Terraform (I): introducción a la infraestructura como código
2019-01-30 10:00Ya he comentado en alguna ocasión mi amor por Hashicorp por las facilidades que nos ofrecen a los que trabajamos en entornos Cloud. Hoy vamos a hablar de su herramienta de aprovisionamiento de infraestructura, Terraform.

Introducción
Terraform nos permite gestionar la infraestructura de nuestros proyectos como código. Así podemos predecir los resultados de un cambio antes de aplicarla o versionarla gracias a una herramienta de control de versiones. Casi todos los proveedores Cloud tienen su propio lenguaje para ello, con el inconveniente de tener que aprender un lenguaje por proveedor.
Terraform ofrece una sintaxis común a todos los proveedores y una metodología declarativa: definimos la infraestructura y después la aplicamos en nuestro proveedor (Cloud o On-Premise). Así podemos predecir los resultados de nuestros cambios antes de aplicarlos, evitando problemas y sucesos no deseados.
Para instalarlo, tan sólo tendremos que descargarlo de su página oficial, hacerlo ejecutable y meterlo en nuestro PATH. Tengo un pequeño script que nos realiza todo el proceso, si queremos.
Uso de Terraform
Tras instalar Terraform, ahora debemos configurarlo. Terraform se conecta a las APIs públicas de los proveedores y transforma el código en órdenes que generarán la infraestructura deseada.
Configurando el proveedor
Primero elegimos uno de los casi 100 provedores diferentes que soporta Terraform (desde proveedores de DNS o sistemas de monitorización hasta un proveedor de Cloud completo).
En este post, vamos a configurar Terraform contra AWS. Los requisitos según la documentación son una región y unas credenciales configuradas. Ya hemos tratado anteriormente como obtener esos datos.
Ahora generamos el fichero provider.tf y ejecutamos terraform init:
provider "aws" {
region = "eu-west-1"
access_key = "MIACCESSKEYMOLONA"
secret_key = "MISECRETKEYMOLONA"
}
Si nuestra configuración es correcta, Terraform descargará sus dependencias y nos indicará un mensaje en color verde:
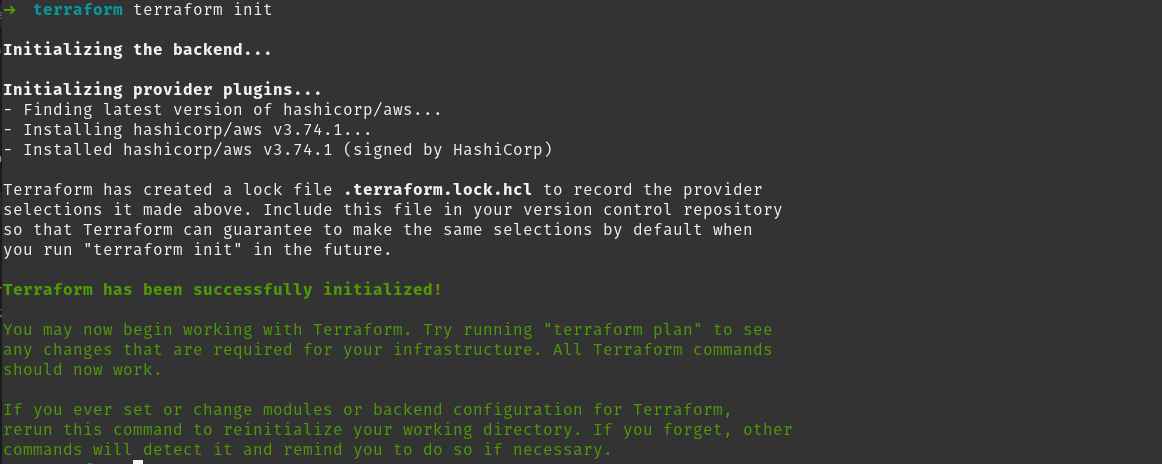
Planificar, desplegar y destruir
Con esto, ya podemos empezar a desplegar infraestructura. En este ejemplo, vamos a desplegar simplemente una máquina virtual basada en Amazon Linux con un tamaño concreto y un par de claves para acceder a ella, creadas previamente. Creamos el fichero main.tf con este contenido:
resource "aws_instance" "ec2_example" {
ami = "ami-0bf84c42e04519c85"
instance_type = "t2.micro"
key_name = "tangelov"
tags = {
Name = "HelloTangelov"
}
}
Si ahora ejecutamos terraform plan este nos indicará los cambios que vamos a tener:
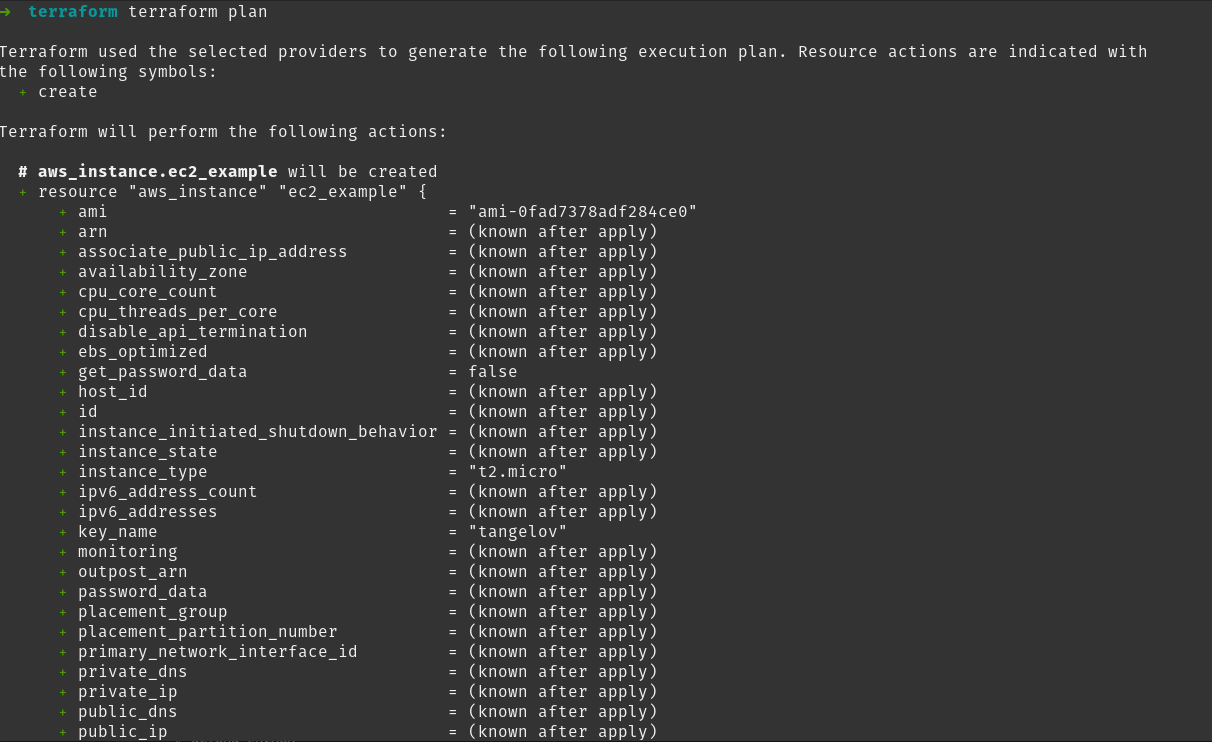
Y si ejecutamos terraform apply y escribimos yes, los cambios se aplicarán en nuestra plataforma.
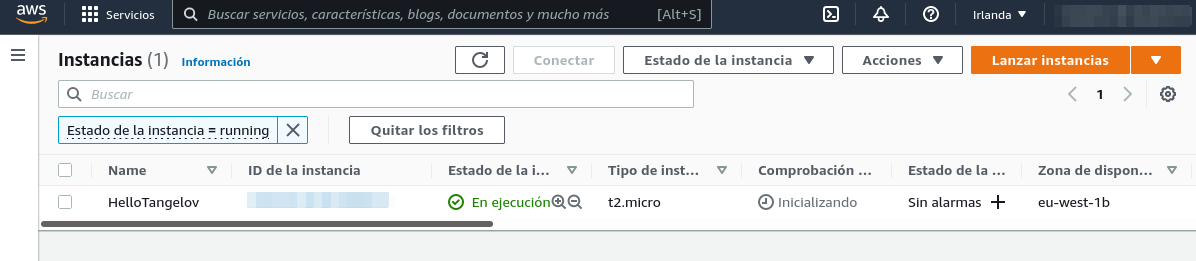
Como podemos ver en nuestra consola de AWS, nuestra máquina se encuentra disponible
Si deseamos destruir lo que ya hemos creado, tan sólo tenemos que ejecutar terraform destroy. Como podemos ver, este proceso es fácilmente repetible y nos puede servir para crear entornos según las necesidades que tengamos.
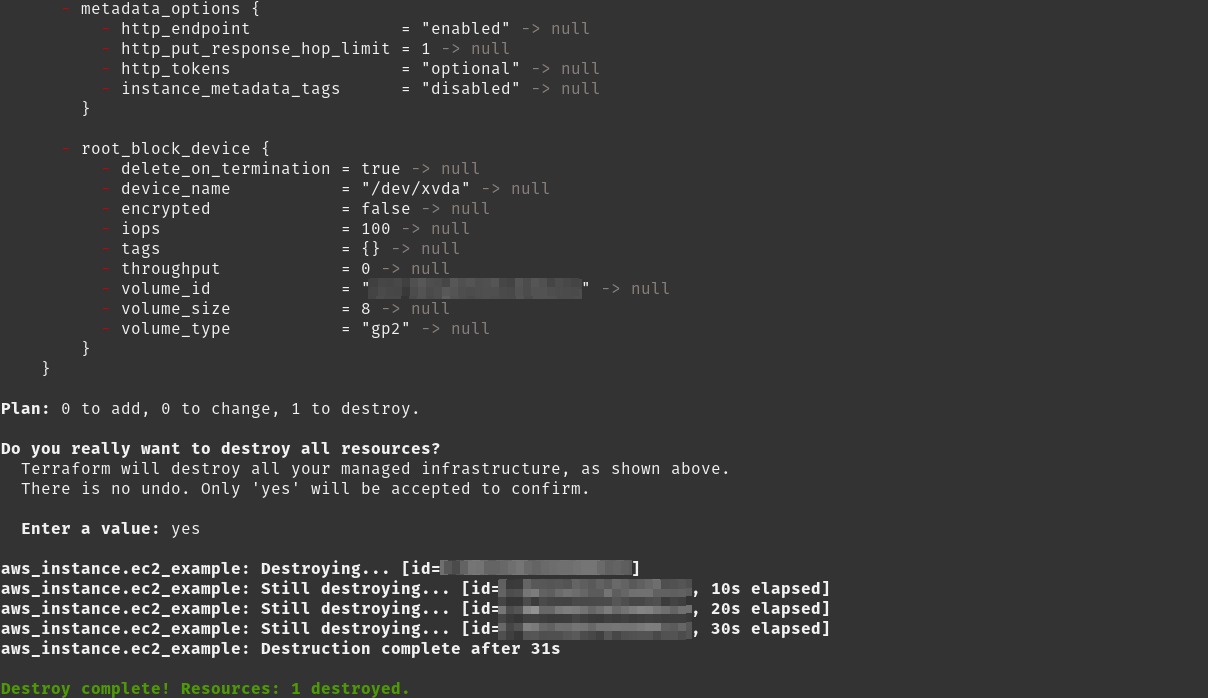
Terraformando tangelov.me
Aunque ya llevo utilizando Terraform bastante tiempo en mi ámbito laboral, no había terminado de decidir si utilizarlo para definir la infraestructura de esta web debido a que es tremendamente simple.
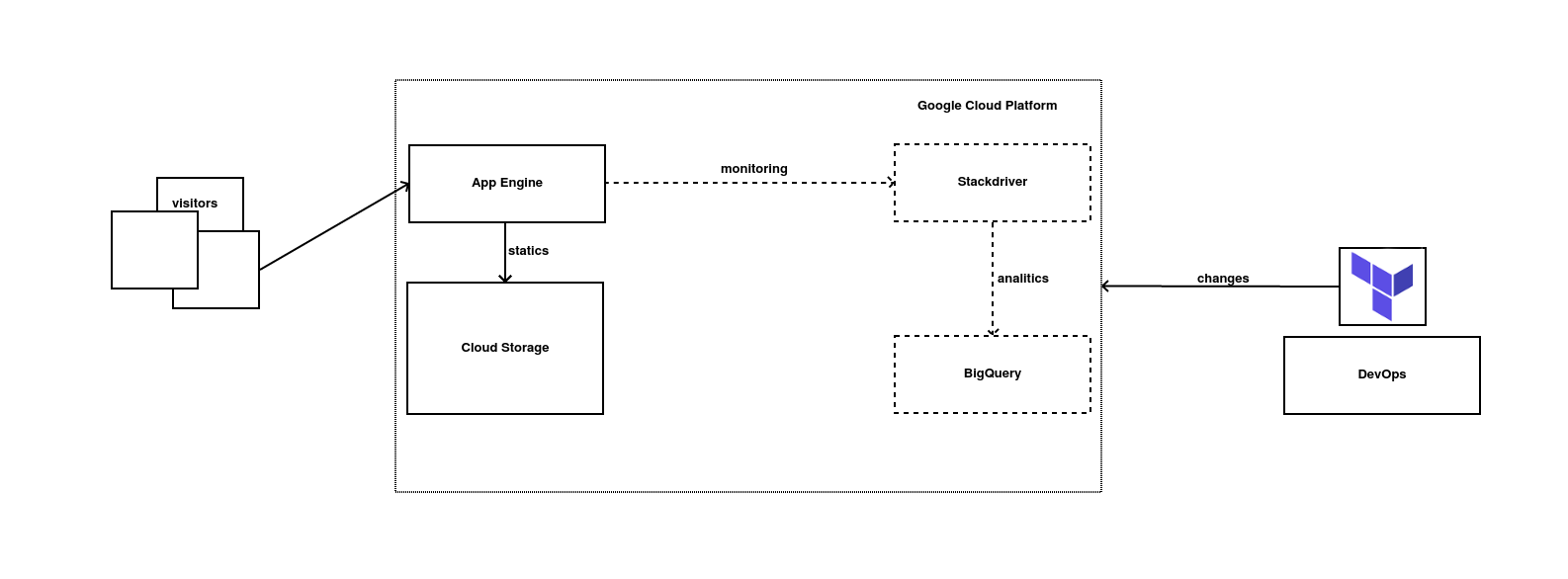
Sin embargo, últimamente estuve investigando cómo podía añadir algún tipo de analítica simple, sin poder ello tener que meter Google Analytics u algún servicio de tracking extra y decidí que para lo que yo quería podía utilizar simplemente las métricas de Stackdriver, el servicio de monitorización de Google Cloud Platform.
A la web, formada por un App Engine y un bucket de Cloud Storage para los estáticos, les he añadido lo siguiente:
-
Primero he generado una cuenta de servicio para Terraform y he generado un nuevo bucket para almacenar el estado de la infraestructura en remoto (en próximos posts, explicaremos esto mejor).
-
En segundo lugar, he importado todos los elementos que ya había anteriormente: App Engine y el bucket de estáticos.
-
En tercer lugar, he creado un export de los logs de request hacia BigQuery y he definido el dataset donde éstos se van a almacenar en BigQuery. Así podré ver el número de visitas o cuales son los posts que generan mayor interés (SPOILER: el que ayuda a preparar la certificación de Google Cloud Platform es el más visitado de lejos).
-
Por último, he añadido los permisos necesarios para que todo el conjunto funcione correctamente.
La infraestructura a groso modo sería ahora mismo así (en líneas discontinuas se encuentra todo lo nuevo):
Si alguno desea implementar un sistema igual, todo ello está codificado y puede ser consultado aquí.
Nota del autor: Este post fue escrito utilizando Terraform 0.11 y actualmente la herramienta ha seguido evolucionando por lo que puede haber algunos cambios en la sintaxis del código almacenado en el repositorio.
Documentación
Revisado a 01/05/2023