Cloud Run: orquestando contenedores sin Kubernetes
2022-10-25 05:00Kubernetes es el orquestador de contenedores más utilizado del mundo. Gracias a su rápido ciclo de desarrollo, no ha parado de incorporar nuevas funcionalidades, que han cubierto nuevos casos de uso y le han permitido alcanzar un crecimiento casi exponencial.
Este ciclo de desarrollo también tiene sus problemas. Cada vez es más difícil y complejo mantener un cluster de Kubernetes y esto ha hecho que aparezcan orquestadores alternativos para cubrir los casos de uso más habituales.
Tenemos múltiples opciones. Si queremos ejecutar contenedores en nuestros servidores, podemos optar por Docker Swarm (de Docker Inc.), o Nomad (de Hashicorp.) Si somos usuarios de algún proveedor de nube pública, tenemos otras opciones nativas. El primer orquestador en aparecer de este tipo fue Google App Engine Flexible, pero lo que se considera “estándar” para este tipo de servicios fue definido por Amazon en AWS Fargate.
Todos estos orquestadores de nube pública tienen algo en común. Buscan ofrecer una plataforma que permita al desarrollador centrarse lo máximo posible en desarrollar su aplicación y reducir al máximo los costes operacionales y el mantenimiento de la infraestructura. Son servicios privativos, muy integrados con otros servicios de la plataforma.
Si en AWS tenemos Fargate y en Microsoft Azure tenemos Azure Container Apps, la solución de Google Cloud es Cloud Run. En este post vamos a ver las características de Cloud Run y cómo adaptar una aplicación para que ésta pueda ejecutarse en dicha plataforma.
Cloud Run
Cloud Run es el principal orquestador de contenedores no-basado en Kubernetes de Google Cloud. Desarrollado sobre Knative, tan sólo necesita una imagen, unos parámetros de configuración y él se encargará de mantener nuestra aplicación en ejecución.
Estas son sus características principales:
-
Servicio totalmente gestionado con redundancia regional y autoescalado, sin tener que ocuparnos de ningún tipo de infraestructura.
-
Pago por uso. Por defecto, sólo se nos cobra cuando nuestro código está en ejecución.
-
Soporte nativo para Node.js, Go, Java, Kotlin, Scala, Python, .NET, aunque podemos usar cualquier otro lenguaje a través de contenedores.
-
Soporte para los protocolos HTTP/1.*, HTTP/2, WebSockets y gRPC.
-
CI/CD nativo gracias al uso de Cloud Build (con soporte a GitHub, BitBucket y Cloud Source Repositories).
-
Integración nativa con algunos servicios de GCP como Secret Manager, Cloud Logging, Cloud Monitoring, o a través de Serverless Connectors (Cloud SQL, Cloud Memorystore, Cloud Filestore, etc.).
Al basarse en Knative, comparte características con éste, lo que lo hace ideal para ejecutar aplicaciones serverless y/o que respondan ante eventos (Event Driven Applications).
En resumen, la aplicación perfecta para desplegar en Cloud run no debe tener estado y debe responder ante eventos, ya sean peticiones HTTP o mensajes en una cola de mensajería.
Diferencias con la competencia
Cloud Run es comparado a menudo con otros servicios similares como AWS Fargate o Azure Container Apps, pero tiene algunas diferencias (y similitudes con estos servicios) que debemos conocer antes de empezar a utilizarlo.
Para empezar, Cloud Run puede ejecutarse en dos generaciones distintas de runtime con diferencias importantes entre sí.
La primera generación cuenta con bastantes limitaciones. No proporciona compatibilidad total en llamadas al sistema operativo, ni permite usar sistemas de ficheros en red como NFS, SMB, etc. Todo ello puede hacer que nuestra aplicación no funcione correctamente.
La segunda generación solventa todos estos problemas y ofrece un mayor rendimiento a cambio de requerir algo más de memoria. Podemos ver todas las diferencias aquí.
Otro punto distintivo es relativo al coste. Cloud Run tiene un tier gratuito muy generoso que se puede “auto-apagar” cuando no se está usando para reducir el coste total. Sólo se nos cobra por los recursos en ejecución cuando la aplicación está respondiendo peticiones. Aunque Azure Container Apps sigue el mismo modelo, AWS Fargate nos obliga a tener siempre una copia en ejecución.
Por último, Cloud Run (y su competencia) no tiene persistencia. Cualquier fichero escrito en el contenedor se perderá si éste se reinicia. La diferencia entre la solución de Google y los demás es que Cloud Run utiliza la memoria RAM como sistema de almacenamiento y si escribimos mucho en disco, podemos quedarnos sin memoria.
Desplegando Atlantis sobre Cloud Run
Tras haber revisado la documentación, ya podemos probar el servicio. En este post, y enlazando directamente con el anterior, vamos a ver cómo desplegar Atlantis sobre Cloud Run.
El equipo de desarrollo proporciona guías para desplegar la aplicación en distintos sabores de Kubernetes, así como Docker o Fargate, por lo que deberíamos poder adaptarlo a Cloud Run con algunos pequeños ajustes en su arquitectura.
Requisitos
Antes de comenzar despliegue alguno, debemos realizar una toma de requisitos previa. ¿Cómo funciona Atlantis? ¿Qué problemas nos podemos encontrar?
Su modo de funcionamiento es el siguiente:
- Al recibir un evento, clona el código del repositorio y lo almacena en local.
- Después ejecuta una serie de acciones definidas por nosotros: descarga los binarios y proveedores necesarios para ejecutar Terraform y generará un plan. Mientras dicho plan no sea aplicado o descartado, se genera un bloqueo temporal.
- Por último, se aplica el plan almacenado en local si se cumplen los requisitos definidos en el workflow.
Esto hace que Atlantis necesite un lugar persistente donde almacenar sus datos puesto que guarda en local los repositorios clonados y numerosos ficheros relacionados con Terraform (proveedores, módulos y planes). También guarda en una base de datos dentro de un fichero los bloqueos que identifican a cada plan.
Esto choca de forma directa con las características de Cloud Run por lo que debemos modificar un poco la arquitectura para su correcto funcionamiento. Tenemos tres opciones:
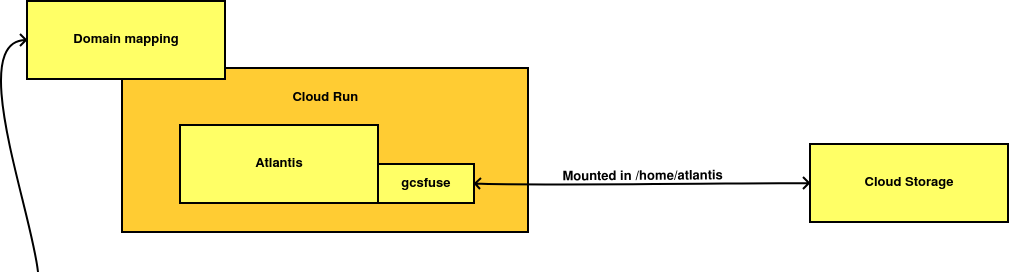
- La primera opción implica montar un bucket de Google Cloud Storage como si fuera un disco a través del uso de gcsfuse y almacenar ahí los datos persistentes de la aplicación.
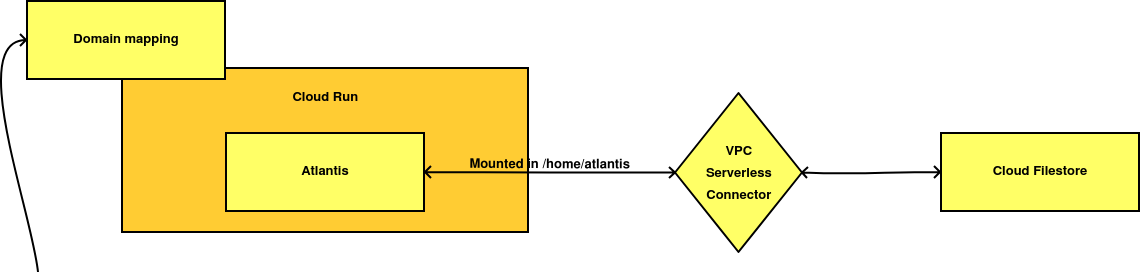
- La segunda opción bebe directamente del módulo de Terraform para desplegar Atlantis sobre Fargate. De esta forma, guardamos los datos en algún sistema de ficheros en red como Cloud Filestore o los Cloud Volumes de NetApp.
- La última opción sería no adaptar nada y asumir las consecuencias de dicha acción. Cuando la aplicación se caiga o sea re-desplegada, deberemos volver a ejecutar los planes que no se hayan aplicado.
Cada escenario tiene distintas ventajas e inconvenientes, por lo que antes de tomar una decisión, realicé diferentes pruebas de concepto.
La prueba basada en Cloud Storage no funcionó. Aunque era un poco lento, su principal problema fue la falta de compatibilidad plena de gcsfuse con POSIX. Repositorios que fallaban al clonarse, problemas en la ejecución de los binarios almacenados en el bucket, etc.
La segunda prueba funcionó a la perfección, aunque era un poco más compleja al tener que configurar un VPC Serverless Connector para acceder a los ficheros. Sin embargo, la tabla de precios de Cloud Firestore, que impide reservar menos de 1 TB de datos, la convertían en una solución inviable al añadir 200 dólares extra a su coste total.
Al final, la tercera solución fue elegida por coste y complejidad. Implica asumir la pérdida temporal de algún plan, pero no es algo que vaya a impactar mucho en mis workflows.
Otra solución que no he probado es el uso de un bucket de Cloud Storage como almacenamiento intermedio. El estado es descargado de un bucket durante el arranque y actualizado al parar o reemplazar la instancia.
Código en Terraform
Previo a comenzar cualquier despliegue, no debemos olvidar la configuración de nuestro usuario robot en Gitlab, tal y cómo vimos en el post anterior.
Con los deberes hechos, procedemos a desplegar nuestros recursos y dependencias utilizando Terraform y Gitlab CI.
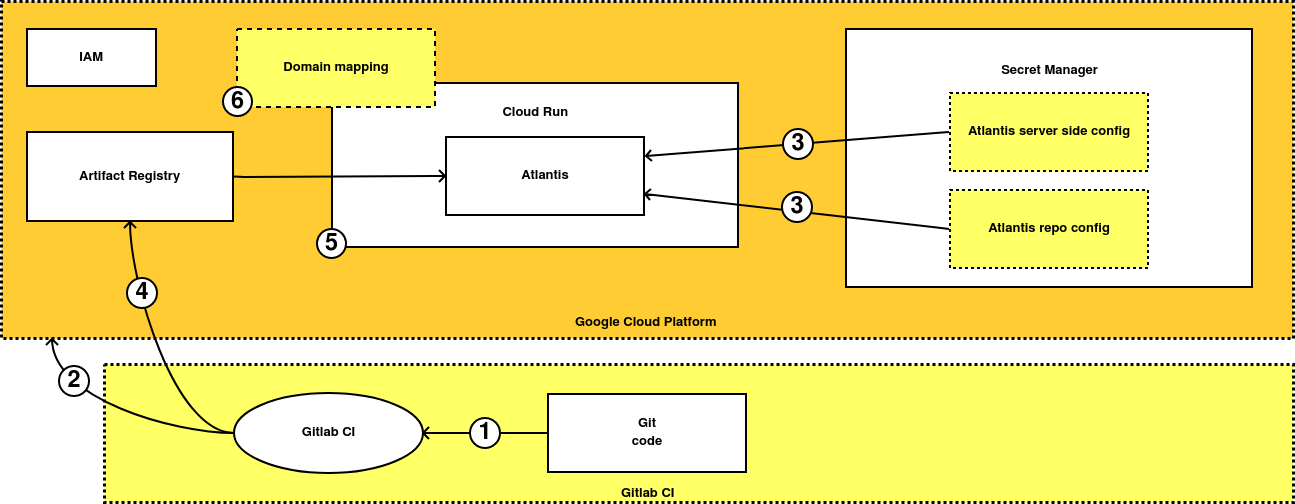
-
Todo el código del proyecto se almacena en Gitlab. Cualquier modificación lanza un pipeline de CI/CD que puede o generar una nueva imagen de Atlantis y/o aplicar el código de Terraform en Google Cloud.
Si queremos que se genere una nueva imagen, deberemos modificar alguno de los ficheros dentro de la carpeta docker y mergear el código a la rama main.
-
El siguiente paso es desplegar la infraestructura para que el servicio pueda funcionar. Necesitamos:
-
Un repositorio de Artifact Registry donde almacenar nuestras imágenes Docker. Cloud Run no permite usar imágenes de DockerHub o Github así que vamos a crear nuestra propia imagen, que además pienso personalizar en el futuro.
-
Dos secretos en Secret Manager: uno para la configuración del servicio y otro para la de los repositorios gestionados por Atlantis.
-
Una cuenta de servicio de IAM con múltiples permisos que le permitan acceder al contenido de los secretos.
-
Un servicio en Cloud Run.
Si intentamos desplegar todo de golpe, el servicio de Cloud Run dará un error al no existir ni una configuración válida para Atlantis ni una imagen dentro del repositorio de Artifact Registry.
-
-
El siguiente paso es manual. Ahora creamos una versión nueva dentro de cada secreto con la configuración de nuestro servicio y de los repositorios. Para cualquier duda al respecto, recomiendo revisar el post previo a éste.
La configuración del Atlantis no está directamente integrada en Terraform (de momento) porque quiero pensar mejor cual es la mejor forma de hacerlo.
-
El cuarto paso es generar una imagen de Atlantis, ya sea con el pipeline o a mano.
-
Si ejecutamos nuestro pipeline otra vez, Cloud Run ya se desplegará sin errores.
-
Por último podemos crear un dominio personalizado para Atlantis, pero dependiendo de cómo dicho dominio esté gestionado en GCP, sera posible automatizarlo o no. Por ello este paso es totalmente opcional y manual.
Llegados a este punto nuestra aplicación es funcional, sin necesitar llaves de cuentas de servicio puesto que todos los permisos son gestionados de forma nativa. El código completo de la solución está disponible aquí.
Limitaciones
Este reto me ha encantado. Ha sido un proceso con bastante ensayo y error al no conocer Cloud Run profundamente, pero me ha servido para descubrir sus limitaciones frente a una aplicación real y la letra pequeña del mismo.
Antes de nada me gustaría comentar que sé que estaba intentando desplegar una aplicación con estado en un servicio no diseñado para ello, pero esperaba poder salvar dicho obstáculo gracias a la combinación de otros servicios. De esto va la arquitectura en nube pública.
El primer golpe fue el espacio mínimo a reservar en Cloud Filestore: 1 TB de datos. En el módulo oficial para AWS Fargate, el estado de Atlantis es almacenado en un pequeño disco dentro de EFS, que añade un coste marginal al proyecto.
En Google, la cosa es distinta. El tamaño mínimo obligatorio es tan grande que lo descarta como opción para muchos proyectos. Quizás es algún tipo de política interna que desconozco, porque he estado revisando todos los servicios del marketplace (NetApp, Elastifile, etc) referentes a sistemas de ficheros en red y comparten este problema.
La segunda limitación ha sido el modo de facturación de Cloud Run. Aunque por defecto se nos facture según la CPU y Memoria RAM utilizada al responder peticiones, este modo no funciona bien con aplicaciones que ejecuten procesos en segundo plano. Al definir el modelo de facturación alternativo, no por peticiones, nuestro coste total crece bastante y además se nos obliga a utilizar instancias mayores a 512 MB de RAM.
# Este es el error que recibiremos si utilizamos el modelo por defecto de Cloud Run
Initializing the backend...
╷
│ Error: Failed to get existing workspaces: querying Cloud Storage failed: Get "https://storage.googleapis.com/storage/v1/b/bucket-secreto/o?alt=json&delimiter=%2F&pageToken=&prefix=dummy%2F&prettyPrint=false&projection=full&versions=false": impersonate: unable to generate access token: Post "https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/sa-account@fake-project.iam.gserviceaccount.com:generateAccessToken": net/http: TLS handshake timeout
│
La última piedra en el camino ha sido la integración del sistema de secretos, Cloud Run y Atlantis. Al arrancar, Atlantis comprueba que la extensión de configuración del servicio termine en .yaml.
Sin embargo, Secret Manager no permite el uso de puntos en los nombres de los secretos y Cloud Run no nos deja personalizar el nombre de los ficheros con el que éstos se montan dentro del servicio.
Para solucionarlo, he necesitado añadir un paso extra en el script de arranque del contenedor, que copia el contenido del secreto y genera el fichero en el formato esperado.
Por último, me gustaría añadir una pequeña tabla con el coste aproximado de ejecutar Atlantis al mes en cada uno de los servicios totalmente gestionados dentro de Google Cloud:
| Servicio | Coste | Observaciones |
|---|---|---|
| Cloud Run | 44 $ | El estado se pierde al reiniciar o reemplazar la instancia |
| Cloud Run + Filestore | 260 $ | El servicio requiere configurar un VPC Serverless Connector |
| Autopilot | 73 $ | El coste del clúster puede ser compartido entre múltiples servicios |
Y nada, con esto terminamos. Espero que os haya gustado y ¡nos vemos en el siguiente post!
Documentación
Revisado a 01-05-2023