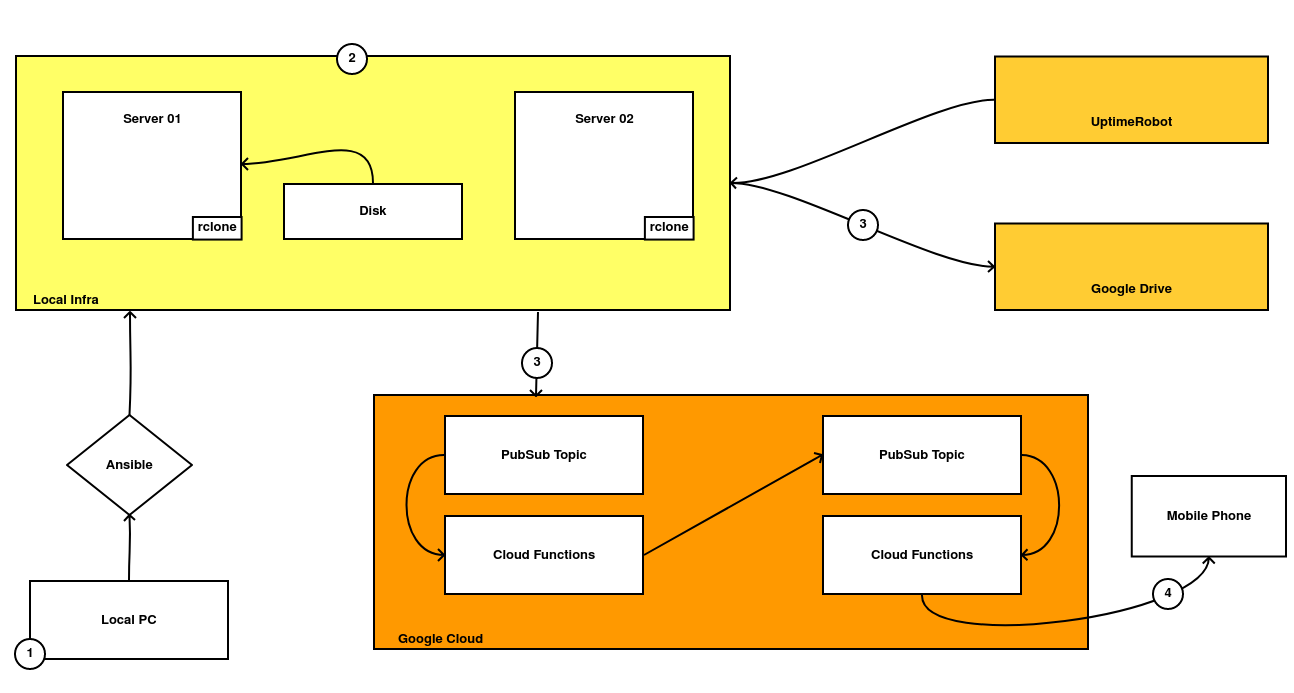
A grandes rasgos, esto sería lo que tengo en local:
Para la instalación, configuración y mantenimiento de los distintos servidores, utilizo una colección de roles, collections y playbooks de Ansible. Si alguien está interesado, son accesibles desde aquí.
-
Para la instalación, configuración y mantenimiento de los distintos servidores, utilizo una colección de roles, collections y playbooks de Ansible. Si alguien está interesado, son accesibles desde aquí.
-
Corriendo en los servidores están mis servicios. De algunos ya he hablado anteriormente (como Nextcloud), pero utilizo algunos más. Para gestionar el ciclo de vida de estos servicios de forma transparente, me baso en los recursos de Ansible que he comentado en el punto anterior.
-
Debido a que lo utilizo a diario, mis servidores se monitorizan a través de algunas aplicaciones de terceros. Uptime Robot me permite comprobar que se encuentran activos (y recibir notificaciones en caso contrario) e implementé un sencillo sistema de backups, que realiza un backup al completo de forma diaria y que sube una copia a Google Drive.
-
Si un backup no se ha subido a la nube, o algún servicio deja de funcionar, recibo notificaciones en mi móvil para poder aplicar alguna remediación.
Trade-offs en tecnología
Un trade-off es traducido según la Wikipedia como una solución de compromiso. En ingeniería, significa que a la hora de tomar una decisión, ésta generará ciertas ventajas pero también algunos inconvenientes que tendremos que solucionar.
Existen muchos motivos por los cuales nos vamos a tener que enfrentar a trade-offs, pero el principal es que no existe una tecnología perfecta para todos los casos de uso y en la mayoría de casos, tendremos que adaptarnos.
En mi caso, la decisión de utilizar Ansible es correcta. El sistema fue evolucionando desde una lista de scripts escritos en Bash hace más de siete años y aunque estoy contento, tiene algunos problemas:
-
Es poco flexible. Cada vez que quiero probar un nuevo servicio, tengo que invertir una gran cantidad de tiempo y trabajo, codificando desde cero los playbooks para Ansible. Aunque a veces existen roles, no siempre son de gran calidad y puedo utilizarlos sin adaptarlos.
-
El sistema de mantenimiento es lento. Cada ventana de mantenimiento hace que las aplicaciones no estén disponibles en torno a unos 45 minutos puesto que todo debe hacerse de una forma ordenada y con poca capacidad para paralelizar ciertas tareas sin riesgo.
-
El sistema de backups también tiene una gran rigidez. Aunque utilizar backups completos simplifica la restauración de sus datos en caso de desastre, requiere tanto tamaño en la nube que a veces se me llena el espacio de la cuenta de Google Drive que uso para almacenarlos en caso de Disaster Recovery. También tardan bastante tiempo en realizarse.
-
El sistema de monitorización es demasiado básico: aunque puedo saber si un servicio está vivo o no, no puedo saber por qué. Si bien esto no es un gran problema, creo que es fácilmente mejorable.
Una vez hemos identificado los problemas, podemos tomar decisiones y proponer soluciones. Vamos allá.
La flexibilidad de los contenedores
Si deseo probar una nueva aplicación, tengo que realizar los siguientes pasos:
Primero debo buscar si existen roles públicos para dicha aplicación en GitHub, Ansible Galaxy y otros repositorios. En caso contrario, debo crear los playbooks para instalarla y entender un poco cómo funciona la misma para aplicar los parches de mantenimiento, mantener sus dependencias actualizadas y el orden en que todo el proceso debe hacerse. Esto hace que cualquier cambio requiera de una gran inversión temporal en tiempo y trabajo.
Por ejemplo, recuerdo que integrar un Pi Hole en el sistema, me costó aproximadamente 10 días de trabajo, en investigación, integración y testeo.
Hoy en día, casi todos los desarrolladores (o su comunidad) mantienen contenedores para ejecutar de manera sencilla sus aplicaciones y el uso de contenedores es una de las mejores soluciones posibles a este problema.
Los contenedores son sistemas que nos permiten agrupar aplicaciones y sus dependencias en un mismo paquete y que además suelen tener integrado el ciclo de vida de la aplicación, además de soporte y mantenimiento por parte de los desarrolladores (quitándome yo esa parte del trabajo). En muchos casos, actualizar una aplicación desplegada sobre contenedores es simplemente reemplazar uno por el otro.
Grafana Cloud
He estado utilizando Uptime Robot como servicio de monitorización durante años. Envía peticiones a nuestros servicios y le permite detectar si están activos o no. Aunque estoy orgulloso de tener unos SLAs por encima del 99,9%, me hubiera gustado tener más información para saber qué había pasado cada vez que tenía una incidencia, en lugar de tener que llegar a casa y ponerme a investigar a ciegas.
Grafana es uno de los softwares open-source de monitorización de código abierto con más éxito en los últimos años. Permite crear paneles muy completos para ver de un vistazo el estado de nuestros servidores y además, la compañía que lo desarrolla publicó hace tiempo un servicio gestionado que es mantenido por ellos.
Su tier gratuito es bastante generoso si tenemos un puñado de servidores y de esta forma yo puedo disfrutar de un servicio completo de monitorización y alertas, con relativamente poco esfuerzo (y además, aprendo algo nuevo)
El futuro de mis servicios
Al llevar tantos años gestionando así mis servicios, cualquier cambio que quiera hacer ahora va a requerir mucho trabajo (y me da bastante pereza). Sin embargo, creo que en esta ocasión merecerá la pena luchar contra la comodidad y asumir el resto. Ganaré mucha flexibilidad para cacharrear y probar nuevos servicios y aplicaciones que al final es lo que me gusta.
En primer lugar, me gustaría comentar que Ansible no va a desaparecer. Sigue siendo una herramienta genial y va a seguir utilizándose para mantener los servicios básicos de los servidores, aplicar parches y actualizaciones,. Lo que sí que voy a hacer es mover las aplicaciones a contenedores y a realizar unos cambios extra que ahora voy a exponer.
El primer cambio que voy a hacer es evitar en la medida de lo posible que mis aplicaciones escriban en la tarjeta SD de las placas ARM. Toda tarjeta SD tiene un número limitado de veces sobre las que se puede escribir en ella y si no tenemos cuidado, podemos matar las tarjetas en apenas un año de vida. Si a mi no me ha ocurrido, pese a tener una base de datos corriendo en ella, es porque mis servicios apenas tienen tráfico. Esto es algo que tengo que tener en cuenta si quiero meter más aplicaciones.
Para conseguirlo, vamos a hacer dos modificaciones: primero vamos a modificar el tamaño del journal que utiliza Systemd y después vamos a utilizar Log2RAM. Este servicio crea un servicio de ficheros en nuestra memoria RAM y lo monta sobre la ruta /var/log haciendo que todos los servicios escriban sobre él en lugar de hacerlo sobre la tarjeta. Para no perder los datos si tenemos un corte de luz, los datos se sincronizan al disco una vez al día.
He creado estas tareas en Ansible para aplicar estos cambios:
- name: Installing and configuring Log limitations
block:
- name: Disabling unlimited journal log
ansible.builtin.lineinfile:
path: "/etc/systemd/journald.conf"
regexp: '^#SystemMaxUse=.*$'
line: "SystemMaxUse=64M"
owner: "root"
group: "root"
mode: '0644'
- name: Setting facts so that they will be persisted in the fact cache
ansible.builtin.set_fact:
log2ram_version: "{{ log2ram_version }}"
cacheable: yes
register: log2ram_result
- name: Download Log2Ram from official repository
ansible.builtin.unarchive:
src: "https://github.com/azlux/log2ram/archive/refs/tags/{{ log2ram_version }}.tar.gz"
dest: "{{ tools_folder }}"
mode: 0744
extra_opts:
remote_src: yes
when: log2ram_result.changed == true
- name: Executing Log2RAM installer
ansible.builtin.command: ./install.sh
args:
chdir: "{{ tools_folder }}/log2ram-{{ log2ram_version }}"
when: log2ram_result.changed == true
- name: Remove installer folder
ansible.builtin.file:
path: "{{ tools_folder }}/log2ram-{{ log2ram_version }}"
state: absent
when: log2ram_result.changed == true
- name: Adding log2ram template
ansible.builtin.template:
src: templates/log2ram.j2
dest: "/etc/log2ram.conf"
owner: "root"
group: "root"
mode: "0640"
El uso de Log2RAM tiene un gran inconveniente. Si ahora nuestro servidor se reinicia, perderemos todos los datos que se encuentran en memoria, teniendo aún menos información para investigar qué ha pasado. Sin embargo, el uso de Grafana Cloud soluciona este problema puesto que podemos enviar nuestros logs en tiempo real.
La integración con Grafana Cloud también es relativamente sencilla, pero antes tendremos que crearnos una cuenta en su página web.
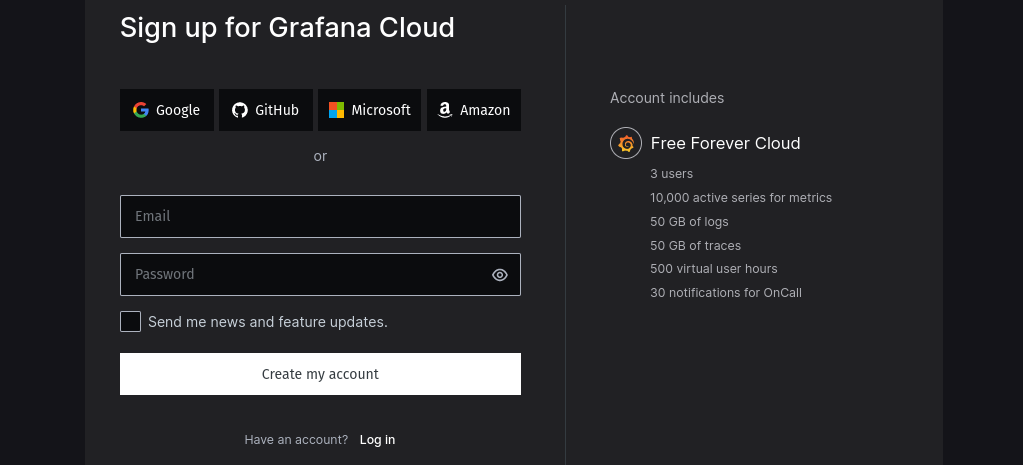
Como podemos ver en la captura de pantalla, su tier gratuito es bastante generoso. La principal limitación que me he encontrado es el número máximo de paneles que podemos tener en Grafana, limitado a tan sólo 10.
De todos los servicios que nos ofrecen, hay tres que son especialmente interesantes:
- Grafana, el servicio para crear paneles con toda la información de nuestros servidores.
- Prometheus, un servicio para almacenar métricas y que también nos permite crear alertas basadas en las anomalías que sufran dichas métricas.
- Loki, un servicio para almacenar logs y poder consultarlos o utilizarlos en nuestros paneles de Grafana.
La idea es sencilla. Vamos a utilizar Grafana Cloud para enviar los logs y métricas que necesitemos a Prometheus y Loki y gracias a ellos, crear los dashboards y las alertas que necesitemos en Grafana.
Al igual que el caso anterior, vamos a configurarlo con Ansible, pero para hacerlo necesitamos previamente activar nuestro entorno y crear una API key:
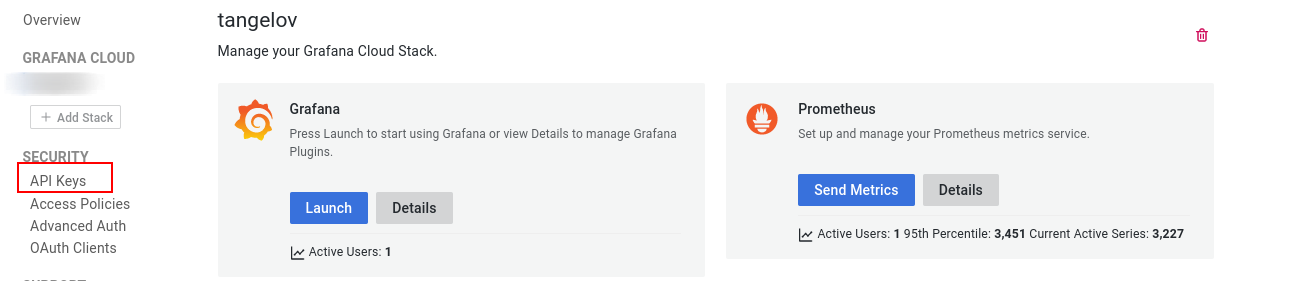
Ahora sólo tendremos que instalar su cliente y conectarlo con nuestra instancia de Grafana Cloud:
- name: Installation and configuration of Grafana client
block:
- name: Install of Grafana Agent
block:
- name: Adding Grafana from official deb repository
ansible.builtin.apt_repository:
repo: 'deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main'
state: present
update_cache: no
filename: "grafana"
- name: Adding Grafana official apt key
ansible.builtin.apt_key:
url: "https://apt.grafana.com/gpg.key"
keyring: "/etc/apt/keyrings/grafana.gpg"
state: present
- name: Ensuring Grafana Agent and dependencies is installed
ansible.builtin.apt:
name:
- grafana-agent
update_cache: true
state: present
- name: Deploy configuration of Grafana client for Grafana Cloud
ansible.builtin.template:
src: templates/grafana.j2
dest: "/etc/grafana-agent.yaml"
owner: "grafana-agent"
group: "root"
mode: "0640"
notify: "Restart grafana-agent"
Si alguien está interesado en consultar la plantilla que estoy utilizando, puede acceder a ella desde aquí.
En la plantilla activo algunas funcionalidades extra del cliente que necesito para mi caso de uso:
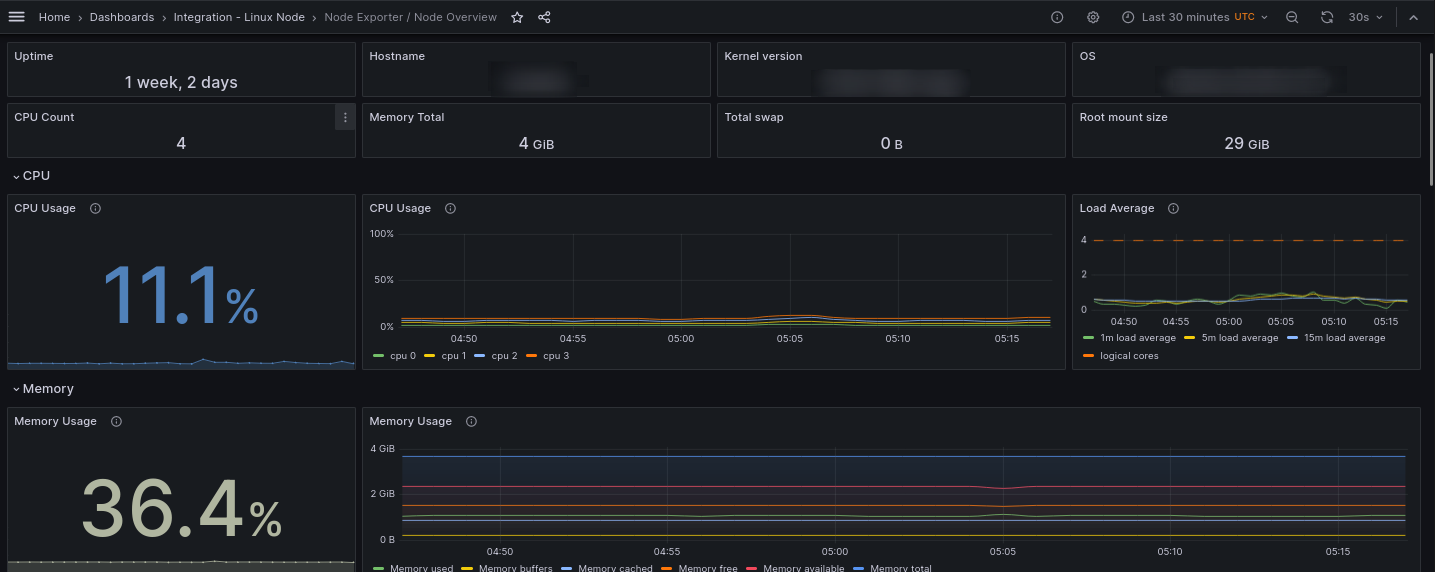
- Prometheus tiene múltiples exporters. Un exporter es un servicio que recopila datos de otro servicio y los expone como métricas para que puedan ser utilizadas por Prometheus. Algunos de ellos están integrados en el cliente de Grafana y yo voy a activar dos: Node Exporter (para obtener métricas básicas acerca del estado de mis servidores) y MySQL Exporter (para obtener métricas sobre el estado de mis bases de datos en MySQL).
- Habilitamos también las escrituras remotas sobre Grafana Cloud utilizando las URLs que el servicio nos ha proporcionado para Prometheus y Loki. También indicamos que logs queremos sean enviados a Grafana Cloud.
Con esto ya podríamos empezar a trabajar y con las primeras métricas ya podemos activar algún dashboard de terceros para jugar un poco:
El futuro de mis servidores
El estado actual del proyecto no afecta todavía a ninguno de los servicios que ya estaba utilizando. Antes de migrar nada, he estado evaluando mis opciones en base a los requisitos que había definido y que son fundamentalmente tres:
- El uso de contenedores requiere el uso de una herramienta para orquestarlos y que me permita integrar los flujos operacionales que ya tengo.
- Necesito un sistema de backups que me aporte una mayor flexibilidad y que no sea costosa de mantener.
- Un sistema que me permita generar plantillas, reutilizar código y automatizaciones en la medida de lo posible
Tras una pequeña investigación, el stack elegido es el siguiente:
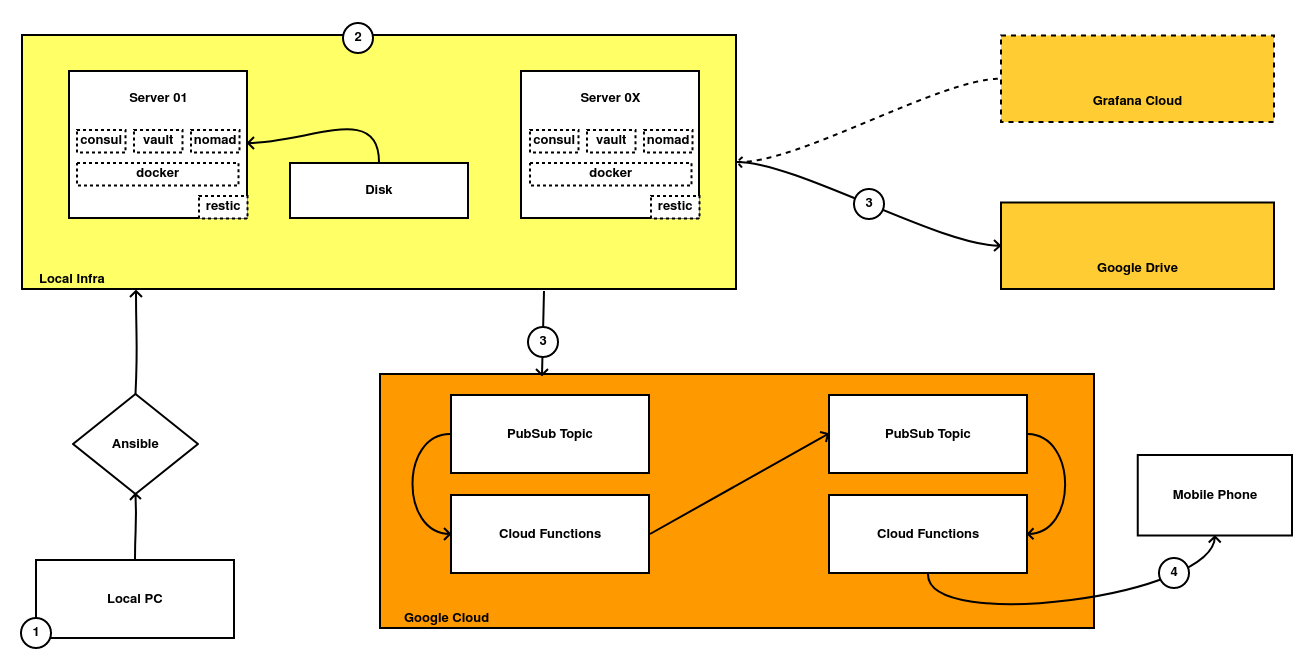
Aunque hablaré más a fondo en siguientes posts, pretendo instalar un Hashistack (porque todas las herramientas son desarrolladas por Hashicorp y se integran entre sí), que me permitirá definir, instalar y mantener las aplicaciones sobre contenedores.
Las piezas del Hashistack son las siguientes:
-
La primera es Consul. Es un servicio que gestiona todo el sistema de redes de nuestras aplicaciones y que posee algunas funcionalidades extra muy potentes como la capacidad de funcionar como un Service Mesh. Yo lo voy a utilizar principalmente como Service Discovery y como sistema de almacenamiento para el resto de piezas del stack, gracias a su potente base de datos de clave-valor.
-
La segunda es Vault. De esta herramienta de gestión de secretos ya escribí un post en el pasado y no voy a añadir mucho más por el momento. Pienso utilizarlo para generar credenciales efímeras que serán utilizadas por las aplicaciones, aportando un extra de seguridad.
-
El último del grupo es Nomad. Es el más desconocido de los tres y es un orquestador de aplicaciones. Nos permite gestionar procesos, aplicaciones empaquetadas en contenedores, ficheros JARs de Java, etc. Hace tiempo que quería aprender a utilizarlo y me parece un buen momento para ver su potencial y sus limitaciones y compararlo con la competencia (principalmente Kubernetes y Docker Swarm), que ya conozco muy bien.
También voy a reemplazar el servicio de backups actual, basado en Backupninja, por uno más moderno basado en Restic. Me permite utilizar distintos backends donde almacenar los backups, así cómo hacerlos incrementales y mucho más. Es un servicio que conozco desde hace mucho, pero por pura pereza no lo había investigado.
Todos estos cambios me van a permitir generar mucho contenido para el blog y espero que sea útil para alguien. Además, he visto poco contenido sobre el tema en castellano.
Y sin más, espero que os haya gustado el post y os veo en próximos capítulos.
Documentación
- Página web oficial de Consul (ENG)
- Página web oficial de Vault (ENG)
- Página web oficial de Nomad (ENG)
- ¿Qué es un Service Mesh? (ENG)
- ¿Qué es el Service Discovery en una arquitectura de microservicios (ENG)
- Página oficial de Restic (ENG)
- Proyecto oficial en Github de Log2RAM (ENG)
- Log2RAM, extending SD Card lifetime (ENG)
Revisado a 05/07/2023