Open Policy Agent - Creando tests para Terraform
2021-06-13 14:00Cada vez que se lanza una aplicación al público, ésta sigue un proceso bastante común: se coge el código fuente, se compila o empaqueta, se configura y, finalmente, se despliega y se testea. Sin embargo, es algo que puede ser muy complejo y las interdependencias entre cada uno de los pasos hacen que se pueda tardar horas o días en finalizar. Por ello, la automatización se ha ido abriendo paso para reducir los tiempos y facilitar la vida de operadores y desarrolladores.
Cualquier automatización debe ser iterativa y acumulativa. Se empieza por las partes más sencillas, como la construcción de la aplicación y poco a poco se van integrando más capas. La acumulación de estas automatizaciones en la construcción y despliegue de las aplicaciones, son la base de cualquier sistema de CI/CD (Continuous Integration / Continuous Deployment) actual.
La infraestructura como código recoge estos mismos principios y, como ya comenté en un post anterior, yo ya utilizo un pipeline básico para desplegar mi infraestructura. Hoy vamos a ver cómo crear estos tests y verificar que los despliegues hacen justamente lo que queremos.
Testing sobre Terraform
A modo de prólogo, recomiendo a cualquier lector leer el artículo antes referenciado para entender con más profundidad cómo funciona mi pipeline de infraestructura. A grandes rasgos hace lo siguiente:
- Se valida el código con
terraform validate. - Se crea un plan de Terraform donde están almacenados todos los cambios.
- Se pasan una serie de tests basados en OPA sobre dicho plan, utilizando conftest.
- Si no hay errores, se aplican los cambios automáticamente tras integrar el código a la rama master.
Existen una gran cantidad de tipos de tests y herramientas que podemos utilizar junto a Terraform:
-
Terratest: esta librería de Go, desarrollada por Terragrunt, permite generar tests que crean infraestructura, ejecutar una serie de tests sobre ella y finalmente destruirla automáticamente. Permite validar el funcionamiento de nuestra infra y ejecutar una serie de tests End to End. Pese a la potencia de la herramienta, mi falta de conocimiento de Go hizo que la descartara, aunque es posible que la incorpore en el futuro.
-
Goss: esta aplicación nos permite realizar tests funcionales contra cualquier infraestructura ya desplegada. Utiliza YAML para crear tests, lo que le aporta una gran legibilidad, pero su enfoque a ejecutar pruebas en máquinas virtuales, hizo que la desechara.
-
Open Policy Agent (OPA): es una herramienta que nos permite realizar validaciones en cualquier tipo de lenguaje estructurado, ya sean YAML, JSON o HCL (como Terraform). Pese a su curva inicial, se integra con una gran cantidad de tecnologías y servicios (como Cloud Formation o Kubernetes) y una gran comunidad.
-
Regula o Checkov: debido a la complejidad de Rego (el lenguaje usado por OPA), han aparecido herramientas que encapsulan tests escritos en dicho lenguaje y simplifican su uso. Regula o Checkov son solo algunos ejemplos.
Aunque existen muchos tipos de tests: unitarios, smoke tests, End to End, de integración… Terraform es declarativo, lo que nos permite ver los cambios antes de aplicarlos. Por ello decidí utilizar OPA y crear tests unitarios y de compliance, que son validados contra el plan de Terraform y que nos aseguran el correcto despliegue de nuestra infraestructura. No descarto a futuro, integrar otro tipo de tests.
Aprendiendo a escribir tests en Rego
Rego es el lenguaje utilizado por OPA para escribir sus validaciones. Empecé a interesarme por él por motivos estrictamente profesionales, pero la decisión de utilizar OPA en lugar de otra herramienta estuvo motivada por su potencial: de esta forma, podía escribir tests para una enorme abanico de herramientas y servicios que además, luego podían ser reaprovechados por otros departamentos.
Rego está basado en Datadog y diseñado para parsear y analizar documentos estructurados como son JSON o YAML. Así podemos utilizar queries para definir políticas que verifiquen si nuestro documento cumple dichas reglas o no.
Para mi caso de uso, decidí implementar cinco políticas que considero que son básicas, para poder validar cualquier despliegue:
- Que no se destruya ningún recurso de forma automática.
- Que todos los recursos que soportan etiquetas estén etiquetados de forma correcta.
- Que todas las variables declaradas en Terraform tengan una descripción para facilitar la comprensión del código.
- Que los buckets de Google Cloud Storage tengan el versionado habilitado y en un caso concreto, que sea público.
Primeros pasos
Este post no pretende ser un curso para aprender Rego desde 0, sino un aporte extra para comprender mejor su funcionamiento y reducir la curva de aprendizaje. No soy un experto y sigo profundizando en su uso.
Si alguien está interesado en aprenderlo desde cero, recomiendo echarle un vistazo a la documentación oficial, puesto que tiene multitud de ejemplos y al curso gratuito que Styra (la empresa principal que desarrolla OPA) ofrece en su Styra Academy.
Comencemos con un poco de teoría, explicando algunos elementos básicos del lenguaje:
- Rego no es un lenguaje tipado y las variables pueden contener cualquier tipo de valor: escalares, floats, cadenas de texto, diccionarios, tuplas, listas, etc.
- Permite hacer referencias a valores anidados o recorrerlos, ya sean diccionarios, listas o tuplas. También soporta list comprehensions como Python.
- Soporta el uso de condicionales del tipo “if/else”, así como comparaciones utilizando los operadores habituales (mayor que, menor que, etc).
- No tiene estructuras de tipo bucle como for o while aunque como hemos dicho, si podemos recorrer valores anidados fácilmente.
- Posee una serie de funciones embebidas que extienden un poco su funcionalidad básica.
- Al igual que otros lenguajes también tiene algunas palabras reservadas como input, some o package.
Rego tiene una pecularidad que no había visto antes. Además de verdadero (true) o falso (false), una comparación puede devolvernos no definido (undefined). Aunque a la hora de escribir reglas, el comportamiento de undefined es similar a false, si intentamos asignar algo con valor undefined a una variable, recibiremos un error similar al siguiente: rego_unsafe_var_error: var mi_variable is unsafe .
Los tres operandos principales que utilizaremos en Rego son:
- := - Es el símbolo que asigna un valor a una variable.
- == - Es el símbolo que compara si dos variables son iguales o no.
- = - Es la suma de los anteriores dos operandos, asigna el valor y lo compara.
Aquí podemos ver algunas ejemplos:
# Por ejemplo en este caso estaríamos generando una variable llamada resource_type que contiene un string
resource_type := "google_storage_bucket"
# Podemos asignar variables a diccionarios, a números, a arrays o tuplas
num_replicas := 5
allowed_regions := ["europe-west1", "europe-west2"]
# Comparamos si la variable resource_type es un bucket de GCP
resource_type == "google_storage_bucket" # Devolvería true
resource_type = ""google_storage_default_object_acl" # Devolvería true también
# Más información aquí: https://www.openpolicyagent.org/docs/latest/policy-reference/#built-in-functions
Una de las bondades de Rego es la facilidad con la que se puede acceder a cualquier estructura de datos anidada. Imaginemos que este JSON es lo que necestiamos validar: contiene un elemento llamado variables, que a su vez tiene otros sub-elementos, que están formados por las claves description o default y tienen diferentes valores:
{
"variables": {
"billing_account_name": {
"description": "Display name of the Billing Account"
},
"billing_dataset_name": {
"description": "Name of the BigQuery dataset created to store the Biling export"
},
"cb_gitlab_project_variable": {
"default": "00000000"
}
}
}
Para acceder a los elementos de un array o un diccionario, tan sólo tendríamos que hacer lo siguiente:
# Asignamos 'todos' al valor de cada uno de los elementos que forman 'variables'.
# Se usa un guión bajo entre corchetes y es lo más parecido a un for que podemos hacer en Rego
todos := input.variables[_]
# Asignamos 'uno' al elemento número 1 de la lista de variables:
uno := input.variables[0]
El siguiente paso es hablar de las estructuras “if/else”. En Rego no existe if, pero else produce una funcionalidad similar puesto que cambia el resultado de una función o una regla dependiendo del input que haya recibido. Se entiende mucho mejor con un ejemplo:
get_desc(var) = desc {
desc := var.description
} else = no_desc {
no_desc := ""
}
Esta función, de nombre get_desc, hace lo siguiente:
- Cualquier input que reciba, puede ser referenciado desde dentro como la variable var.
- Por defecto, la función devolverá el valor de la variable desc.
- El valor de la variable desc se define en el contenido de description, que deberá ser un sub-elemento, dentro de var.
- En el caso de que no exista un subelemento description, la función devolverá la variable no_des, cuyo valor es un string vacío.
Esta estructura sería equivalente a escribir en Python:
if description in var:
return true
else:
return false
Funciones embebidas y funciones personalizadas
Según sus creadores, Rego está diseñado para ser sencillo y extensible. Debido a esto, aunque posea funciones embebidas como otros lenguajes, nos faltan muchas funcionalidades típicas. Por ejemplo, podemos convertir en minúscula o mayúscula el contenido de una string, verificar el firmado de un token, utilizar regex, realizar llamadas HTTP, etc. Podemos ver una lista completa de todas las funciones embebidas aquí.
No obstante, si que faltan algunas funcionalidades básicas de otros lenguajes como el poder detectar si un elemento está dentro de una lista. Para suplir estas carencias, Rego permite también la creación de funciones personalizadas. Por ejemplo, éste sería el código de la función que comprueba si un elemento existe en un array:
array_contains(arr, elem) = true {
arr[_] = elem
}
else = false {
true
}
Su funcionamiento es el siguiente:
- La función recibe dos variables de entrada. Una llamada arr que contiene la lista de elementos y otra llamada elem, que es el elemento a buscar.
- Devolverá true si alguno de los elementos (la recorremos con arr[_]) de la lista es igual al elemento a buscar (se asigna y comprueba con el operador =)
- Devolverá false en caso contrario.
Reglas, módulos y paquetes
Cada política que definimos en Rego, está formada por uno o más módulos (ficheros) que a su vez consiste en:
- Un package.
- Cero o más import declarados.
- Cero o más reglas definidas.
Como ya hemos dicho, Rego también tiene algunas palabras reservadas que se utilizan a nivel interno y que debemos conocer. Las que vamos a utilizar son las siguientes:
- as: se utiliza para definir alias dentro de módulos.
- else: se utiliza para crear estructuras de tipo if/else. Podemos añadir múltiples else consecutivos que son ejecutados por orden hasta que una de las condiciones se cumple.
- import: permite declarar dependencias entre distintos paquetes dentro de OPA.
- package: se utiliza para agrupar las reglas definidos de uno o más módulos en un namespace.
Son conceptos un poco abstractos, así que voy a utilizar a modo de ejemplo este fichero, creado por Scalr y que evalúa que los discos de cualquier instancia en AWS, se borren automáticamente cuando la máquina virtual es eliminada:
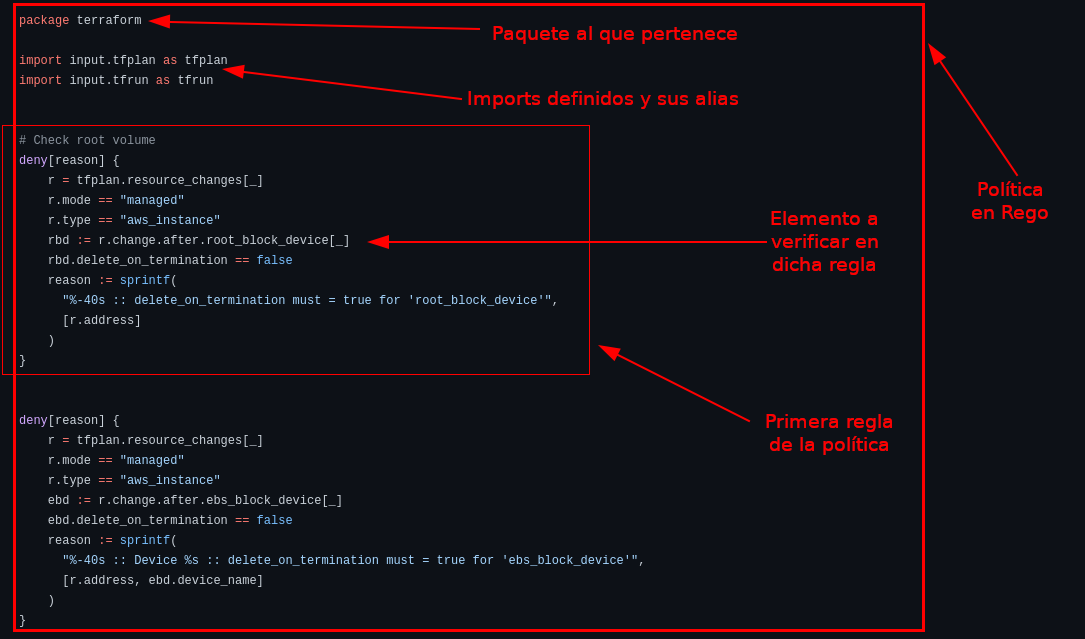
- Cada fichero tiene que tener definido un package que nos permita agrupar de forma lógica, múltiples ficheros en un mismo espacio de nombres. En este caso es terraform.
- Se importan dos orígenes de datos y se les añaden diferentes alias. Esto nos permite referirnos a ellos en otras partes del código utilizando los alias.
- Esta política en concreto tiene dos reglas definidas. Vamos a explicar más a fondo la primera de ellas:
-
Es una regla de tipo deny. Este tipo devolverá un mensaje de error en caso de que la regla se cumpla. Existen otros tipos como warn (que devolverá un mensaje de warning) y violation (parecido a deny, pero orientado a trabajar con OPA Gatekeeper).
-
Cada regla está formada por múltiples comprobaciones y variables. En este caso, r es cada uno de los recursos que son gestionados por Terraform, comprobándose que modo utiliza, que tipo de recurso es, que tipo de discos usa y si tienen deshabilitado el delete_on_termination. Dentro de una misma regla, todas las comprobaciones deben cumplirse (debe ser de mode “managed” AND del tipo “aws_instance”, etc.) y mostrar el error.
Si queremos verificar dos condiciones diferentes, como si fuese un “condición 1 OR condicion 2”, debemos crear dos reglas diferentes aunque eso suponga duplicar código. Es una de las limitaciones de Rego.
-
Cada regla devolverá un error por pantalla, el cual es en este caso está definido por la variable reason.
-
Creando nuestras propias políticas
Una vez ya conocemos por encima el funcionamiento de Rego, podemos empezar a escribir nuestras propias políticas. Una de las funcionalidades de Terraform es convertir el output de terraform plan en un fichero JSON sobre el cual podemos aplicar diferentes políticas de OPA.
La estructura del fichero JSON resultante puede ser consultada aquí y tiene algunas partes muy interesantes:
- Posee una lista de todos los elementos controlados por Terraform y si van a ser actualizados, creados o borrados en dicho plan.
- Registra los valores y estructura de las variables y outputs definidos en Terraform.
- Registra los módulos y providers utilizados en Terraform, así cómo su versión.
En mi caso, he generado en el repositorio de infraestructura una carpeta llamada policy con la siguiente esquema:
policy
├── functions.rego
└── main.rego
Hay dos ficheros, uno donde se almacenan todas las funciones (porque son comunes a todas las políticas) y otro, llamado main, donde se encuentran dichas políticas. A futuro cuando amplie el número de proveedores, crearé ficheros por proveedor y los agruparé en paquetes de una forma más óptima.
La primera regla que vamos a crear es la que verifica que no se destruya ningún recurso de forma automática. Así nos aseguramos que no se pierden datos, evitando un posible error catastrófico.
Los valores que nos interesan se encuentran dentro del plan en resource_changes, dentro de cada recurso en la sección de change.actions. Aquí tenemos como ejemplo como se ve un objeto dentro un bucket que es recreado por Terraform:
{
"address": "google_storage_bucket_object.gcp_function_checking_backups_code",
"mode": "managed",
"type": "google_storage_bucket_object",
"name": "gcp_function_checking_backups_code",
"provider_name": "registry.terraform.io/hashicorp/google",
"change": {
"actions": [
"delete",
"create"
],
"before": {
"lista_de_valores": "que el recurso tiene antes de ejecutar el plan"
},
"after": {
"lista_de_valores": "que el recurso tendrá tras ejecutar el plan"
},
"after_unknown": {
"valor_no_conocido": "hasta que se ejecute el plan"
}
}
}
Para validar que un recurso no es destruido o recreado, debemos buscar en la lista de change.actions que no existe ningún elemento cuyo valor sea delete.
El código de dicha política sería así:
deny[msg] {
# Asignando los cambios a evitar en Terraform
avoid := "delete"
# Asignamos cada recurso y sus cambios a la variable item
item = input.resource_changes[_]
# Iteramos sobre una los distintos cambios aplicados en cada recurso y verificamos si alguno es delete
# Nos saltamos cualquier tipo de objeto que sea un objeto dentro de un bucket puesto
# que actualmente todos los datos que tengo almacenados en ellos salvo las imágenes
# (que no están terraformadas), son efimeros y tiene sentido que se vayan recreando periódicamente.
some i
item.type != "google_storage_bucket_object"
item.change.actions[i] == avoid
msg = sprintf(
"El recurso '%v' de tipo '%v' va a ser destruido o reemplazado. Abortando",
[item.name, item.type]
)
}
La siguiente política que vamos a escribir verifica que todos los recursos que soporten etiquetas estén bien etiquetados. Lo primero es definir que etiquetas queremos que sean obligatorias y crear las funciones que nos permitan validar su existencia:
## Definimos las variables obligatorias en nuestros recursos
required_tags = ["environment", "management-tool", "app"]
## Función get_basename comprueba si un elemento es de un determinado proveedor o no
get_basename(path) = basename{
arr := split(path, "/")
basename:= arr[count(arr)-1]
}
## Función get_tags obtiene todos los tags/labels en función del proveedor. En Google
## son llamados labels y por eso se realiza un filtrado previo por proveedor. Si no tiene
## tags, devuelve una lista vacía como podemos ver en sus condicionales.
get_tags(resource) = labels {
provider_name := get_basename(resource.provider_name)
"google" == provider_name
labels := resource.change.after.labels
} else = tags {
tags := resource.change.after.tags
}
En este caso, hemos creado dos funciones y una variable:
- Hemos decidido que los tags obligatorios van a ser environment, management-tool y app.
- La función get_basename es utilizada para saber cual es el proveedor del recurso que estamos gestionando con Terraform.
- Si el proveedor es Google, se utiliza la variable labels y si es cualquier otro (como AWS), utilizamos la variable tags.
Si en el futuro utilizamos otro proveedor que utilice otra key para almacenar sus etiquetas, podemos seguir mejorar la función simplemente añadiendo otro else a la misma.
Tras crear las funciones necesarias, ya podemos escribir la nueva regla:
deny[msg] {
# Asignamos los cambios a la variable item
item := input.resource_changes[_]
# Comprobamos que se está aplicando algún cambio al recurso y si existe lo asignamos a la variable
# action
action := item.change.actions[count(item.change.actions) - 1]
# Vemos si alguno de los cambios aplicados son create o update con la función array_contains
functions.array_contains(["create", "update"], action)
# Utilizamos la funcion get_tags para ver que labels/tags tiene cada recurso
tags := functions.get_tags(item)
# Generamos un array con las tags que contiene el recurso y otro con los que consideramos requisito
existing_tags := [ key | tags[key] ]
required_tag := functions.required_tags[_]
# Si el objeto no tiene o va a perder dichos tags, devolvemos un error
not functions.array_contains(existing_tags, required_tag)
msg := sprintf(
"El recurso '%v de tipo '%v' no tiene asignada la siguiente tag/label %q. Abortando",
[item.name, item.address, required_tag]
)
}
Por último, vamos a explicar cómo generar la regla que verifica si el versionado de los buckets de Cloud Storage está activo o no. Al igual que en los otros casos, primero creamos una función que valide que el versionado esté configurado y habilitado:
get_versioning(resource) = versioning {
versioning := resource.change.after.versioning[_].enabled
versioning == true
} else = no_versioning {
no_versioning := false
}
Y después escribimos la regla. Creo que con los comentarios de la misma se entenderá bien:
deny[msg] {
# Asignamos los cambios a la variable item
item := input.resource_changes[_]
# Comprobamos que el item es del tipo google_storage_bucket
item.type == "google_storage_bucket"
# Comprobamos que se está aplicando algún cambio al recurso y si existe lo asignamos a la variable
# action
action := item.change.actions[count(item.change.actions) - 1]
# Vemos si alguno de los cambios aplicados son create o update con la función array_contains
functions.array_contains(["create", "update"], action)
# Comprobamos que tiene el versionado con el valor true
versioning = functions.get_versioning(item)
versioning != true
msg := sprintf(
"El recurso '%v' de tipo '%v' no tiene habilitado el versionado. Abortando",
[item.address, item.type]
)
}
Y… esto es todo. Espero que este post sirve de ayuda a gente que quiera iniciarse con Open Policy Agent y que le permita salvar esa barrera de entrada que es Rego. Espero que el post os haya gustado y nos vemos en futuras entregas.
Un abrazo y Happy Terraform!
Documentación
-
Five tips for using the Rego language for Open Policy Agent (ENG)
-
Ejemplos desarrollados por Scalr de políticas creadas para Terraform (ENG)
-
Ejemplos de testing en Terraform para usar con Conftest (ENG)
Revisado a 01-05-2023